 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemNovo: Look Back at the Spectrum for Balanced De Novo Peptide Sequencing from Mass Spectrometry
Jun 10, 2026De novo peptide sequencing from tandem mass spectrometry is pivotal in proteomics, enabling identification of novel peptides without reference databases. While recent Transformer-based encoder-decoder models have achieved remarkable performance, we uncover a critical pathology in their inference dynamics. Through comprehensive feature scaling experiments, we demonstrate that existing auto-regressive peptide decoders tend to over-rely on generated-sequence priors while progressively under-utilizing fine-grained physical evidence from the input mass spectrum. This phenomenon leads to suboptimal results, where generated peptide sequences are biologically plausible yet not faithful to the input spectrum. To rectify this, we propose MemNovo, a training-free and plug-and-play mechanism that re-balances peptide and spectral contributions at inference time. MemNovo alleviates the information bottleneck by establishing a persistent spectral memory bank and injecting retrieved features directly into the final decoding stage via an ultra-conservative residual connection. Theoretical analysis confirms that this mechanism restores the mutual information between the decoder state and the raw spectrum. Extensive experiments on the Nine Species benchmark with two representative baselines, Casanovo and InstaNovo, demonstrate that MemNovo consistently improves both amino acid precision and peptide precision, achieving up to 39.1% relative improvement in peptide precision for Casanovo and up to 3.9% for InstaNovo, with negligible computational overhead.
* Code: https://github.com/AIMS-Lab-HKUSTGZ/MemNovo
Refold: Refining Protein Inverse Folding with Efficient Structural Matching and Fusion
Mar 15, 2026Protein inverse folding aims to design an amino acid sequence that will fold into a given backbone structure, serving as a central task in protein design. Two main paradigms have been widely explored. Template-based methods exploit database-derived structural priors and can achieve high local precision when close structural neighbors are available, but their dependence on database coverage and match quality often degrades performance on out-of-distribution (OOD) targets. Deep learning approaches, in contrast, learn general structure-to-sequence regularities and usually generalize better to new backbones. However, they struggle to capture fine-grained local structure, which can cause uncertain residue predictions and missed local motifs in ambiguous regions. We introduce Refold, a novel framework that synergistically integrates the strengths of database-derived structural priors and deep learning prediction to enhance inverse folding. Refold obtains structural priors from matched neighbors and fuses them with model predictions to refine residue probabilities. In practice, low-quality neighbors can introduce noise, potentially degrading model performance. We address this issue with a Dynamic Utility Gate that controls prior injection and falls back to the base prediction when the priors are untrustworthy. Comprehensive evaluations on standard benchmarks demonstrate that Refold achieves state-of-the-art native sequence recovery of 0.63 on both CATH 4.2 and CATH 4.3. Also, analysis indicates that Refold delivers larger gains on high-uncertainty regions, reflecting the complementarity between structural priors and deep learning predictions.
Rethinking Genomic Modeling Through Optical Character Recognition
Feb 02, 2026Recent genomic foundation models largely adopt large language model architectures that treat DNA as a one-dimensional token sequence. However, exhaustive sequential reading is structurally misaligned with sparse and discontinuous genomic semantics, leading to wasted computation on low-information background and preventing understanding-driven compression for long contexts. Here, we present OpticalDNA, a vision-based framework that reframes genomic modeling as Optical Character Recognition (OCR)-style document understanding. OpticalDNA renders DNA into structured visual layouts and trains an OCR-capable vision--language model with a \emph{visual DNA encoder} and a \emph{document decoder}, where the encoder produces compact, reconstructible visual tokens for high-fidelity compression. Building on this representation, OpticalDNA defines prompt-conditioned objectives over core genomic primitives-reading, region grounding, subsequence retrieval, and masked span completion-thereby learning layout-aware DNA representations that retain fine-grained genomic information under a reduced effective token budget. Across diverse genomic benchmarks, OpticalDNA consistently outperforms recent baselines; on sequences up to 450k bases, it achieves the best overall performance with nearly $20\times$ fewer effective tokens, and surpasses models with up to $985\times$ more activated parameters while tuning only 256k \emph{trainable} parameters.
ImageDDI: Image-enhanced Molecular Motif Sequence Representation for Drug-Drug Interaction Prediction
Aug 11, 2025To mitigate the potential adverse health effects of simultaneous multi-drug use, including unexpected side effects and interactions, accurately identifying and predicting drug-drug interactions (DDIs) is considered a crucial task in the field of deep learning. Although existing methods have demonstrated promising performance, they suffer from the bottleneck of limited functional motif-based representation learning, as DDIs are fundamentally caused by motif interactions rather than the overall drug structures. In this paper, we propose an Image-enhanced molecular motif sequence representation framework for \textbf{DDI} prediction, called ImageDDI, which represents a pair of drugs from both global and local structures. Specifically, ImageDDI tokenizes molecules into functional motifs. To effectively represent a drug pair, their motifs are combined into a single sequence and embedded using a transformer-based encoder, starting from the local structure representation. By leveraging the associations between drug pairs, ImageDDI further enhances the spatial representation of molecules using global molecular image information (e.g. texture, shadow, color, and planar spatial relationships). To integrate molecular visual information into functional motif sequence, ImageDDI employs Adaptive Feature Fusion, enhancing the generalization of ImageDDI by dynamically adapting the fusion process of feature representations. Experimental results on widely used datasets demonstrate that ImageDDI outperforms state-of-the-art methods. Moreover, extensive experiments show that ImageDDI achieved competitive performance in both 2D and 3D image-enhanced scenarios compared to other models.
EDBench: Large-Scale Electron Density Data for Molecular Modeling
May 14, 2025



Existing molecular machine learning force fields (MLFFs) generally focus on the learning of atoms, molecules, and simple quantum chemical properties (such as energy and force), but ignore the importance of electron density (ED) $\rho(r)$ in accurately understanding molecular force fields (MFFs). ED describes the probability of finding electrons at specific locations around atoms or molecules, which uniquely determines all ground state properties (such as energy, molecular structure, etc.) of interactive multi-particle systems according to the Hohenberg-Kohn theorem. However, the calculation of ED relies on the time-consuming first-principles density functional theory (DFT) which leads to the lack of large-scale ED data and limits its application in MLFFs. In this paper, we introduce EDBench, a large-scale, high-quality dataset of ED designed to advance learning-based research at the electronic scale. Built upon the PCQM4Mv2, EDBench provides accurate ED data, covering 3.3 million molecules. To comprehensively evaluate the ability of models to understand and utilize electronic information, we design a suite of ED-centric benchmark tasks spanning prediction, retrieval, and generation. Our evaluation on several state-of-the-art methods demonstrates that learning from EDBench is not only feasible but also achieves high accuracy. Moreover, we show that learning-based method can efficiently calculate ED with comparable precision while significantly reducing the computational cost relative to traditional DFT calculations. All data and benchmarks from EDBench will be freely available, laying a robust foundation for ED-driven drug discovery and materials science.
Enhancing Chemical Reaction and Retrosynthesis Prediction with Large Language Model and Dual-task Learning
May 05, 2025



Chemical reaction and retrosynthesis prediction are fundamental tasks in drug discovery. Recently, large language models (LLMs) have shown potential in many domains. However, directly applying LLMs to these tasks faces two major challenges: (i) lacking a large-scale chemical synthesis-related instruction dataset; (ii) ignoring the close correlation between reaction and retrosynthesis prediction for the existing fine-tuning strategies. To address these challenges, we propose ChemDual, a novel LLM framework for accurate chemical synthesis. Specifically, considering the high cost of data acquisition for reaction and retrosynthesis, ChemDual regards the reaction-and-retrosynthesis of molecules as a related recombination-and-fragmentation process and constructs a large-scale of 4.4 million instruction dataset. Furthermore, ChemDual introduces an enhanced LLaMA, equipped with a multi-scale tokenizer and dual-task learning strategy, to jointly optimize the process of recombination and fragmentation as well as the tasks between reaction and retrosynthesis prediction. Extensive experiments on Mol-Instruction and USPTO-50K datasets demonstrate that ChemDual achieves state-of-the-art performance in both predictions of reaction and retrosynthesis, outperforming the existing conventional single-task approaches and the general open-source LLMs. Through molecular docking analysis, ChemDual generates compounds with diverse and strong protein binding affinity, further highlighting its strong potential in drug design.
FlexMol: A Flexible Toolkit for Benchmarking Molecular Relational Learning
Oct 19, 2024



Molecular relational learning (MRL) is crucial for understanding the interaction behaviors between molecular pairs, a critical aspect of drug discovery and development. However, the large feasible model space of MRL poses significant challenges to benchmarking, and existing MRL frameworks face limitations in flexibility and scope. To address these challenges, avoid repetitive coding efforts, and ensure fair comparison of models, we introduce FlexMol, a comprehensive toolkit designed to facilitate the construction and evaluation of diverse model architectures across various datasets and performance metrics. FlexMol offers a robust suite of preset model components, including 16 drug encoders, 13 protein sequence encoders, 9 protein structure encoders, and 7 interaction layers. With its easy-to-use API and flexibility, FlexMol supports the dynamic construction of over 70, 000 distinct combinations of model architectures. Additionally, we provide detailed benchmark results and code examples to demonstrate FlexMol's effectiveness in simplifying and standardizing MRL model development and comparison.
Class Knowledge Overlay to Visual Feature Learning for Zero-Shot Image Classification
Feb 26, 2021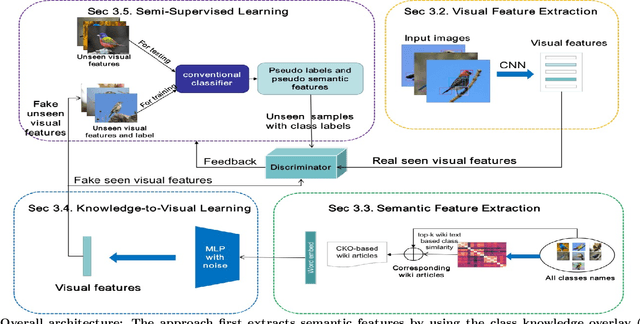
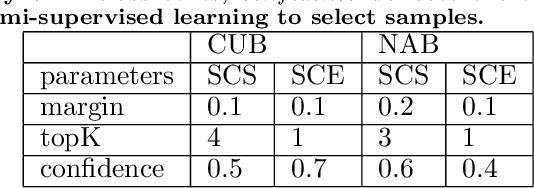
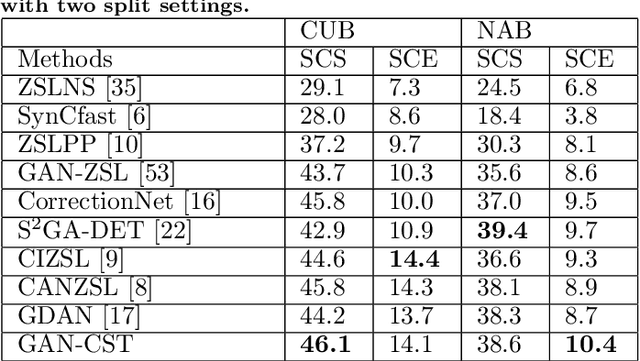
New categories can be discovered by transforming semantic features into synthesized visual features without corresponding training samples in zero-shot image classification. Although significant progress has been made in generating high-quality synthesized visual features using generative adversarial networks, guaranteeing semantic consistency between the semantic features and visual features remains very challenging. In this paper, we propose a novel zero-shot learning approach, GAN-CST, based on class knowledge to visual feature learning to tackle the problem. The approach consists of three parts, class knowledge overlay, semi-supervised learning and triplet loss. It applies class knowledge overlay (CKO) to obtain knowledge not only from the corresponding class but also from other classes that have the knowledge overlay. It ensures that the knowledge-to-visual learning process has adequate information to generate synthesized visual features. The approach also applies a semi-supervised learning process to re-train knowledge-to-visual model. It contributes to reinforcing synthesized visual features generation as well as new category prediction. We tabulate results on a number of benchmark datasets demonstrating that the proposed model delivers superior performance over state-of-the-art approaches.
Multi-Knowledge Fusion for New Feature Generation in Generalized Zero-Shot Learning
Feb 23, 2021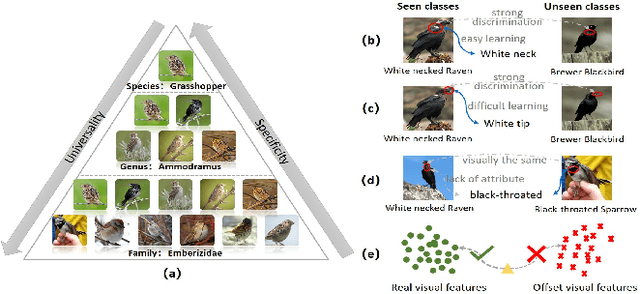
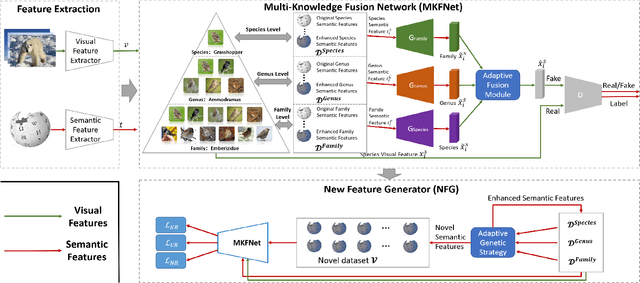
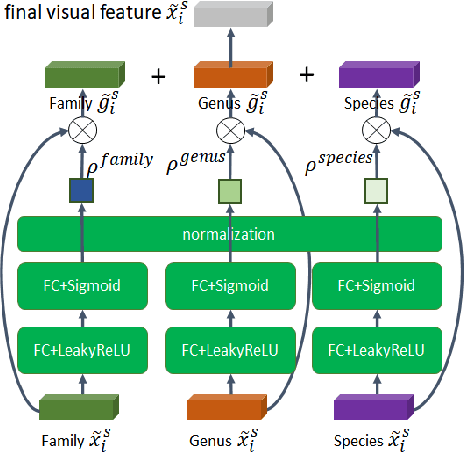
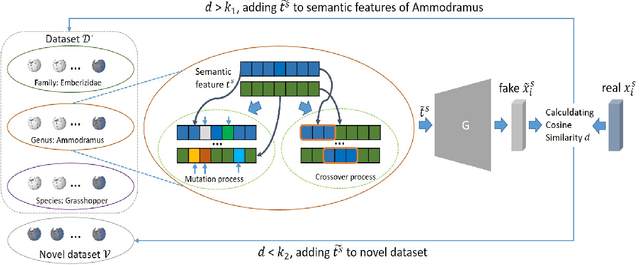
Suffering from the semantic insufficiency and domain-shift problems, most of existing state-of-the-art methods fail to achieve satisfactory results for Zero-Shot Learning (ZSL). In order to alleviate these problems, we propose a novel generative ZSL method to learn more generalized features from multi-knowledge with continuously generated new semantics in semantic-to-visual embedding. In our approach, the proposed Multi-Knowledge Fusion Network (MKFNet) takes different semantic features from multi-knowledge as input, which enables more relevant semantic features to be trained for semantic-to-visual embedding, and finally generates more generalized visual features by adaptively fusing visual features from different knowledge domain. The proposed New Feature Generator (NFG) with adaptive genetic strategy is used to enrich semantic information on the one hand, and on the other hand it greatly improves the intersection of visual feature generated by MKFNet and unseen visual faetures. Empirically, we show that our approach can achieve significantly better performance compared to existing state-of-the-art methods on a large number of benchmarks for several ZSL tasks, including traditional ZSL, generalized ZSL and zero-shot retrieval.
Cross Knowledge-based Generative Zero-Shot Learning Approach with Taxonomy Regularization
Jan 25, 2021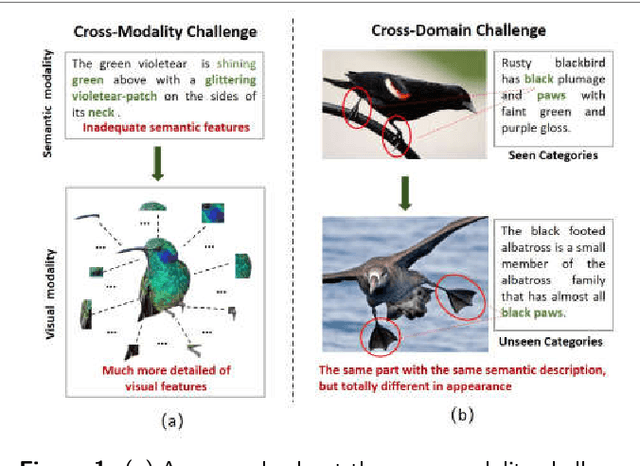
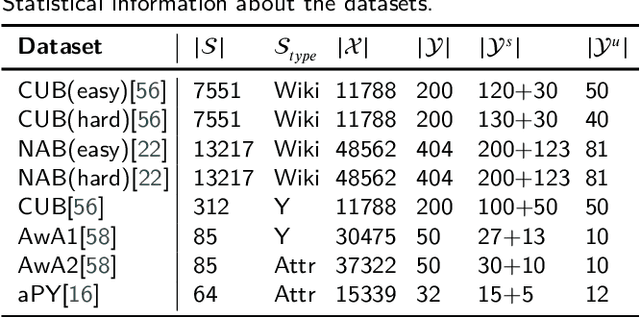
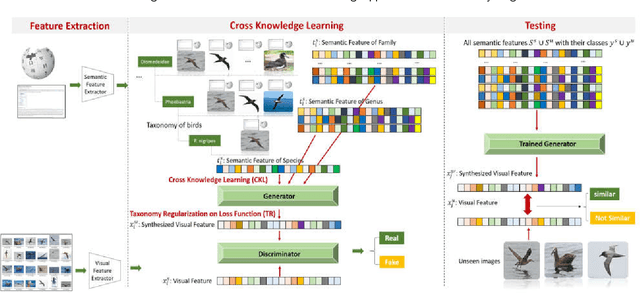
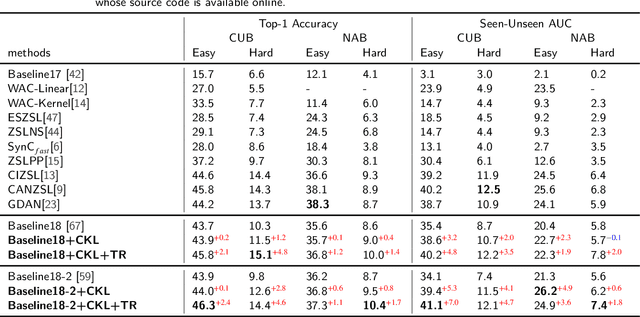
Although zero-shot learning (ZSL) has an inferential capability of recognizing new classes that have never been seen before, it always faces two fundamental challenges of the cross modality and crossdomain challenges. In order to alleviate these problems, we develop a generative network-based ZSL approach equipped with the proposed Cross Knowledge Learning (CKL) scheme and Taxonomy Regularization (TR). In our approach, the semantic features are taken as inputs, and the output is the synthesized visual features generated from the corresponding semantic features. CKL enables more relevant semantic features to be trained for semantic-to-visual feature embedding in ZSL, while Taxonomy Regularization (TR) significantly improves the intersections with unseen images with more generalized visual features generated from generative network. Extensive experiments on several benchmark datasets (i.e., AwA1, AwA2, CUB, NAB and aPY) show that our approach is superior to these state-of-the-art methods in terms of ZSL image classification and retrieval.