 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative validation of surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation in endoscopy: Results of the PhaKIR 2024 challenge
Jul 22, 2025Reliable recognition and localization of surgical instruments in endoscopic video recordings are foundational for a wide range of applications in computer- and robot-assisted minimally invasive surgery (RAMIS), including surgical training, skill assessment, and autonomous assistance. However, robust performance under real-world conditions remains a significant challenge. Incorporating surgical context - such as the current procedural phase - has emerged as a promising strategy to improve robustness and interpretability. To address these challenges, we organized the Surgical Procedure Phase, Keypoint, and Instrument Recognition (PhaKIR) sub-challenge as part of the Endoscopic Vision (EndoVis) challenge at MICCAI 2024. We introduced a novel, multi-center dataset comprising thirteen full-length laparoscopic cholecystectomy videos collected from three distinct medical institutions, with unified annotations for three interrelated tasks: surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation. Unlike existing datasets, ours enables joint investigation of instrument localization and procedural context within the same data while supporting the integration of temporal information across entire procedures. We report results and findings in accordance with the BIAS guidelines for biomedical image analysis challenges. The PhaKIR sub-challenge advances the field by providing a unique benchmark for developing temporally aware, context-driven methods in RAMIS and offers a high-quality resource to support future research in surgical scene understanding.
TR2M: Transferring Monocular Relative Depth to Metric Depth with Language Descriptions and Scale-Oriented Contrast
Jun 16, 2025This work presents a generalizable framework to transfer relative depth to metric depth. Current monocular depth estimation methods are mainly divided into metric depth estimation (MMDE) and relative depth estimation (MRDE). MMDEs estimate depth in metric scale but are often limited to a specific domain. MRDEs generalize well across different domains, but with uncertain scales which hinders downstream applications. To this end, we aim to build up a framework to solve scale uncertainty and transfer relative depth to metric depth. Previous methods used language as input and estimated two factors for conducting rescaling. Our approach, TR2M, utilizes both text description and image as inputs and estimates two rescale maps to transfer relative depth to metric depth at pixel level. Features from two modalities are fused with a cross-modality attention module to better capture scale information. A strategy is designed to construct and filter confident pseudo metric depth for more comprehensive supervision. We also develop scale-oriented contrastive learning to utilize depth distribution as guidance to enforce the model learning about intrinsic knowledge aligning with the scale distribution. TR2M only exploits a small number of trainable parameters to train on datasets in various domains and experiments not only demonstrate TR2M's great performance in seen datasets but also reveal superior zero-shot capabilities on five unseen datasets. We show the huge potential in pixel-wise transferring relative depth to metric depth with language assistance. (Code is available at: https://github.com/BeileiCui/TR2M)
EndoARSS: Adapting Spatially-Aware Foundation Model for Efficient Activity Recognition and Semantic Segmentation in Endoscopic Surgery
Jun 07, 2025Endoscopic surgery is the gold standard for robotic-assisted minimally invasive surgery, offering significant advantages in early disease detection and precise interventions. However, the complexity of surgical scenes, characterized by high variability in different surgical activity scenarios and confused image features between targets and the background, presents challenges for surgical environment understanding. Traditional deep learning models often struggle with cross-activity interference, leading to suboptimal performance in each downstream task. To address this limitation, we explore multi-task learning, which utilizes the interrelated features between tasks to enhance overall task performance. In this paper, we propose EndoARSS, a novel multi-task learning framework specifically designed for endoscopy surgery activity recognition and semantic segmentation. Built upon the DINOv2 foundation model, our approach integrates Low-Rank Adaptation to facilitate efficient fine-tuning while incorporating Task Efficient Shared Low-Rank Adapters to mitigate gradient conflicts across diverse tasks. Additionally, we introduce the Spatially-Aware Multi-Scale Attention that enhances feature representation discrimination by enabling cross-spatial learning of global information. In order to evaluate the effectiveness of our framework, we present three novel datasets, MTLESD, MTLEndovis and MTLEndovis-Gen, tailored for endoscopic surgery scenarios with detailed annotations for both activity recognition and semantic segmentation tasks. Extensive experiments demonstrate that EndoARSS achieves remarkable performance across multiple benchmarks, significantly improving both accuracy and robustness in comparison to existing models. These results underscore the potential of EndoARSS to advance AI-driven endoscopic surgical systems, offering valuable insights for enhancing surgical safety and efficiency.
EndoVLA: Dual-Phase Vision-Language-Action Model for Autonomous Tracking in Endoscopy
May 21, 2025In endoscopic procedures, autonomous tracking of abnormal regions and following circumferential cutting markers can significantly reduce the cognitive burden on endoscopists. However, conventional model-based pipelines are fragile for each component (e.g., detection, motion planning) requires manual tuning and struggles to incorporate high-level endoscopic intent, leading to poor generalization across diverse scenes. Vision-Language-Action (VLA) models, which integrate visual perception, language grounding, and motion planning within an end-to-end framework, offer a promising alternative by semantically adapting to surgeon prompts without manual recalibration. Despite their potential, applying VLA models to robotic endoscopy presents unique challenges due to the complex and dynamic anatomical environments of the gastrointestinal (GI) tract. To address this, we introduce EndoVLA, designed specifically for continuum robots in GI interventions. Given endoscopic images and surgeon-issued tracking prompts, EndoVLA performs three core tasks: (1) polyp tracking, (2) delineation and following of abnormal mucosal regions, and (3) adherence to circular markers during circumferential cutting. To tackle data scarcity and domain shifts, we propose a dual-phase strategy comprising supervised fine-tuning on our EndoVLA-Motion dataset and reinforcement fine-tuning with task-aware rewards. Our approach significantly improves tracking performance in endoscopy and enables zero-shot generalization in diverse scenes and complex sequential tasks.
Can DeepSeek Reason Like a Surgeon? An Empirical Evaluation for Vision-Language Understanding in Robotic-Assisted Surgery
Apr 02, 2025DeepSeek series have demonstrated outstanding performance in general scene understanding, question-answering (QA), and text generation tasks, owing to its efficient training paradigm and strong reasoning capabilities. In this study, we investigate the dialogue capabilities of the DeepSeek model in robotic surgery scenarios, focusing on tasks such as Single Phrase QA, Visual QA, and Detailed Description. The Single Phrase QA tasks further include sub-tasks such as surgical instrument recognition, action understanding, and spatial position analysis. We conduct extensive evaluations using publicly available datasets, including EndoVis18 and CholecT50, along with their corresponding dialogue data. Our comprehensive evaluation results indicate that, when provided with specific prompts, DeepSeek-V3 performs well in surgical instrument and tissue recognition tasks However, DeepSeek-V3 exhibits significant limitations in spatial position analysis and struggles to understand surgical actions accurately. Additionally, our findings reveal that, under general prompts, DeepSeek-V3 lacks the ability to effectively analyze global surgical concepts and fails to provide detailed insights into surgical scenarios. Based on our observations, we argue that the DeepSeek-V3 is not ready for vision-language tasks in surgical contexts without fine-tuning on surgery-specific datasets.
Point Tracking in Surgery--The 2024 Surgical Tattoos in Infrared (STIR) Challenge
Mar 31, 2025Understanding tissue motion in surgery is crucial to enable applications in downstream tasks such as segmentation, 3D reconstruction, virtual tissue landmarking, autonomous probe-based scanning, and subtask autonomy. Labeled data are essential to enabling algorithms in these downstream tasks since they allow us to quantify and train algorithms. This paper introduces a point tracking challenge to address this, wherein participants can submit their algorithms for quantification. The submitted algorithms are evaluated using a dataset named surgical tattoos in infrared (STIR), with the challenge aptly named the STIR Challenge 2024. The STIR Challenge 2024 comprises two quantitative components: accuracy and efficiency. The accuracy component tests the accuracy of algorithms on in vivo and ex vivo sequences. The efficiency component tests the latency of algorithm inference. The challenge was conducted as a part of MICCAI EndoVis 2024. In this challenge, we had 8 total teams, with 4 teams submitting before and 4 submitting after challenge day. This paper details the STIR Challenge 2024, which serves to move the field towards more accurate and efficient algorithms for spatial understanding in surgery. In this paper we summarize the design, submissions, and results from the challenge. The challenge dataset is available here: https://zenodo.org/records/14803158 , and the code for baseline models and metric calculation is available here: https://github.com/athaddius/STIRMetrics
Learning to Efficiently Adapt Foundation Models for Self-Supervised Endoscopic 3D Scene Reconstruction from Any Cameras
Mar 20, 2025



Accurate 3D scene reconstruction is essential for numerous medical tasks. Given the challenges in obtaining ground truth data, there has been an increasing focus on self-supervised learning (SSL) for endoscopic depth estimation as a basis for scene reconstruction. While foundation models have shown remarkable progress in visual tasks, their direct application to the medical domain often leads to suboptimal results. However, the visual features from these models can still enhance endoscopic tasks, emphasizing the need for efficient adaptation strategies, which still lack exploration currently. In this paper, we introduce Endo3DAC, a unified framework for endoscopic scene reconstruction that efficiently adapts foundation models. We design an integrated network capable of simultaneously estimating depth maps, relative poses, and camera intrinsic parameters. By freezing the backbone foundation model and training only the specially designed Gated Dynamic Vector-Based Low-Rank Adaptation (GDV-LoRA) with separate decoder heads, Endo3DAC achieves superior depth and pose estimation while maintaining training efficiency. Additionally, we propose a 3D scene reconstruction pipeline that optimizes depth maps' scales, shifts, and a few parameters based on our integrated network. Extensive experiments across four endoscopic datasets demonstrate that Endo3DAC significantly outperforms other state-of-the-art methods while requiring fewer trainable parameters. To our knowledge, we are the first to utilize a single network that only requires surgical videos to perform both SSL depth estimation and scene reconstruction tasks. The code will be released upon acceptance.
Advancing Dense Endoscopic Reconstruction with Gaussian Splatting-driven Surface Normal-aware Tracking and Mapping
Jan 31, 2025



Simultaneous Localization and Mapping (SLAM) is essential for precise surgical interventions and robotic tasks in minimally invasive procedures. While recent advancements in 3D Gaussian Splatting (3DGS) have improved SLAM with high-quality novel view synthesis and fast rendering, these systems struggle with accurate depth and surface reconstruction due to multi-view inconsistencies. Simply incorporating SLAM and 3DGS leads to mismatches between the reconstructed frames. In this work, we present Endo-2DTAM, a real-time endoscopic SLAM system with 2D Gaussian Splatting (2DGS) to address these challenges. Endo-2DTAM incorporates a surface normal-aware pipeline, which consists of tracking, mapping, and bundle adjustment modules for geometrically accurate reconstruction. Our robust tracking module combines point-to-point and point-to-plane distance metrics, while the mapping module utilizes normal consistency and depth distortion to enhance surface reconstruction quality. We also introduce a pose-consistent strategy for efficient and geometrically coherent keyframe sampling. Extensive experiments on public endoscopic datasets demonstrate that Endo-2DTAM achieves an RMSE of $1.87\pm 0.63$ mm for depth reconstruction of surgical scenes while maintaining computationally efficient tracking, high-quality visual appearance, and real-time rendering. Our code will be released at github.com/lastbasket/Endo-2DTAM.
EndoChat: Grounded Multimodal Large Language Model for Endoscopic Surgery
Jan 20, 2025



Recently, Multimodal Large Language Models (MLLMs) have demonstrated their immense potential in computer-aided diagnosis and decision-making. In the context of robotic-assisted surgery, MLLMs can serve as effective tools for surgical training and guidance. However, there is still a lack of MLLMs specialized for surgical scene understanding in clinical applications. In this work, we introduce EndoChat to address various dialogue paradigms and subtasks in surgical scene understanding that surgeons encounter. To train our EndoChat, we construct the Surg-396K dataset through a novel pipeline that systematically extracts surgical information and generates structured annotations based on collected large-scale endoscopic surgery datasets. Furthermore, we introduce a multi-scale visual token interaction mechanism and a visual contrast-based reasoning mechanism to enhance the model's representation learning and reasoning capabilities. Our model achieves state-of-the-art performance across five dialogue paradigms and eight surgical scene understanding tasks. Additionally, we conduct evaluations with professional surgeons, most of whom provide positive feedback on collaborating with EndoChat. Overall, these results demonstrate that our EndoChat has great potential to significantly advance training and automation in robotic-assisted surgery.
V$^2$-SfMLearner: Learning Monocular Depth and Ego-motion for Multimodal Wireless Capsule Endoscopy
Dec 23, 2024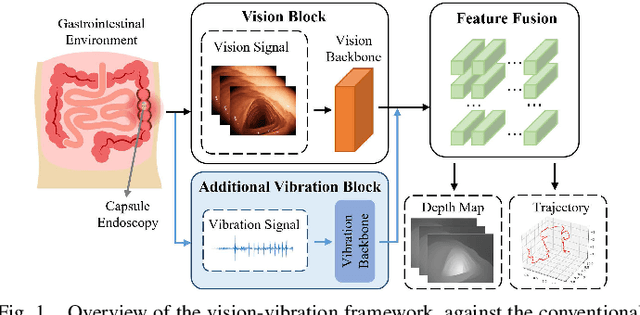
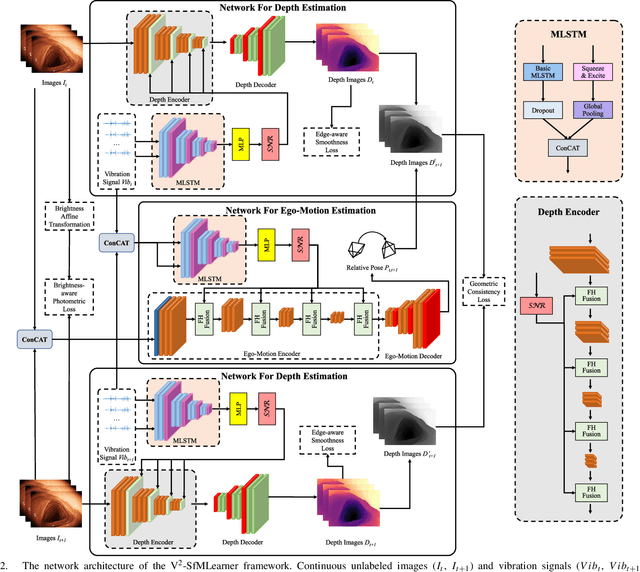
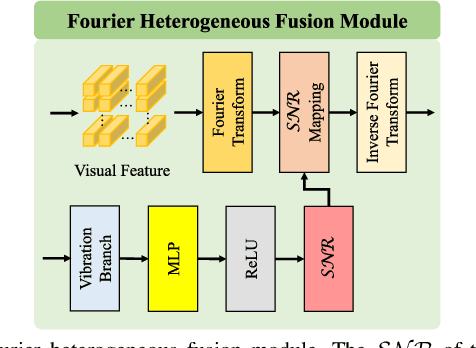
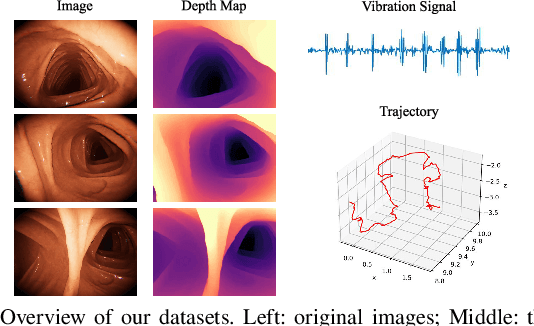
Deep learning can predict depth maps and capsule ego-motion from capsule endoscopy videos, aiding in 3D scene reconstruction and lesion localization. However, the collisions of the capsule endoscopies within the gastrointestinal tract cause vibration perturbations in the training data. Existing solutions focus solely on vision-based processing, neglecting other auxiliary signals like vibrations that could reduce noise and improve performance. Therefore, we propose V$^2$-SfMLearner, a multimodal approach integrating vibration signals into vision-based depth and capsule motion estimation for monocular capsule endoscopy. We construct a multimodal capsule endoscopy dataset containing vibration and visual signals, and our artificial intelligence solution develops an unsupervised method using vision-vibration signals, effectively eliminating vibration perturbations through multimodal learning. Specifically, we carefully design a vibration network branch and a Fourier fusion module, to detect and mitigate vibration noises. The fusion framework is compatible with popular vision-only algorithms. Extensive validation on the multimodal dataset demonstrates superior performance and robustness against vision-only algorithms. Without the need for large external equipment, our V$^2$-SfMLearner has the potential for integration into clinical capsule robots, providing real-time and dependable digestive examination tools. The findings show promise for practical implementation in clinical settings, enhancing the diagnostic capabilities of doctors.