 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Robustness to L-infinity and Spatial Perturbations and their Composition
Oct 05, 2022
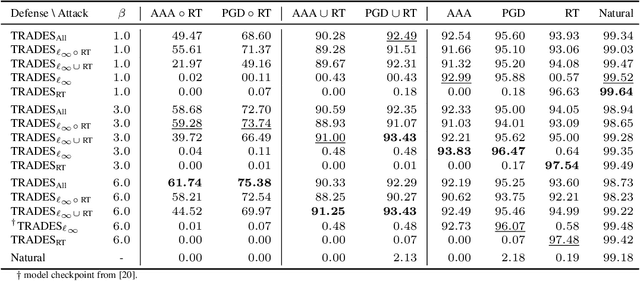
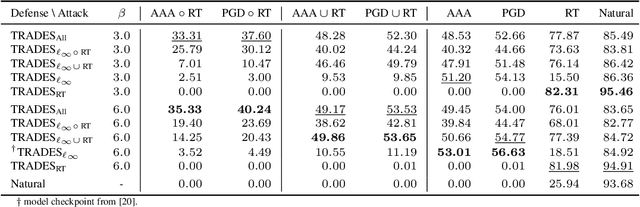
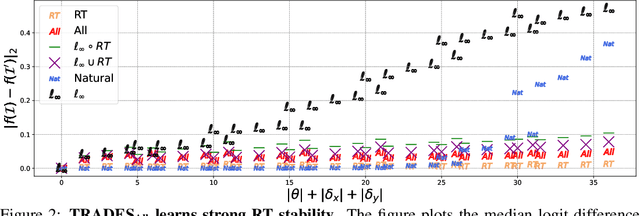
In adversarial machine learning, the popular $\ell_\infty$ threat model has been the focus of much previous work. While this mathematical definition of imperceptibility successfully captures an infinite set of additive image transformations that a model should be robust to, this is only a subset of all transformations which leave the semantic label of an image unchanged. Indeed, previous work also considered robustness to spatial attacks as well as other semantic transformations; however, designing defense methods against the composition of spatial and $\ell_{\infty}$ perturbations remains relatively underexplored. In the following, we improve the understanding of this seldom investigated compositional setting. We prove theoretically that no linear classifier can achieve more than trivial accuracy against a composite adversary in a simple statistical setting, illustrating its difficulty. We then investigate how state-of-the-art $\ell_{\infty}$ defenses can be adapted to this novel threat model and study their performance against compositional attacks. We find that our newly proposed TRADES$_{\text{All}}$ strategy performs the strongest of all. Analyzing its logit's Lipschitz constant for RT transformations of different sizes, we find that TRADES$_{\text{All}}$ remains stable over a wide range of RT transformations with and without $\ell_\infty$ perturbations.
RetrievalGuard: Provably Robust 1-Nearest Neighbor Image Retrieval
Jun 17, 2022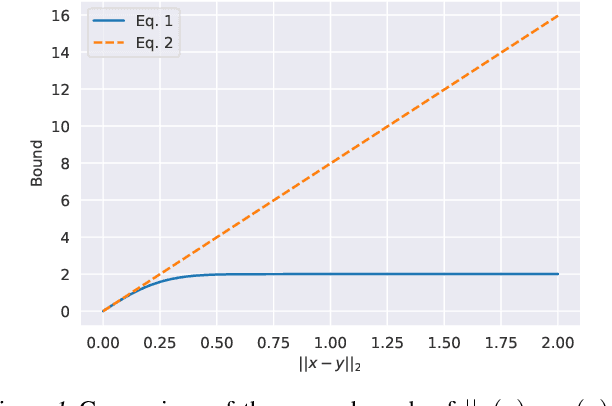
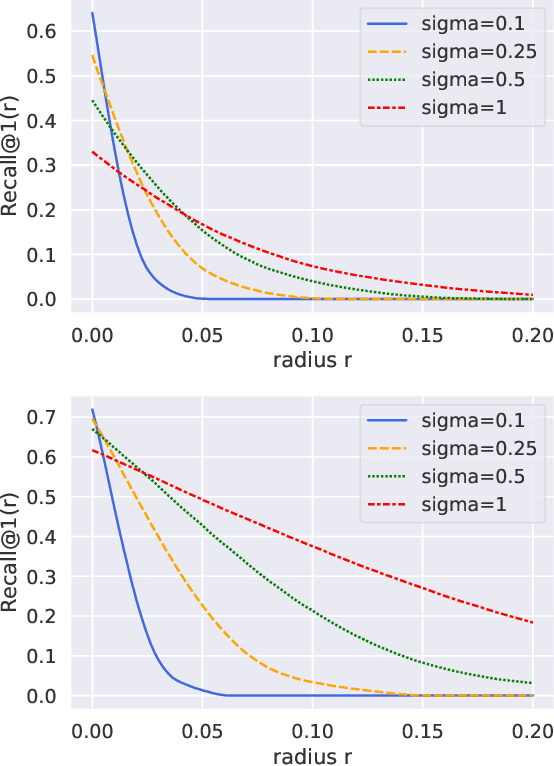
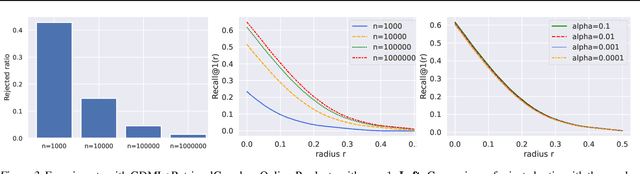
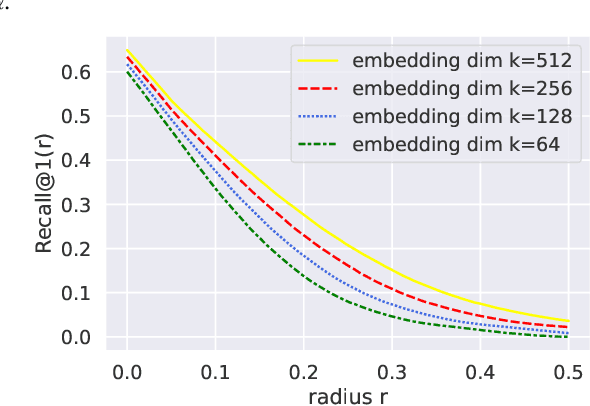
Recent research works have shown that image retrieval models are vulnerable to adversarial attacks, where slightly modified test inputs could lead to problematic retrieval results. In this paper, we aim to design a provably robust image retrieval model which keeps the most important evaluation metric Recall@1 invariant to adversarial perturbation. We propose the first 1-nearest neighbor (NN) image retrieval algorithm, RetrievalGuard, which is provably robust against adversarial perturbations within an $\ell_2$ ball of calculable radius. The challenge is to design a provably robust algorithm that takes into consideration the 1-NN search and the high-dimensional nature of the embedding space. Algorithmically, given a base retrieval model and a query sample, we build a smoothed retrieval model by carefully analyzing the 1-NN search procedure in the high-dimensional embedding space. We show that the smoothed retrieval model has bounded Lipschitz constant and thus the retrieval score is invariant to $\ell_2$ adversarial perturbations. Experiments on image retrieval tasks validate the robustness of our RetrievalGuard method.
Causal Balancing for Domain Generalization
Jun 10, 2022
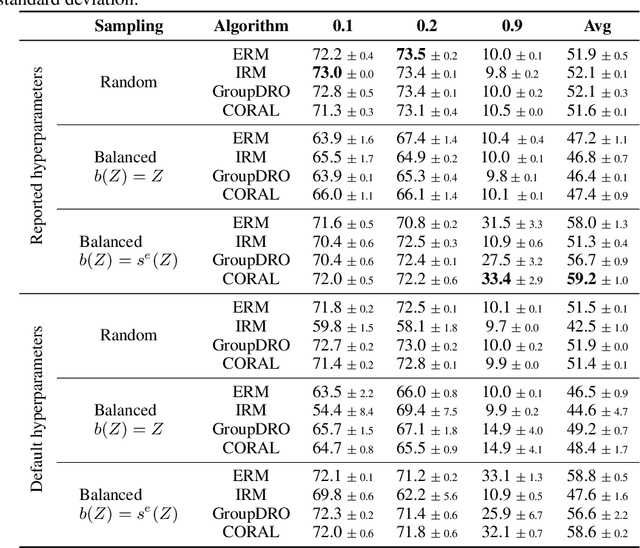
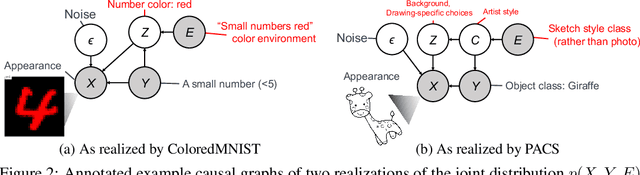
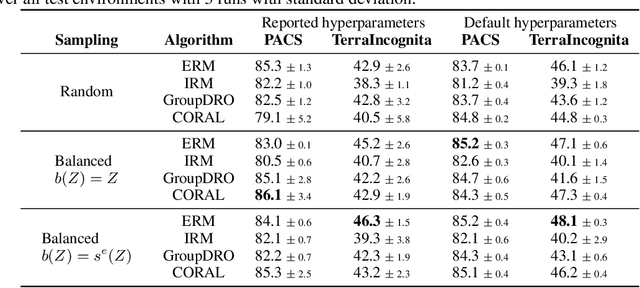
While machine learning models rapidly advance the state-of-the-art on various real-world tasks, out-of-domain (OOD) generalization remains a challenging problem given the vulnerability of these models to spurious correlations. While current domain generalization methods usually focus on enforcing certain invariance properties across different domains by new loss function designs, we propose a balanced mini-batch sampling strategy to reduce the domain-specific spurious correlations in the observed training distributions. More specifically, we propose a two-phased method that 1) identifies the source of spurious correlations, and 2) builds balanced mini-batches free from spurious correlations by matching on the identified source. We provide an identifiability guarantee of the source of spuriousness and show that our proposed approach provably samples from a balanced, spurious-free distribution over all training environments. Experiments are conducted on three computer vision datasets with documented spurious correlations, demonstrating empirically that our balanced mini-batch sampling strategy improves the performance of four different established domain generalization model baselines compared to the random mini-batch sampling strategy.
Building Robust Ensembles via Margin Boosting
Jun 07, 2022
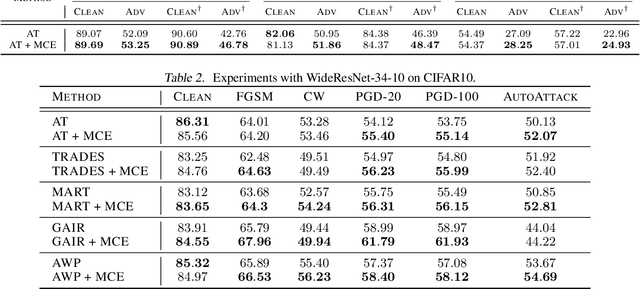

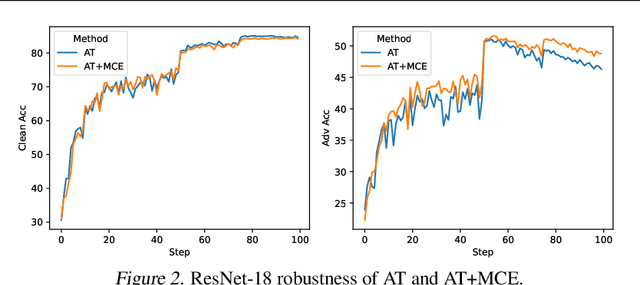
In the context of adversarial robustness, a single model does not usually have enough power to defend against all possible adversarial attacks, and as a result, has sub-optimal robustness. Consequently, an emerging line of work has focused on learning an ensemble of neural networks to defend against adversarial attacks. In this work, we take a principled approach towards building robust ensembles. We view this problem from the perspective of margin-boosting and develop an algorithm for learning an ensemble with maximum margin. Through extensive empirical evaluation on benchmark datasets, we show that our algorithm not only outperforms existing ensembling techniques, but also large models trained in an end-to-end fashion. An important byproduct of our work is a margin-maximizing cross-entropy (MCE) loss, which is a better alternative to the standard cross-entropy (CE) loss. Empirically, we show that replacing the CE loss in state-of-the-art adversarial training techniques with our MCE loss leads to significant performance improvement.
Certified Error Control of Candidate Set Pruning for Two-Stage Relevance Ranking
May 19, 2022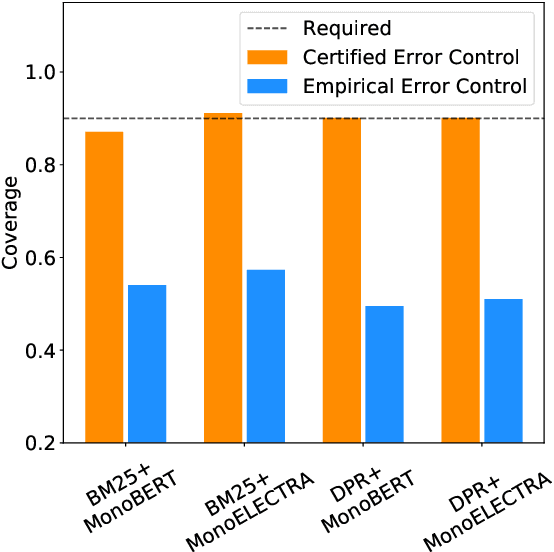

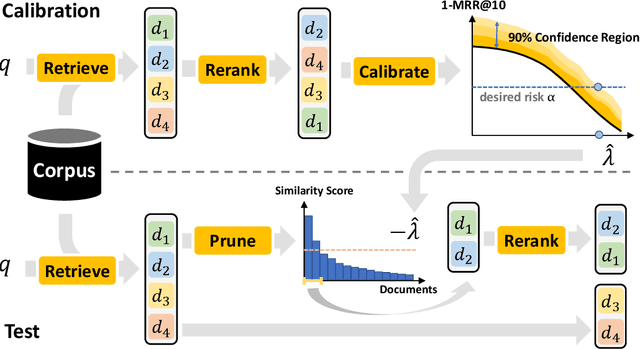
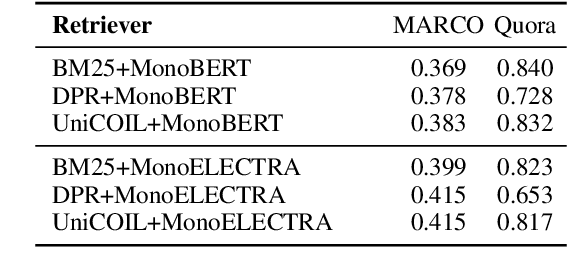
In information retrieval (IR), candidate set pruning has been commonly used to speed up two-stage relevance ranking. However, such an approach lacks accurate error control and often trades accuracy off against computational efficiency in an empirical fashion, lacking theoretical guarantees. In this paper, we propose the concept of certified error control of candidate set pruning for relevance ranking, which means that the test error after pruning is guaranteed to be controlled under a user-specified threshold with high probability. Both in-domain and out-of-domain experiments show that our method successfully prunes the first-stage retrieved candidate sets to improve the second-stage reranking speed while satisfying the pre-specified accuracy constraints in both settings. For example, on MS MARCO Passage v1, our method yields an average candidate set size of 27 out of 1,000 which increases the reranking speed by about 37 times, while the MRR@10 is greater than a pre-specified value of 0.38 with about 90% empirical coverage and the empirical baselines fail to provide such guarantee. Code and data are available at: https://github.com/alexlimh/CEC-Ranking.
How Many Data Are Needed for Robust Learning?
Feb 23, 2022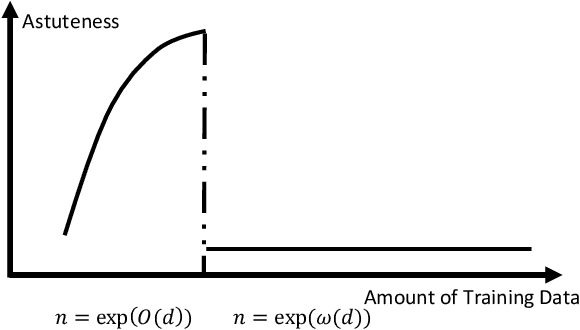
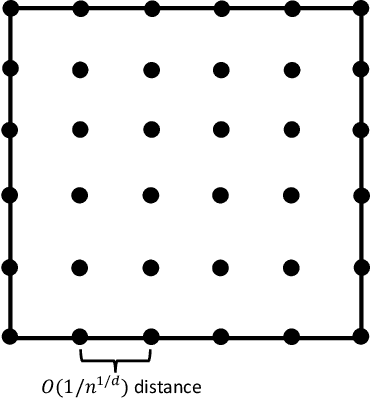
We show that the sample complexity of robust interpolation problem could be exponential in the input dimensionality and discover a phase transition phenomenon when the data are in a unit ball. Robust interpolation refers to the problem of interpolating $n$ noisy training data in $\R^d$ by a Lipschitz function. Although this problem has been well understood when the covariates are drawn from an isoperimetry distribution, much remains unknown concerning its performance under generic or even the worst-case distributions. Our results are two-fold: 1) too many data hurt robustness; we provide a tight and universal Lipschitzness lower bound $\Omega(n^{1/d})$ of the interpolating function for arbitrary data distributions. Our result disproves potential existence of an $\mathcal{O}(1)$-Lipschitz function in the overparametrization scenario when $n=\exp(\omega(d))$. 2) Small data hurt robustness: $n=\exp(\Omega(d))$ is necessary for obtaining a good population error under certain distributions by any $\mathcal{O}(1)$-Lipschitz learning algorithm. Perhaps surprisingly, our results shed light on the curse of big data and the blessing of dimensionality for robustness, and discover an intriguing phenomenon of phase transition at $n=\exp(\Theta(d))$.
Boosting Barely Robust Learners: A New Perspective on Adversarial Robustness
Feb 11, 2022We present an oracle-efficient algorithm for boosting the adversarial robustness of barely robust learners. Barely robust learning algorithms learn predictors that are adversarially robust only on a small fraction $\beta \ll 1$ of the data distribution. Our proposed notion of barely robust learning requires robustness with respect to a "larger" perturbation set; which we show is necessary for strongly robust learning, and that weaker relaxations are not sufficient for strongly robust learning. Our results reveal a qualitative and quantitative equivalence between two seemingly unrelated problems: strongly robust learning and barely robust learning.
Towards Transferable Unrestricted Adversarial Examples with Minimum Changes
Jan 04, 2022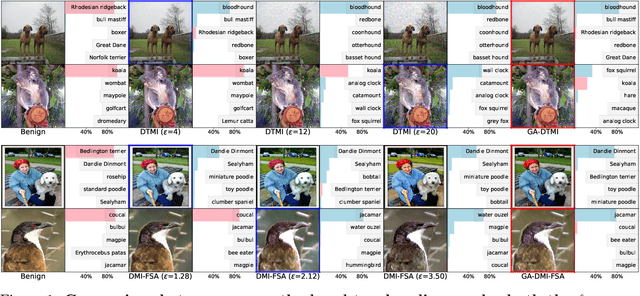

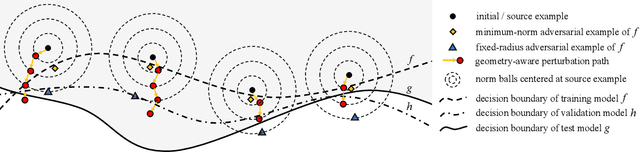
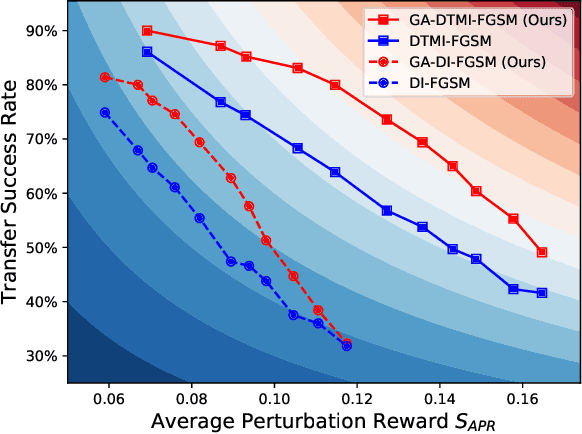
Transfer-based adversarial example is one of the most important classes of black-box attacks. However, there is a trade-off between transferability and imperceptibility of the adversarial perturbation. Prior work in this direction often requires a fixed but large $\ell_p$-norm perturbation budget to reach a good transfer success rate, leading to perceptible adversarial perturbations. On the other hand, most of the current unrestricted adversarial attacks that aim to generate semantic-preserving perturbations suffer from weaker transferability to the target model. In this work, we propose a geometry-aware framework to generate transferable adversarial examples with minimum changes. Analogous to model selection in statistical machine learning, we leverage a validation model to select the optimal perturbation budget for each image under both the $\ell_{\infty}$-norm and unrestricted threat models. Extensive experiments verify the effectiveness of our framework on balancing imperceptibility and transferability of the crafted adversarial examples. The methodology is the foundation of our entry to the CVPR'21 Security AI Challenger: Unrestricted Adversarial Attacks on ImageNet, in which we ranked 1st place out of 1,559 teams and surpassed the runner-up submissions by 4.59% and 23.91% in terms of final score and average image quality level, respectively. Code is available at https://github.com/Equationliu/GA-Attack.
Unrestricted Adversarial Attacks on ImageNet Competition
Oct 25, 2021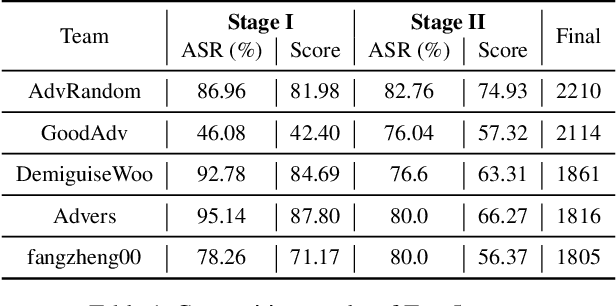
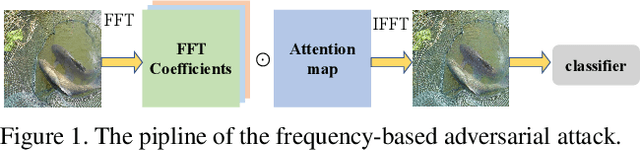
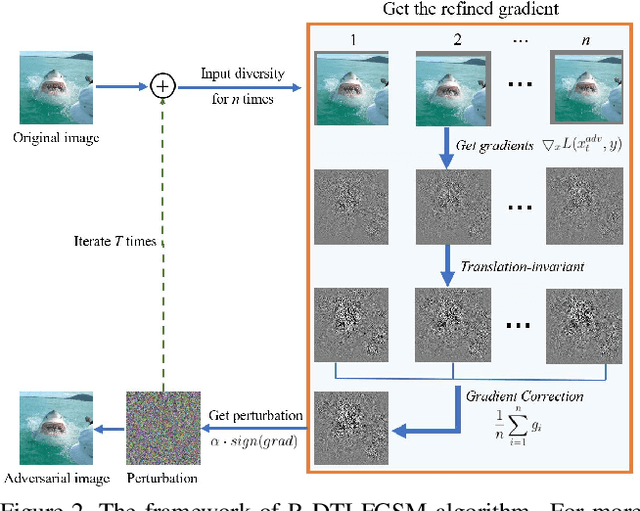
Many works have investigated the adversarial attacks or defenses under the settings where a bounded and imperceptible perturbation can be added to the input. However in the real-world, the attacker does not need to comply with this restriction. In fact, more threats to the deep model come from unrestricted adversarial examples, that is, the attacker makes large and visible modifications on the image, which causes the model classifying mistakenly, but does not affect the normal observation in human perspective. Unrestricted adversarial attack is a popular and practical direction but has not been studied thoroughly. We organize this competition with the purpose of exploring more effective unrestricted adversarial attack algorithm, so as to accelerate the academical research on the model robustness under stronger unbounded attacks. The competition is held on the TianChi platform (\url{https://tianchi.aliyun.com/competition/entrance/531853/introduction}) as one of the series of AI Security Challengers Program.
Self-Adaptive Training: Bridging the Supervised and Self-Supervised Learning
Jan 21, 2021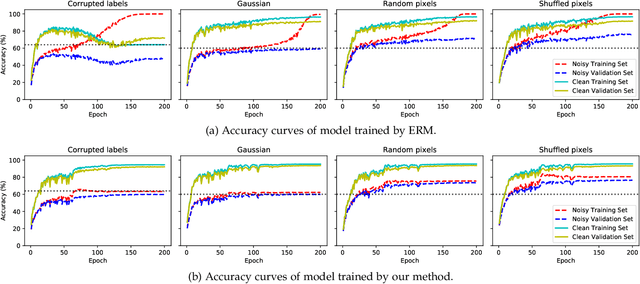
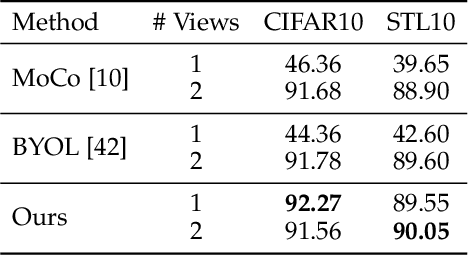
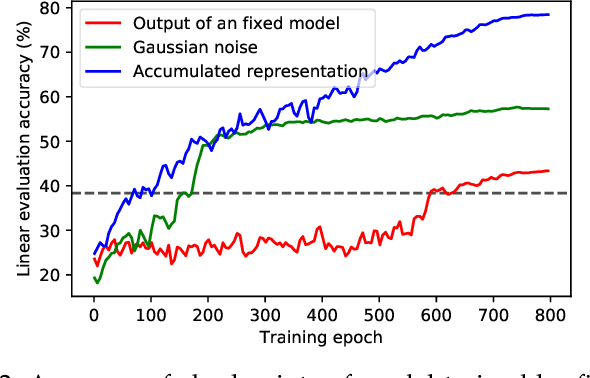
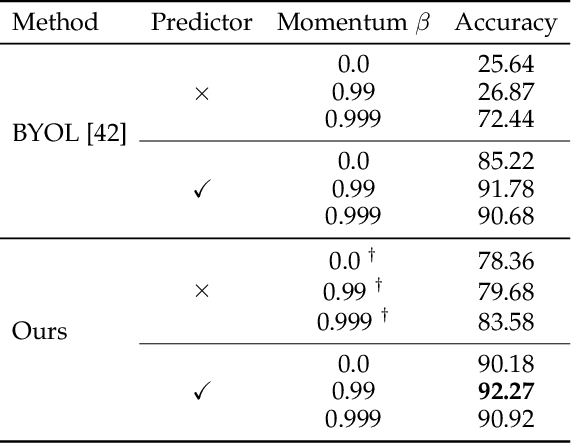
We propose self-adaptive training -- a unified training algorithm that dynamically calibrates and enhances training process by model predictions without incurring extra computational cost -- to advance both supervised and self-supervised learning of deep neural networks. We analyze the training dynamics of deep networks on training data that are corrupted by, e.g., random noise and adversarial examples. Our analysis shows that model predictions are able to magnify useful underlying information in data and this phenomenon occurs broadly even in the absence of \emph{any} label information, highlighting that model predictions could substantially benefit the training process: self-adaptive training improves the generalization of deep networks under noise and enhances the self-supervised representation learning. The analysis also sheds light on understanding deep learning, e.g., a potential explanation of the recently-discovered double-descent phenomenon in empirical risk minimization and the collapsing issue of the state-of-the-art self-supervised learning algorithms. Experiments on the CIFAR, STL and ImageNet datasets verify the effectiveness of our approach in three applications: classification with label noise, selective classification and linear evaluation. To facilitate future research, the code has been made public available at https://github.com/LayneH/self-adaptive-training.