 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkyNet: a Hardware-Efficient Method for Object Detection and Tracking on Embedded Systems
Sep 20, 2019

Developing object detection and tracking on resource-constrained embedded systems is challenging. While object detection is one of the most compute-intensive tasks from the artificial intelligence domain, it is only allowed to use limited computation and memory resources on embedded devices. In the meanwhile, such resource-constrained implementations are often required to satisfy additional demanding requirements such as real-time response, high-throughput performance, and reliable inference accuracy. To overcome these challenges, we propose SkyNet, a hardware-efficient method to deliver the state-of-the-art detection accuracy and speed for embedded systems. Instead of following the common top-down flow for compact DNN design, SkyNet provides a bottom-up DNN design approach with comprehensive understanding of the hardware constraints at the very beginning to deliver hardware-efficient DNNs. The effectiveness of SkyNet is demonstrated by winning the extremely competitive System Design Contest for low power object detection in the 56th IEEE/ACM Design Automation Conference (DAC-SDC), where our SkyNet significantly outperforms all other 100+ competitors: it delivers 0.731 Intersection over Union (IoU) and 67.33 frames per second (FPS) on a TX2 embedded GPU; and 0.716 IoU and 25.05 FPS on an Ultra96 embedded FPGA. The evaluation of SkyNet is also extended to GOT-10K, a recent large-scale high-diversity benchmark for generic object tracking in the wild. For state-of-the-art object trackers SiamRPN++ and SiamMask, where ResNet-50 is employed as the backbone, implementations using our SkyNet as the backbone DNN are 1.60X and 1.73X faster with better or similar accuracy when running on a 1080Ti GPU, and 37.20X smaller in terms of parameter size for significantly better memory and storage footprint.
Bottom-up Higher-Resolution Networks for Multi-Person Pose Estimation
Aug 27, 2019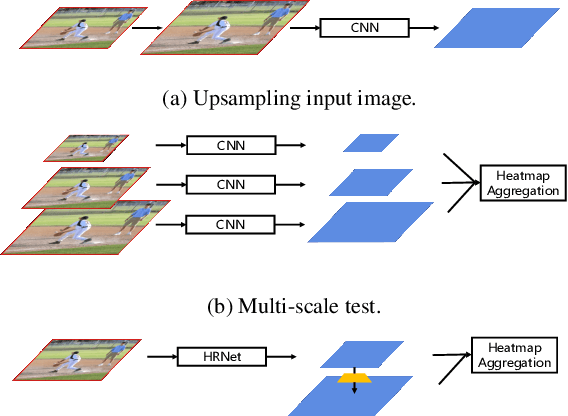
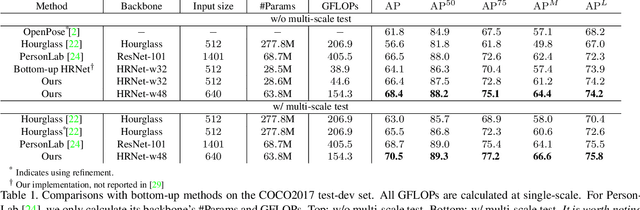
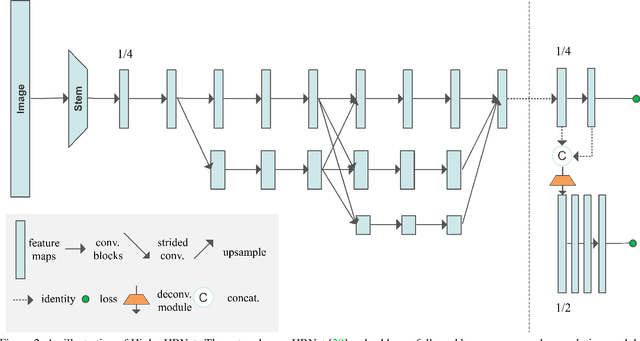
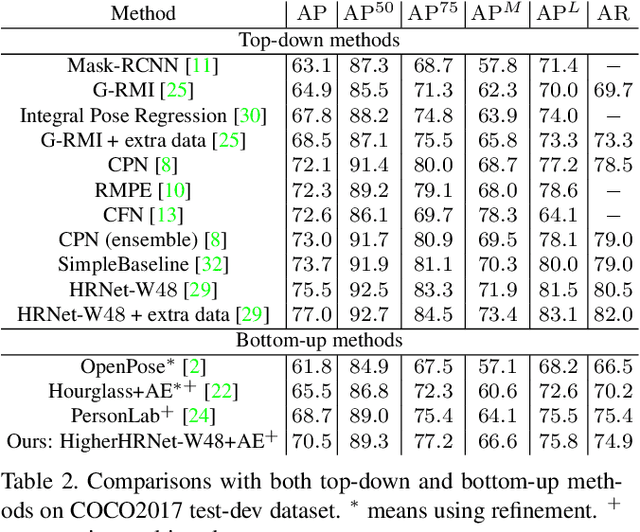
In this paper, we are interested in bottom-up multi-person human pose estimation. A typical bottom-up pipeline consists of two main steps: heatmap prediction and keypoint grouping. We mainly focus on the first step for improving heatmap prediction accuracy. We propose Higher-Resolution Network (HigherHRNet), which is a simple extension of the High-Resolution Network (HRNet). HigherHRNet generates higher-resolution feature maps by deconvolving the high-resolution feature maps outputted by HRNet, which are spatially more accurate for small and medium persons. Then, we build high-quality multi-level features and perform multi-scale pose prediction. The extra computation overhead is marginal and negligible in comparison to existing bottom-up methods that rely on multi-scale image pyramids or large input image size to generate accurate pose heatmaps. HigherHRNet surpasses all existing bottom-up methods on the COCO dataset without using multi-scale test. The code and models will be released.
SPGNet: Semantic Prediction Guidance for Scene Parsing
Aug 26, 2019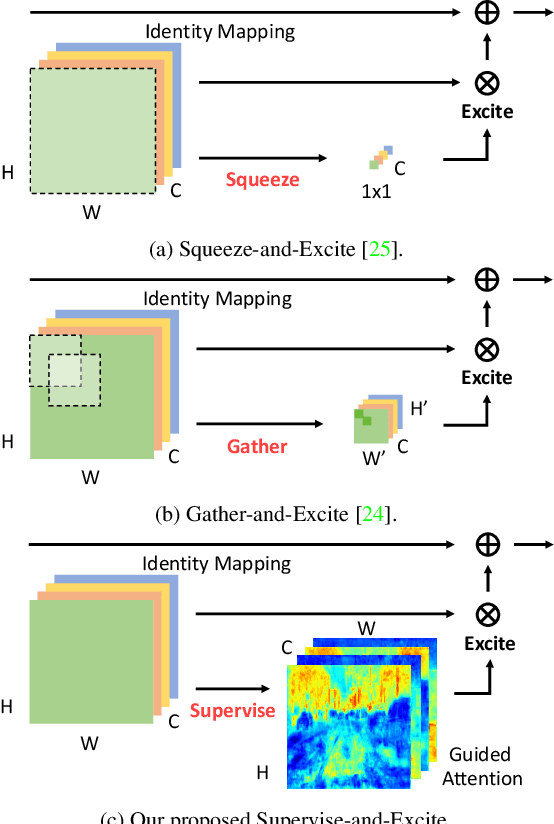
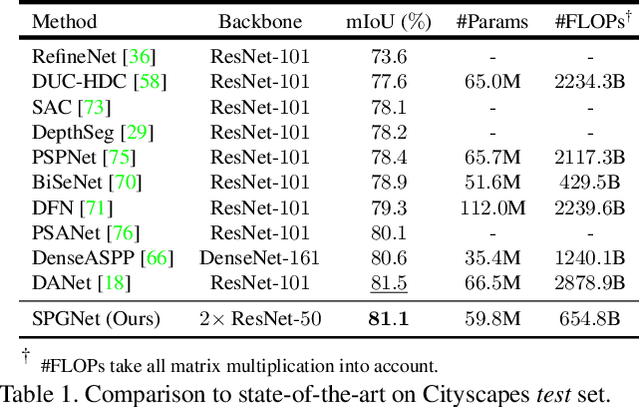
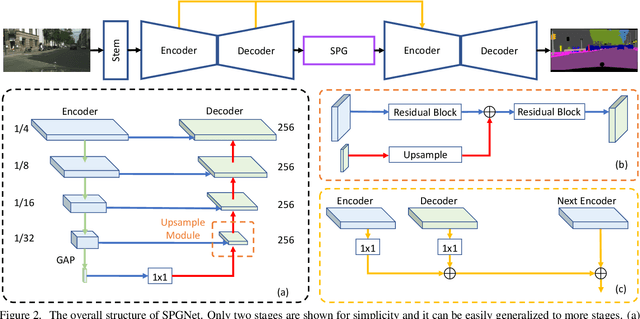

Multi-scale context module and single-stage encoder-decoder structure are commonly employed for semantic segmentation. The multi-scale context module refers to the operations to aggregate feature responses from a large spatial extent, while the single-stage encoder-decoder structure encodes the high-level semantic information in the encoder path and recovers the boundary information in the decoder path. In contrast, multi-stage encoder-decoder networks have been widely used in human pose estimation and show superior performance than their single-stage counterpart. However, few efforts have been attempted to bring this effective design to semantic segmentation. In this work, we propose a Semantic Prediction Guidance (SPG) module which learns to re-weight the local features through the guidance from pixel-wise semantic prediction. We find that by carefully re-weighting features across stages, a two-stage encoder-decoder network coupled with our proposed SPG module can significantly outperform its one-stage counterpart with similar parameters and computations. Finally, we report experimental results on the semantic segmentation benchmark Cityscapes, in which our SPGNet attains 81.1% on the test set using only 'fine' annotations.
SkyNet: A Champion Model for DAC-SDC on Low Power Object Detection
Jul 09, 2019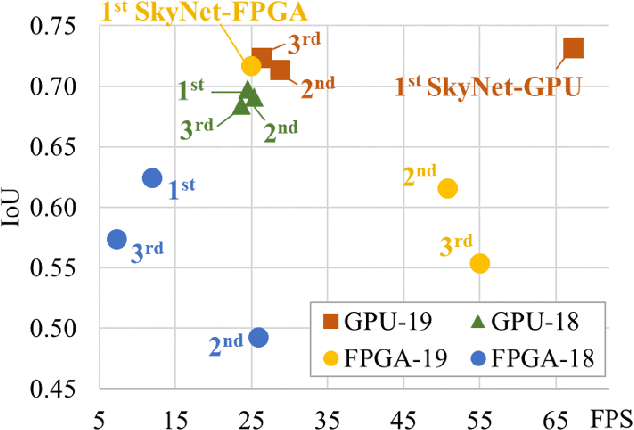
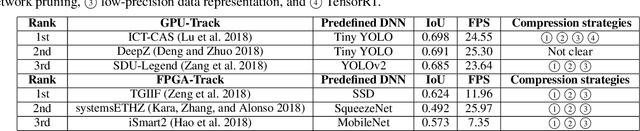

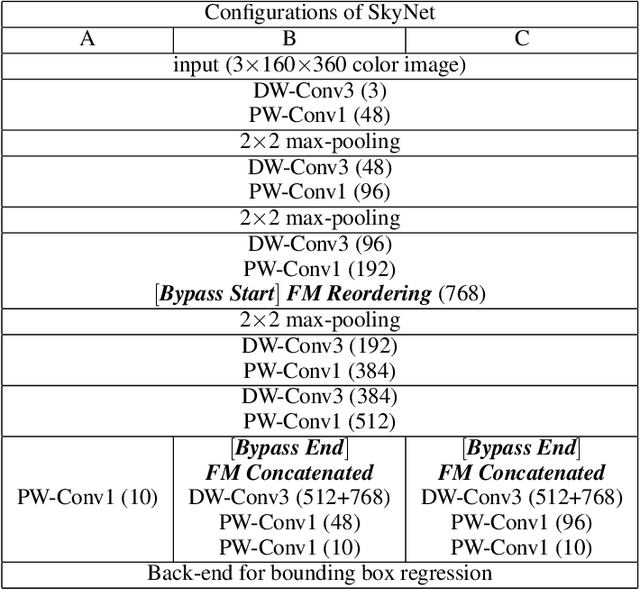
Developing artificial intelligence (AI) at the edge is always challenging, since edge devices have limited computation capability and memory resources but need to meet demanding requirements, such as real-time processing, high throughput performance, and high inference accuracy. To overcome these challenges, we propose SkyNet, an extremely lightweight DNN with 12 convolutional (Conv) layers and only 1.82 megabyte (MB) of parameters following a bottom-up DNN design approach. SkyNet is demonstrated in the 56th IEEE/ACM Design Automation Conference System Design Contest (DAC-SDC), a low power object detection challenge in images captured by unmanned aerial vehicles (UAVs). SkyNet won the first place award for both the GPU and FPGA tracks of the contest: we deliver 0.731 Intersection over Union (IoU) and 67.33 frames per second (FPS) on a TX2 GPU and deliver 0.716 IoU and 25.05 FPS on an Ultra96 FPGA.
When AWGN-based Denoiser Meets Real Noises
Apr 06, 2019
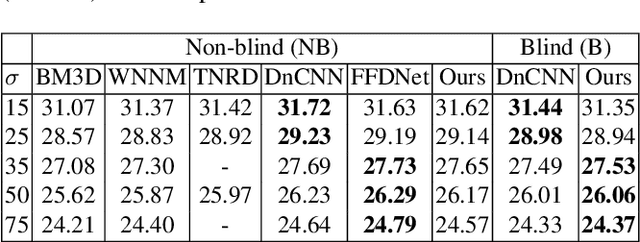

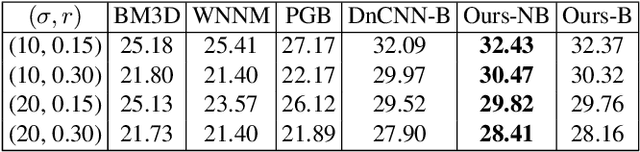
Discriminative learning based image denoisers have achieved promising performance on synthetic noise such as the additive Gaussian noise. However, their performance on images with real noise is often not satisfactory. The main reason is that real noises are mostly spatially/channel-correlated and spatial/channel-variant. In contrast, the synthetic Additive White Gaussian Noise (AWGN) adopted in most previous work is pixel-independent. In this paper, we propose a novel approach to boost the performance of a real image denoiser which is trained only with synthetic pixel-independent noise data. First, we train a deep model that consists of a noise estimator and a denoiser with mixed AWGN and Random Value Impulse Noise (RVIN). We then investigate Pixel-shuffle Down-sampling (PD) strategy to adapt the trained model to real noises. Extensive experiments demonstrate the effectiveness and generalization ability of the proposed approach. Notably, our method achieves state-of-the-art performance on real sRGB images in the DND benchmark. Codes are available at https://github.com/yzhouas/PD-Denoising-pytorch.
One Shot Domain Adaptation for Person Re-Identification
Nov 26, 2018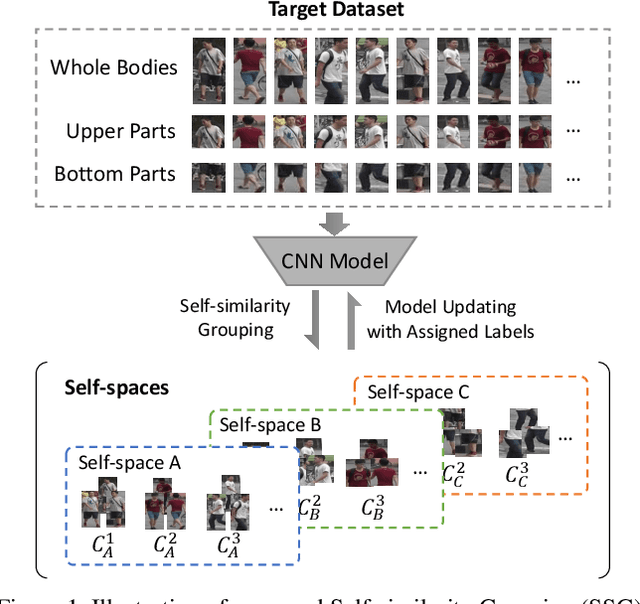
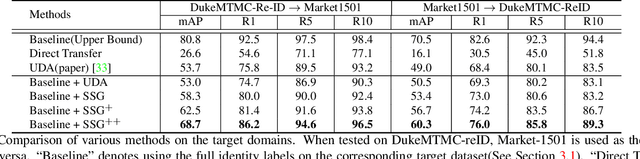
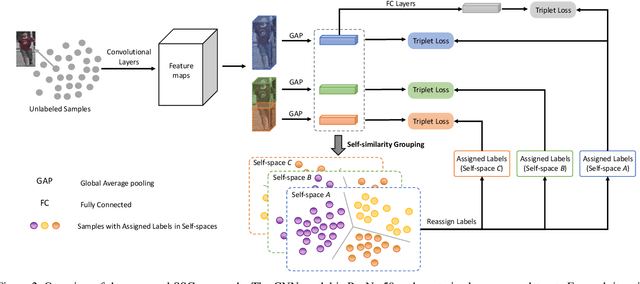
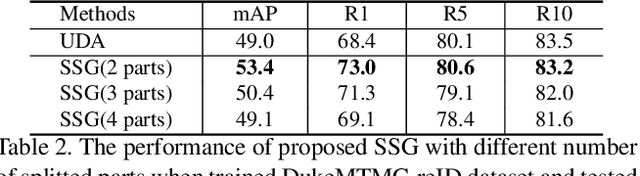
How to effectively address the domain adaptation problem is a challenging task for person re-identification (reID). In this work, we make the first endeavour to tackle this issue according to one shot learning. Given an annotated source training set and a target training set that only one instance for each category is annotated, we aim to achieve competitive re-ID performance on the testing set of the target domain. To this end, we introduce a similarity-guided strategy to progressively assign pseudo labels to unlabeled instances with different confidence scores, which are in turn leveraged as weights to guide the optimization as training goes on. Collaborating with a simple self-mining operation, we make significant improvement in the domain adaptation tasks of re-ID. In particular, we achieve the mAP of 71.5% in the adaptation task of DukeMTMC-reID to Market1501 with one shot setting, which outperforms the state-of-arts of unsupervised domain adaptation more than 17.8%. Under the five shots setting, we achieve competitive accuracy of the fully supervised setting on Market-1501. Code will be made available.
Revisiting Pre-training: An Efficient Training Method for Image Classification
Nov 23, 2018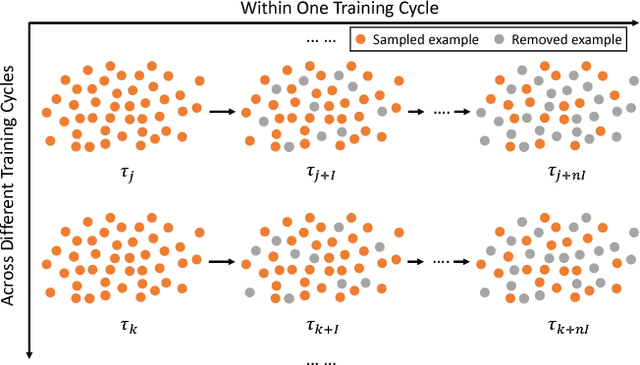

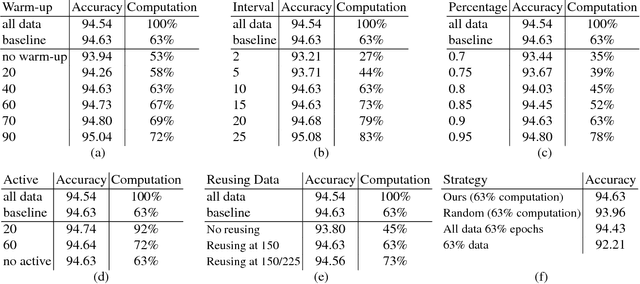

The training method of repetitively feeding all samples into a pre-defined network for image classification has been widely adopted by current state-of-the-art. In this work, we provide a new method, which can be leveraged to train classification networks in a more efficient way. Starting with a warm-up step, we propose to continually repeat a Drop-and-Pick (DaP) learning strategy. In particular, we drop those easy samples to encourage the network to focus on studying hard ones. Meanwhile, by picking up all samples periodically during training, we aim to recall the memory of the networks to prevent catastrophic forgetting of previously learned knowledge. Our DaP learning method can recover 99.88%, 99.60%, 99.83% top-1 accuracy on ImageNet for ResNet-50, DenseNet-121, and MobileNet-V1 but only requires 75% computation in training compared to those using the classic training schedule. Furthermore, our pre-trained models are equipped with strong knowledge transferability when used for downstream tasks, especially for hard cases. Extensive experiments on object detection, instance segmentation and pose estimation can well demonstrate the effectiveness of our DaP training method.
SpotTune: Transfer Learning through Adaptive Fine-tuning
Nov 21, 2018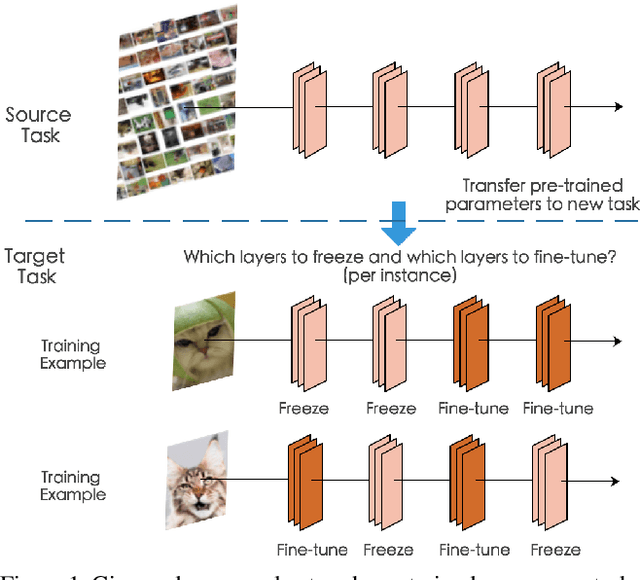
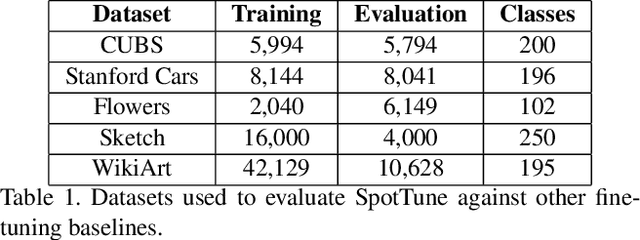
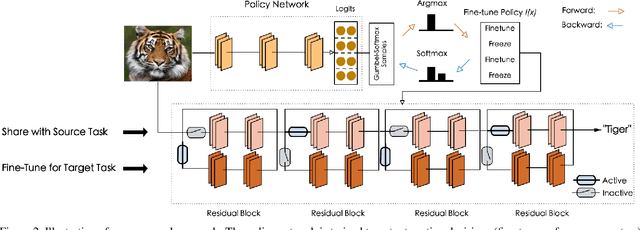
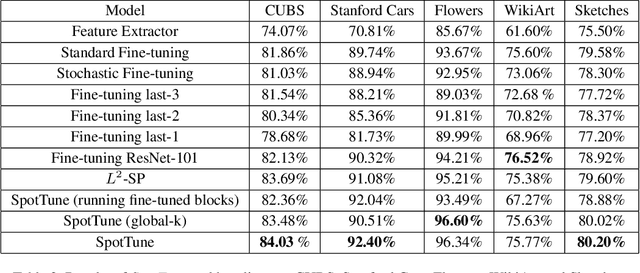
Transfer learning, which allows a source task to affect the inductive bias of the target task, is widely used in computer vision. The typical way of conducting transfer learning with deep neural networks is to fine-tune a model pre-trained on the source task using data from the target task. In this paper, we propose an adaptive fine-tuning approach, called SpotTune, which finds the optimal fine-tuning strategy per instance for the target data. In SpotTune, given an image from the target task, a policy network is used to make routing decisions on whether to pass the image through the fine-tuned layers or the pre-trained layers. We conduct extensive experiments to demonstrate the effectiveness of the proposed approach. Our method outperforms the traditional fine-tuning approach on 12 out of 14 standard datasets.We also compare SpotTune with other state-of-the-art fine-tuning strategies, showing superior performance. On the Visual Decathlon datasets, our method achieves the highest score across the board without bells and whistles.
Weakly Supervised Scene Parsing with Point-based Distance Metric Learning
Nov 06, 2018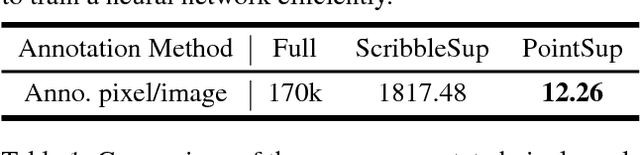

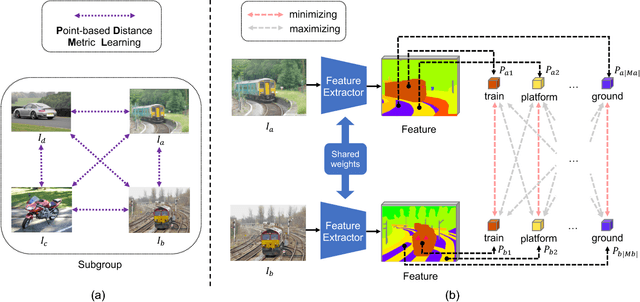
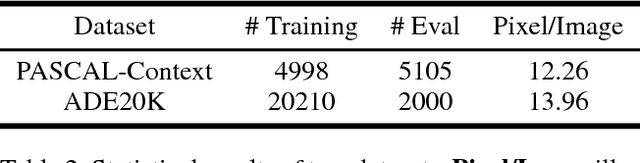
Semantic scene parsing is suffering from the fact that pixel-level annotations are hard to be collected. To tackle this issue, we propose a Point-based Distance Metric Learning (PDML) in this paper. PDML does not require dense annotated masks and only leverages several labeled points that are much easier to obtain to guide the training process. Concretely, we leverage semantic relationship among the annotated points by encouraging the feature representations of the intra- and inter-category points to keep consistent, i.e. points within the same category should have more similar feature representations compared to those from different categories. We formulate such a characteristic into a simple distance metric loss, which collaborates with the point-wise cross-entropy loss to optimize the deep neural networks. Furthermore, to fully exploit the limited annotations, distance metric learning is conducted across different training images instead of simply adopting an image-dependent manner. We conduct extensive experiments on two challenging scene parsing benchmarks of PASCAL-Context and ADE 20K to validate the effectiveness of our PDML, and competitive mIoU scores are achieved.
Horizontal Pyramid Matching for Person Re-identification
Sep 20, 2018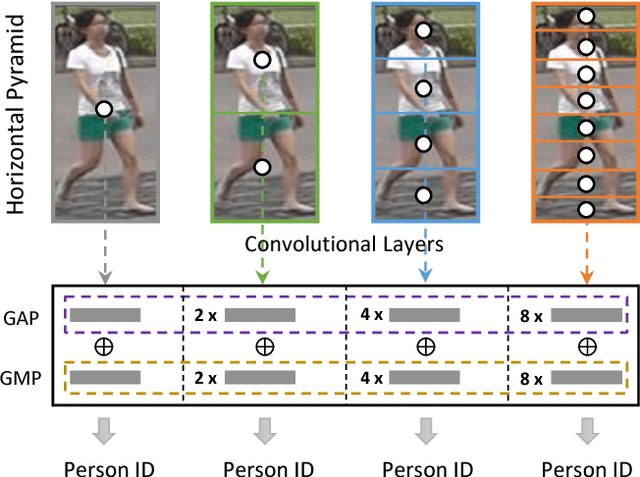
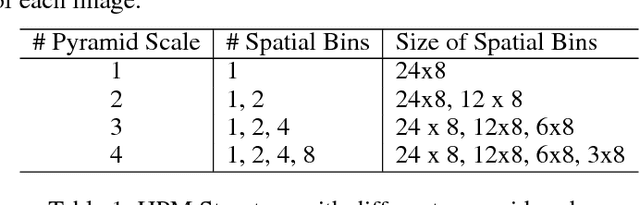

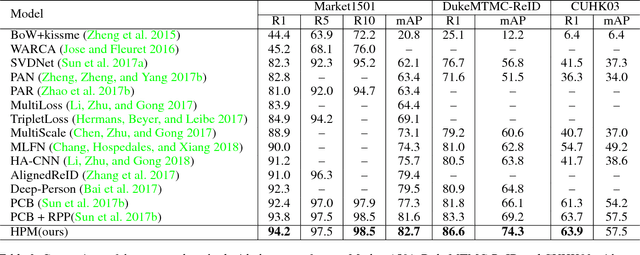
Despite the remarkable recent progress, person Re-identification (Re-ID) approaches are still suffering from the failure cases where the discriminative body parts are missing. To mitigate such cases, we propose a simple yet effective Horizontal Pyramid Matching (HPM) approach to fully exploit various partial information of a given person, so that correct person candidates can be still identified even if some key parts are missing. Within the HPM, we make the following contributions to produce a more robust feature representation for the Re-ID task: 1) we learn to classify using partial feature representations at different horizontal pyramid scales, which successfully enhance the discriminative capabilities of various person parts; 2) we exploit average and max pooling strategies to account for person-specific discriminative information in a global-local manner; 3) we introduce a novel horizontal erasing operation during training to further resist the problem of missing parts and boost the robustness of feature representations. Extensive experiments are conducted on three popular benchmarks including Market-1501, DukeMTMC-reID and CUHK03. We achieve mAP scores of 83.1%, 74.5% and 59.7% on these benchmarks, which are the new state-of-the-arts.