 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Does Hierarchy Work So Well in Reinforcement Learning?
Sep 23, 2019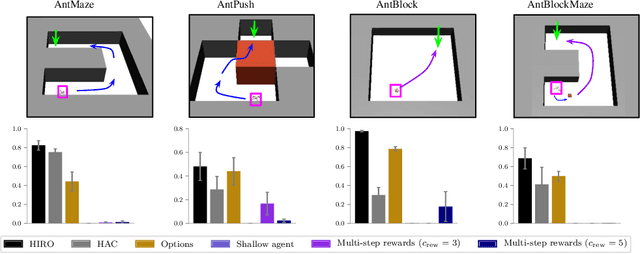
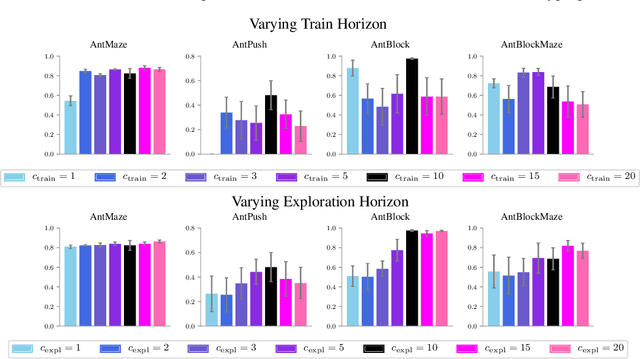
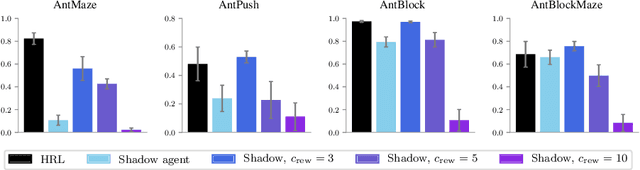
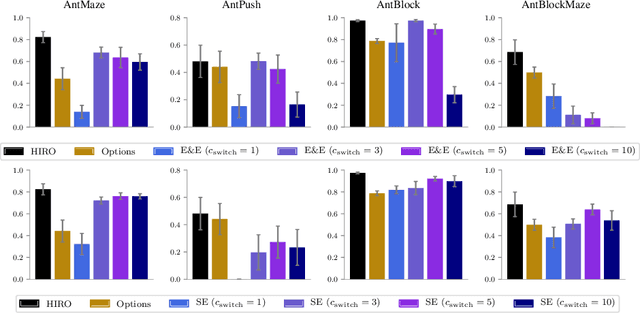
Hierarchical reinforcement learning has demonstrated significant success at solving difficult reinforcement learning (RL) tasks. Previous works have motivated the use of hierarchy by appealing to a number of intuitive benefits, including learning over temporally extended transitions, exploring over temporally extended periods, and training and exploring in a more semantically meaningful action space, among others. However, in fully observed, Markovian settings, it is not immediately clear why hierarchical RL should provide benefits over standard "shallow" RL architectures. In this work, we isolate and evaluate the claimed benefits of hierarchical RL on a suite of tasks encompassing locomotion, navigation, and manipulation. Surprisingly, we find that most of the observed benefits of hierarchy can be attributed to improved exploration, as opposed to easier policy learning or imposed hierarchical structures. Given this insight, we present exploration techniques inspired by hierarchy that achieve performance competitive with hierarchical RL while at the same time being much simpler to use and implement.
Efficient Exploration with Self-Imitation Learning via Trajectory-Conditioned Policy
Jul 24, 2019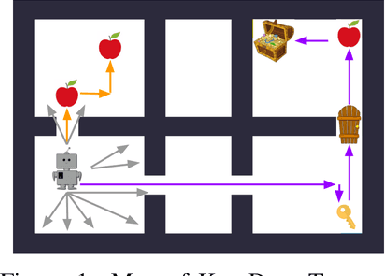
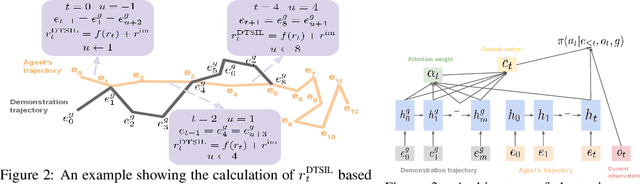
This paper proposes a method for learning a trajectory-conditioned policy to imitate diverse demonstrations from the agent's own past experiences. We demonstrate that such self-imitation drives exploration in diverse directions and increases the chance of finding a globally optimal solution in reinforcement learning problems, especially when the reward is sparse and deceptive. Our method significantly outperforms existing self-imitation learning and count-based exploration methods on various sparse-reward reinforcement learning tasks with local optima. In particular, we report a state-of-the-art score of more than 25,000 points on Montezuma's Revenge without using expert demonstrations or resetting to arbitrary states.
Data-Efficient Learning for Sim-to-Real Robotic Grasping using Deep Point Cloud Prediction Networks
Jun 21, 2019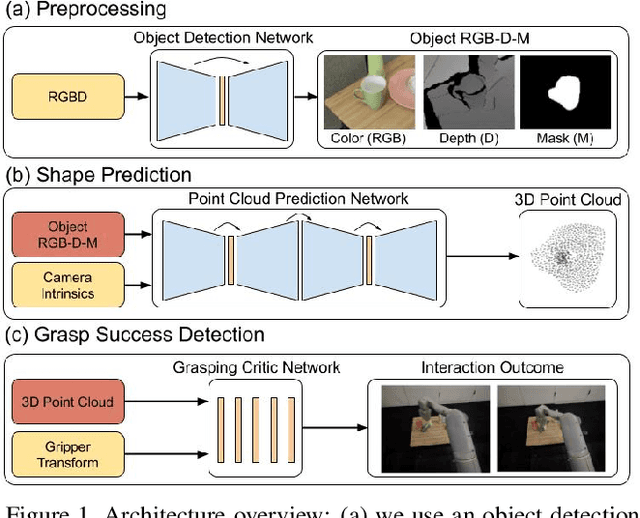
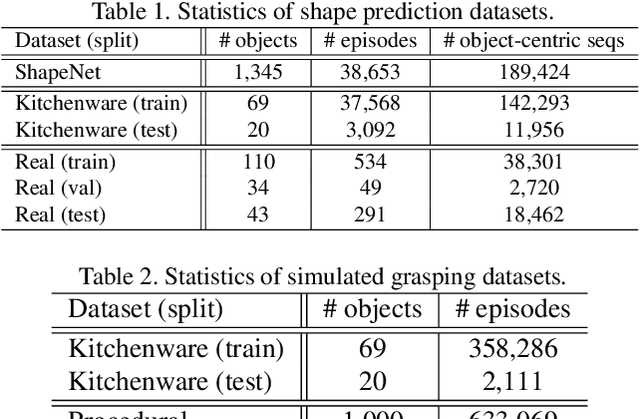
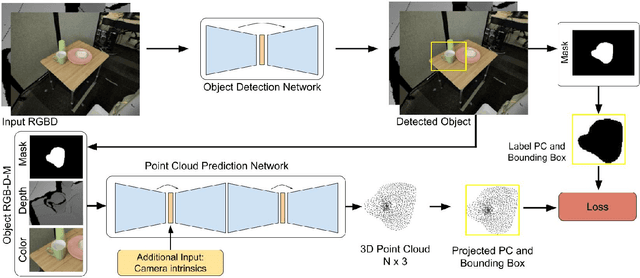
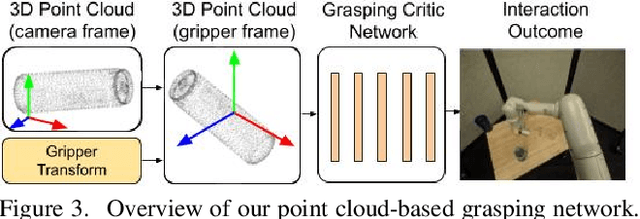
Training a deep network policy for robot manipulation is notoriously costly and time consuming as it depends on collecting a significant amount of real world data. To work well in the real world, the policy needs to see many instances of the task, including various object arrangements in the scene as well as variations in object geometry, texture, material, and environmental illumination. In this paper, we propose a method that learns to perform table-top instance grasping of a wide variety of objects while using no real world grasping data, outperforming the baseline using 2.5D shape by 10%. Our method learns 3D point cloud of object, and use that to train a domain-invariant grasping policy. We formulate the learning process as a two-step procedure: 1) Learning a domain-invariant 3D shape representation of objects from about 76K episodes in simulation and about 530 episodes in the real world, where each episode lasts less than a minute and 2) Learning a critic grasping policy in simulation only based on the 3D shape representation from step 1. Our real world data collection in step 1 is both cheaper and faster compared to existing approaches as it only requires taking multiple snapshots of the scene using a RGBD camera. Finally, the learned 3D representation is not specific to grasping, and can potentially be used in other interaction tasks.
SemanticAdv: Generating Adversarial Examples via Attribute-conditional Image Editing
Jun 19, 2019

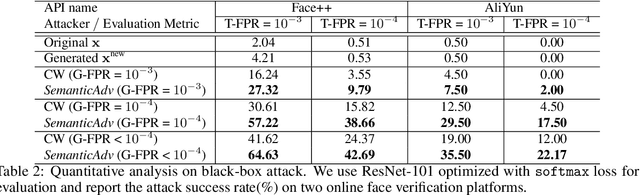
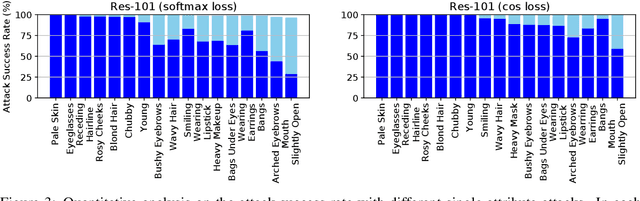
Deep neural networks (DNNs) have achieved great success in various applications due to their strong expressive power. However, recent studies have shown that DNNs are vulnerable to adversarial examples which are manipulated instances targeting to mislead DNNs to make incorrect predictions. Currently, most such adversarial examples try to guarantee "subtle perturbation" by limiting its $L_p$ norm. In this paper, we aim to explore the impact of semantic manipulation on DNNs predictions by manipulating the semantic attributes of images and generate "unrestricted adversarial examples". Such semantic based perturbation is more practical compared with pixel level manipulation. In particular, we propose an algorithm SemanticAdv which leverages disentangled semantic factors to generate adversarial perturbation via altering either single or a combination of semantic attributes. We conduct extensive experiments to show that the semantic based adversarial examples can not only fool different learning tasks such as face verification and landmark detection, but also achieve high attack success rate against real-world black-box services such as Azure face verification service. Such structured adversarial examples with controlled semantic manipulation can shed light on further understanding about vulnerabilities of DNNs as well as potential defensive approaches.
Unsupervised Learning of Object Structure and Dynamics from Videos
Jun 19, 2019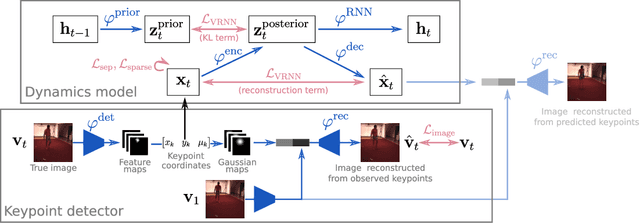
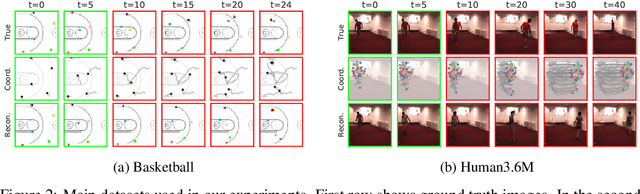
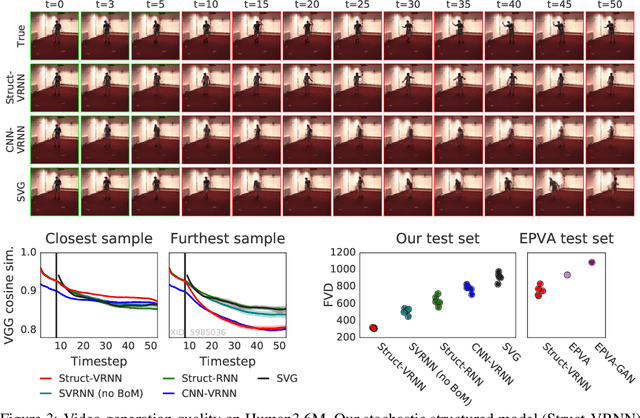
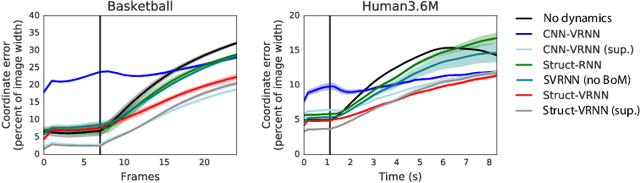
Extracting and predicting object structure and dynamics from videos without supervision is a major challenge in machine learning. To address this challenge, we adopt a keypoint-based image representation and learn a stochastic dynamics model of the keypoints. Future frames are reconstructed from the keypoints and a reference frame. By modeling dynamics in the keypoint coordinate space, we achieve stable learning and avoid compounding of errors in pixel space. Our method improves upon unstructured representations both for pixel-level video prediction and for downstream tasks requiring object-level understanding of motion dynamics. We evaluate our model on diverse datasets: a multi-agent sports dataset, the Human3.6M dataset, and datasets based on continuous control tasks from the DeepMind Control Suite. The spatially structured representation outperforms unstructured representations on a range of motion-related tasks such as object tracking, action recognition and reward prediction.
Zero-Shot Entity Linking by Reading Entity Descriptions
Jun 18, 2019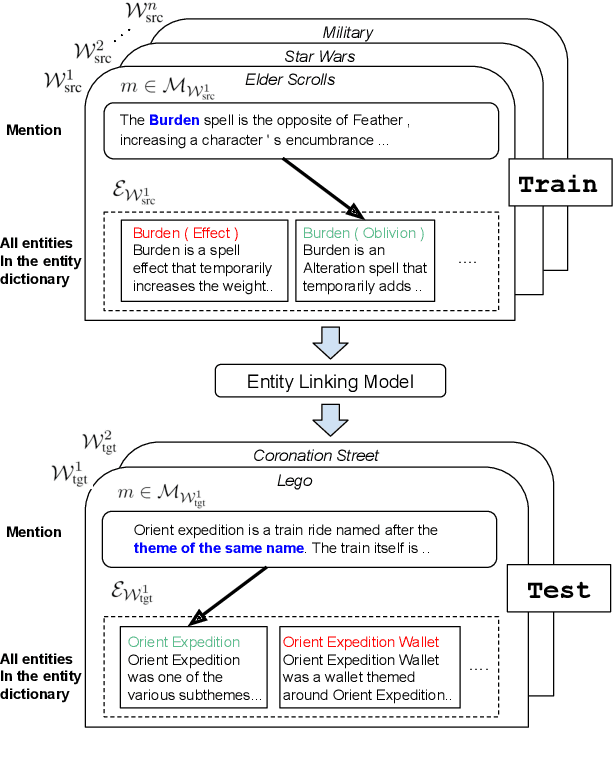

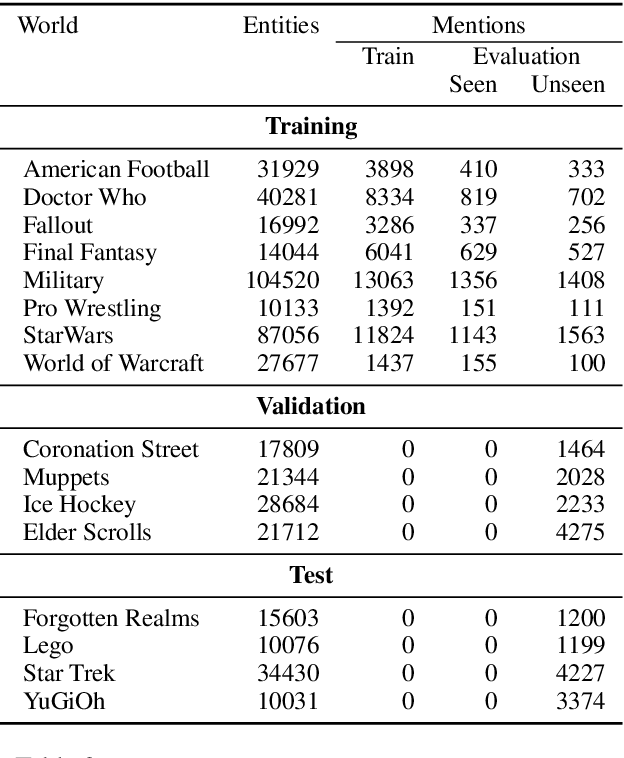
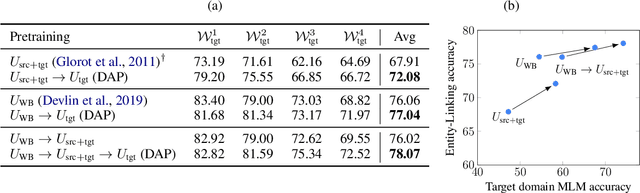
We present the zero-shot entity linking task, where mentions must be linked to unseen entities without in-domain labeled data. The goal is to enable robust transfer to highly specialized domains, and so no metadata or alias tables are assumed. In this setting, entities are only identified by text descriptions, and models must rely strictly on language understanding to resolve the new entities. First, we show that strong reading comprehension models pre-trained on large unlabeled data can be used to generalize to unseen entities. Second, we propose a simple and effective adaptive pre-training strategy, which we term domain-adaptive pre-training (DAP), to address the domain shift problem associated with linking unseen entities in a new domain. We present experiments on a new dataset that we construct for this task and show that DAP improves over strong pre-training baselines, including BERT. The data and code are available at https://github.com/lajanugen/zeshel.
Similarity of Neural Network Representations Revisited
May 14, 2019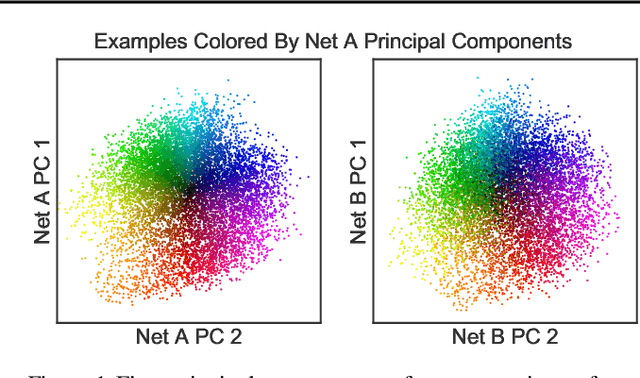

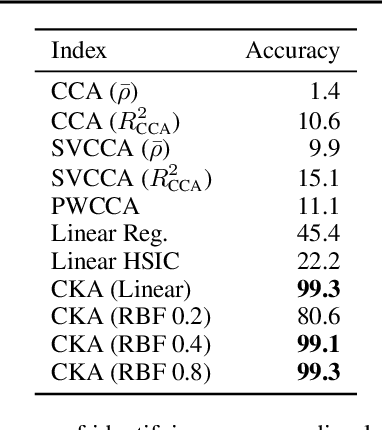
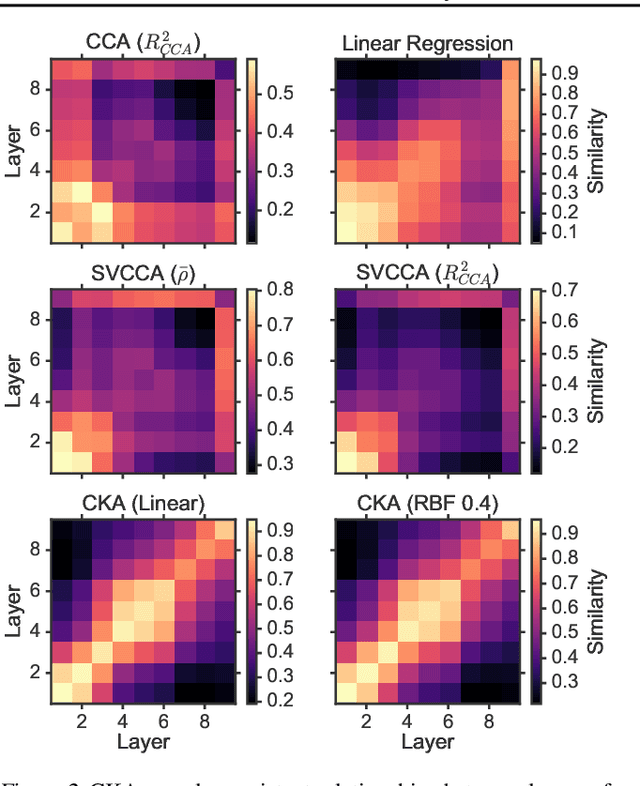
Recent work has sought to understand the behavior of neural networks by comparing representations between layers and between different trained models. We examine methods for comparing neural network representations based on canonical correlation analysis (CCA). We show that CCA belongs to a family of statistics for measuring multivariate similarity, but that neither CCA nor any other statistic that is invariant to invertible linear transformation can measure meaningful similarities between representations of higher dimension than the number of data points. We introduce a similarity index that measures the relationship between representational similarity matrices and does not suffer from this limitation. This similarity index is equivalent to centered kernel alignment (CKA) and is also closely connected to CCA. Unlike CCA, CKA can reliably identify correspondences between representations in networks trained from different initializations.
Incremental Learning with Unlabeled Data in the Wild
Mar 29, 2019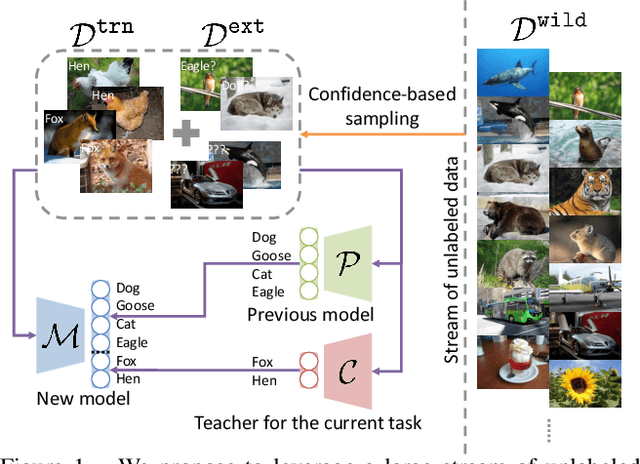
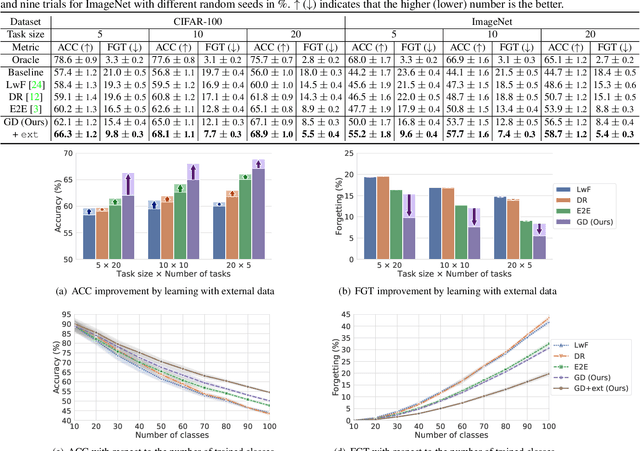


Deep neural networks are known to suffer from catastrophic forgetting in class-incremental learning, where the performance on previous tasks drastically degrades when learning a new task. To alleviate this effect, we propose to leverage a continuous and large stream of unlabeled data in the wild. In particular, to leverage such transient external data effectively, we design a novel class-incremental learning scheme with (a) a new distillation loss, termed global distillation, (b) a learning strategy to avoid overfitting to the most recent task, and (c) a sampling strategy for the desired external data. Our experimental results on various datasets, including CIFAR and ImageNet, demonstrate the superiority of the proposed methods over prior methods, particularly when a stream of unlabeled data is accessible: we achieve up to 9.3% of relative performance improvement compared to the state-of-the-art method.
Robust Inference via Generative Classifiers for Handling Noisy Labels
Jan 31, 2019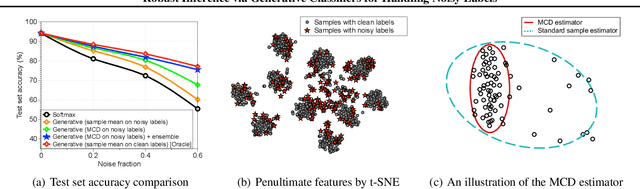
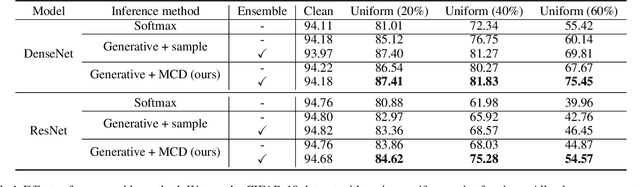
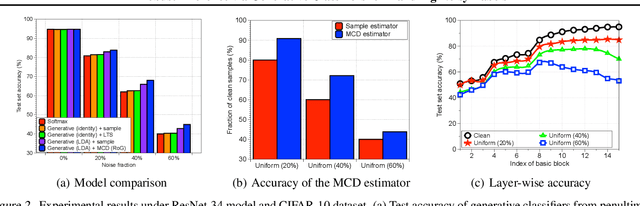
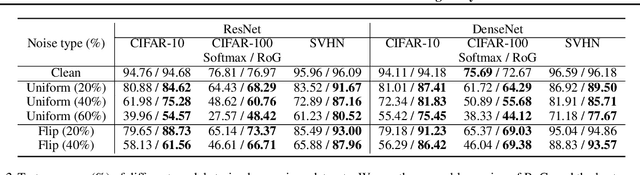
Large-scale datasets may contain significant proportions of noisy (incorrect) class labels, and it is well-known that modern deep neural networks (DNNs) poorly generalize from such noisy training datasets. To mitigate the issue, we propose a novel inference method, termed Robust Generative classifier (RoG), applicable to any discriminative (e.g., softmax) neural classifier pre-trained on noisy datasets. In particular, we induce a generative classifier on top of hidden feature spaces of the pre-trained DNNs, for obtaining a more robust decision boundary. By estimating the parameters of generative classifier using the minimum covariance determinant estimator, we significantly improve the classification accuracy with neither re-training of the deep model nor changing its architectures. With the assumption of Gaussian distribution for features, we prove that RoG generalizes better than baselines under noisy labels. Finally, we propose the ensemble version of RoG to improve its performance by investigating the layer-wise characteristics of DNNs. Our extensive experimental results demonstrate the superiority of RoG given different learning models optimized by several training techniques to handle diverse scenarios of noisy labels.
Diversity-Sensitive Conditional Generative Adversarial Networks
Jan 25, 2019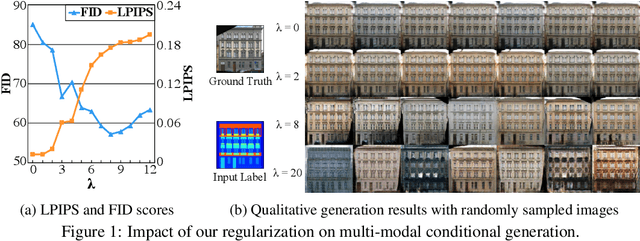
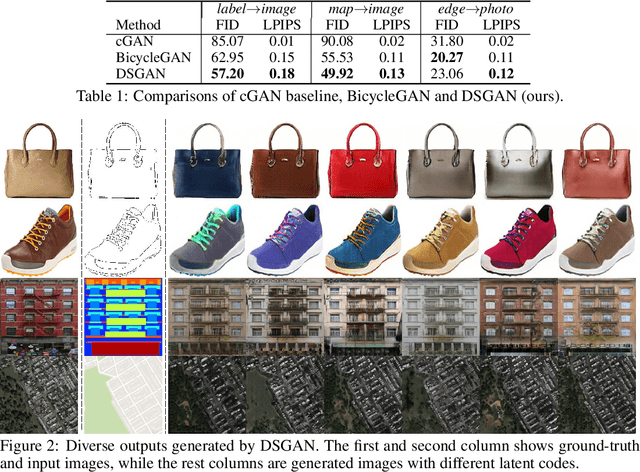
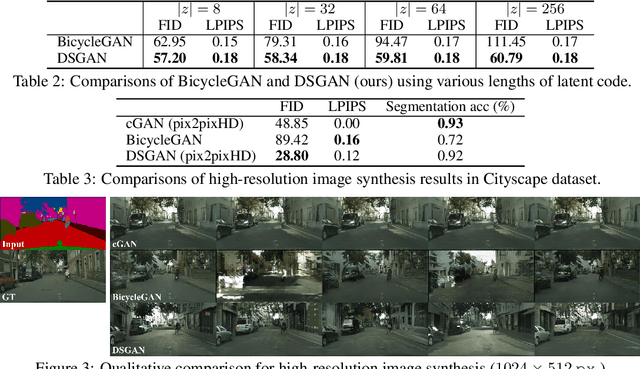

We propose a simple yet highly effective method that addresses the mode-collapse problem in the Conditional Generative Adversarial Network (cGAN). Although conditional distributions are multi-modal (i.e., having many modes) in practice, most cGAN approaches tend to learn an overly simplified distribution where an input is always mapped to a single output regardless of variations in latent code. To address such issue, we propose to explicitly regularize the generator to produce diverse outputs depending on latent codes. The proposed regularization is simple, general, and can be easily integrated into most conditional GAN objectives. Additionally, explicit regularization on generator allows our method to control a balance between visual quality and diversity. We demonstrate the effectiveness of our method on three conditional generation tasks: image-to-image translation, image inpainting, and future video prediction. We show that simple addition of our regularization to existing models leads to surprisingly diverse generations, substantially outperforming the previous approaches for multi-modal conditional generation specifically designed in each individual task.