 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopo-R1: Detecting Topological Anomalies via Vision-Language Models
Mar 13, 2026Topological correctness is crucial for tubular structures such as blood vessels, nerve fibers, and road networks. Existing topology-preserving methods rely on domain-specific ground truth, which is costly and rarely transfers across domains. When deployed to a new domain without annotations, a key question arises: how can we detect topological anomalies without ground-truth supervision? We reframe this as topological anomaly detection, a structured visual reasoning task requiring a model to locate and classify topological errors in predicted segmentation masks. Vision-Language Models (VLMs) are natural candidates; however, we find that state-of-the-art VLMs perform nearly at random, lacking the fine-grained, topology-aware perception needed to identify sparse connectivity errors in dense structures. To bridge this gap, we develop an automated data-curation pipeline that synthesizes diverse topological anomalies with verifiable annotations across progressively difficult levels, thereby constructing the first large-scale, multi-domain benchmark for this task. We then introduce Topo-R1, a framework that endows VLMs with topology-aware perception via two-stage training: supervised fine-tuning followed by reinforcement learning with Group Relative Policy Optimization (GRPO). Central to our approach is a topology-aware composite reward that integrates type-aware Hungarian matching for structured error classification, spatial localization scoring, and a centerline Dice (clDice) reward that directly penalizes connectivity disruptions, thereby jointly incentivizing semantic precision and structural fidelity. Extensive experiments demonstrate that Topo-R1 establishes a new paradigm for annotation-free topological quality assessment, consistently outperforming general-purpose VLMs and supervised baselines across all evaluation protocols.
Act Like a Pathologist: Tissue-Aware Whole Slide Image Reasoning
Feb 28, 2026Computational pathology has advanced rapidly in recent years, driven by domain-specific image encoders and growing interest in using vision-language models to answer natural-language questions about diseases. Yet, the core problem behind pathology question-answering remains unsolved, considering that a gigapixel slide contains far more information than necessary for a given question. Pathologists naturally navigate tissue and morphology complexity by scanning broadly, and zooming in selectively according to the clinical questions. Current models, in contrast, rely on uniform patch sampling or broad attention maps, often attending equally to irrelevant regions while overlooking key visual evidence. In this work, we try to bring models closer to how humans actually examine slides. We propose a question-guided, tissue-aware, and coarse-to-fine retrieval framework, HistoSelect, that consists of two key components: a group sampler that identifies question-relevant tissue regions, followed by a patch selector that retrieves the most informative patches within those regions. By selecting only the most informative patches, our method becomes significantly more efficient: reducing visual token usage by 70% on average, while improving accuracy across three pathology QA tasks. Evaluated on 356,000 question-answer pairs, our approach outperforms existing methods and produces answers grounded in interpretable, pathologist-consistent regions. Our results suggest that bringing human-like search and attention patterns into WSI reasoning is a promising direction for building practical and reliable pathology VLMs.
Learning Brain Tumor Representation in 3D High-Resolution MR Images via Interpretable State Space Models
Sep 12, 2024



Learning meaningful and interpretable representations from high-dimensional volumetric magnetic resonance (MR) images is essential for advancing personalized medicine. While Vision Transformers (ViTs) have shown promise in handling image data, their application to 3D multi-contrast MR images faces challenges due to computational complexity and interpretability. To address this, we propose a novel state-space-model (SSM)-based masked autoencoder which scales ViT-like models to handle high-resolution data effectively while also enhancing the interpretability of learned representations. We propose a latent-to-spatial mapping technique that enables direct visualization of how latent features correspond to specific regions in the input volumes in the context of SSM. We validate our method on two key neuro-oncology tasks: identification of isocitrate dehydrogenase mutation status and 1p/19q co-deletion classification, achieving state-of-the-art accuracy. Our results highlight the potential of SSM-based self-supervised learning to transform radiomics analysis by combining efficiency and interpretability.
Inter-Rater Uncertainty Quantification in Medical Image Segmentation via Rater-Specific Bayesian Neural Networks
Jun 28, 2023



Automated medical image segmentation inherently involves a certain degree of uncertainty. One key factor contributing to this uncertainty is the ambiguity that can arise in determining the boundaries of a target region of interest, primarily due to variations in image appearance. On top of this, even among experts in the field, different opinions can emerge regarding the precise definition of specific anatomical structures. This work specifically addresses the modeling of segmentation uncertainty, known as inter-rater uncertainty. Its primary objective is to explore and analyze the variability in segmentation outcomes that can occur when multiple experts in medical imaging interpret and annotate the same images. We introduce a novel Bayesian neural network-based architecture to estimate inter-rater uncertainty in medical image segmentation. Our approach has three key advancements. Firstly, we introduce a one-encoder-multi-decoder architecture specifically tailored for uncertainty estimation, enabling us to capture the rater-specific representation of each expert involved. Secondly, we propose Bayesian modeling for the new architecture, allowing efficient capture of the inter-rater distribution, particularly in scenarios with limited annotations. Lastly, we enhance the rater-specific representation by integrating an attention module into each decoder. This module facilitates focused and refined segmentation results for each rater. We conduct extensive evaluations using synthetic and real-world datasets to validate our technical innovations rigorously. Our method surpasses existing baseline methods in five out of seven diverse tasks on the publicly available \emph{QUBIQ} dataset, considering two evaluation metrics encompassing different uncertainty aspects. Our codes, models, and the new dataset are available through our GitHub repository: https://github.com/HaoWang420/bOEMD-net .
Domain-Adaptive 3D Medical Image Synthesis: An Efficient Unsupervised Approach
Jul 02, 2022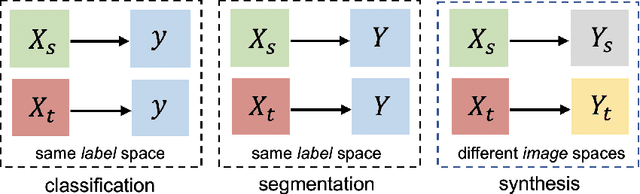

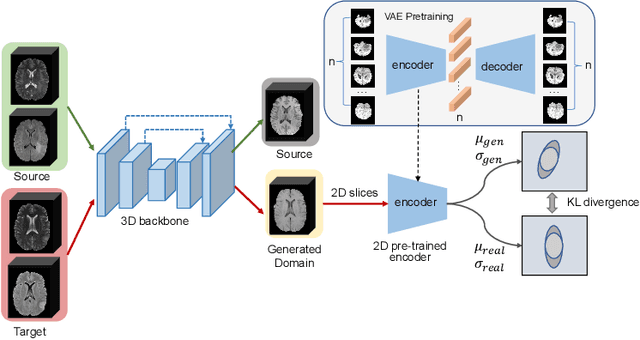
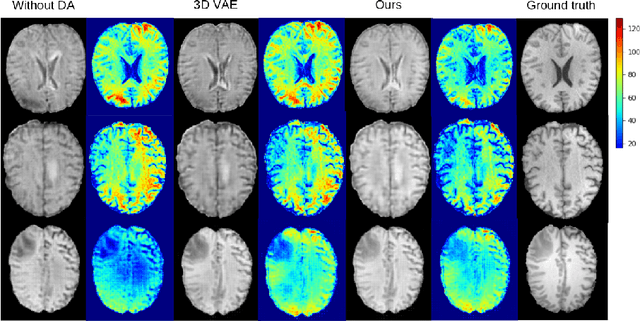
Medical image synthesis has attracted increasing attention because it could generate missing image data, improving diagnosis and benefits many downstream tasks. However, so far the developed synthesis model is not adaptive to unseen data distribution that presents domain shift, limiting its applicability in clinical routine. This work focuses on exploring domain adaptation (DA) of 3D image-to-image synthesis models. First, we highlight the technical difference in DA between classification, segmentation and synthesis models. Second, we present a novel efficient adaptation approach based on 2D variational autoencoder which approximates 3D distributions. Third, we present empirical studies on the effect of the amount of adaptation data and the key hyper-parameters. Our results show that the proposed approach can significantly improve the synthesis accuracy on unseen domains in a 3D setting. The code is publicly available at https://github.com/WinstonHuTiger/2D_VAE_UDA_for_3D_sythesis