 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH$_{2}$OT: Hierarchical Hourglass Tokenizer for Efficient Video Pose Transformers
Sep 08, 2025



Transformers have been successfully applied in the field of video-based 3D human pose estimation. However, the high computational costs of these video pose transformers (VPTs) make them impractical on resource-constrained devices. In this paper, we present a hierarchical plug-and-play pruning-and-recovering framework, called Hierarchical Hourglass Tokenizer (H$_{2}$OT), for efficient transformer-based 3D human pose estimation from videos. H$_{2}$OT begins with progressively pruning pose tokens of redundant frames and ends with recovering full-length sequences, resulting in a few pose tokens in the intermediate transformer blocks and thus improving the model efficiency. It works with two key modules, namely, a Token Pruning Module (TPM) and a Token Recovering Module (TRM). TPM dynamically selects a few representative tokens to eliminate the redundancy of video frames, while TRM restores the detailed spatio-temporal information based on the selected tokens, thereby expanding the network output to the original full-length temporal resolution for fast inference. Our method is general-purpose: it can be easily incorporated into common VPT models on both seq2seq and seq2frame pipelines while effectively accommodating different token pruning and recovery strategies. In addition, our H$_{2}$OT reveals that maintaining the full pose sequence is unnecessary, and a few pose tokens of representative frames can achieve both high efficiency and estimation accuracy. Extensive experiments on multiple benchmark datasets demonstrate both the effectiveness and efficiency of the proposed method. Code and models are available at https://github.com/NationalGAILab/HoT.
UST-SSM: Unified Spatio-Temporal State Space Models for Point Cloud Video Modeling
Aug 20, 2025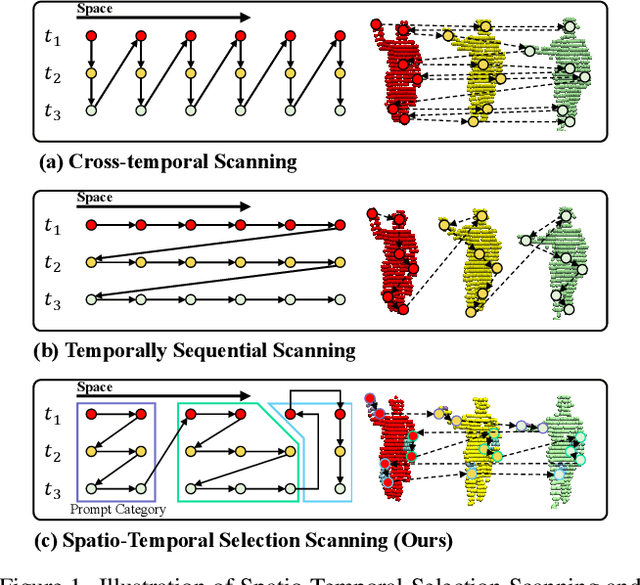
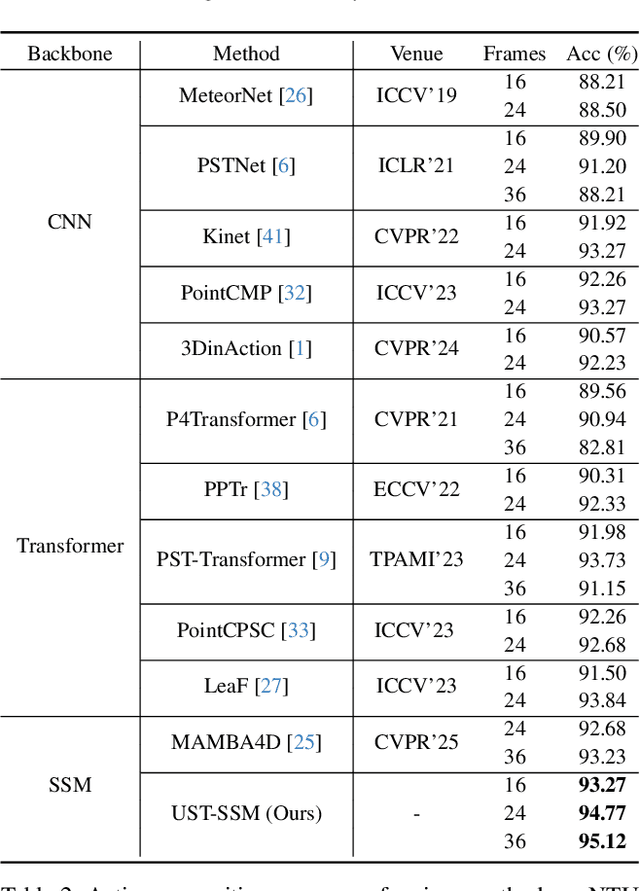
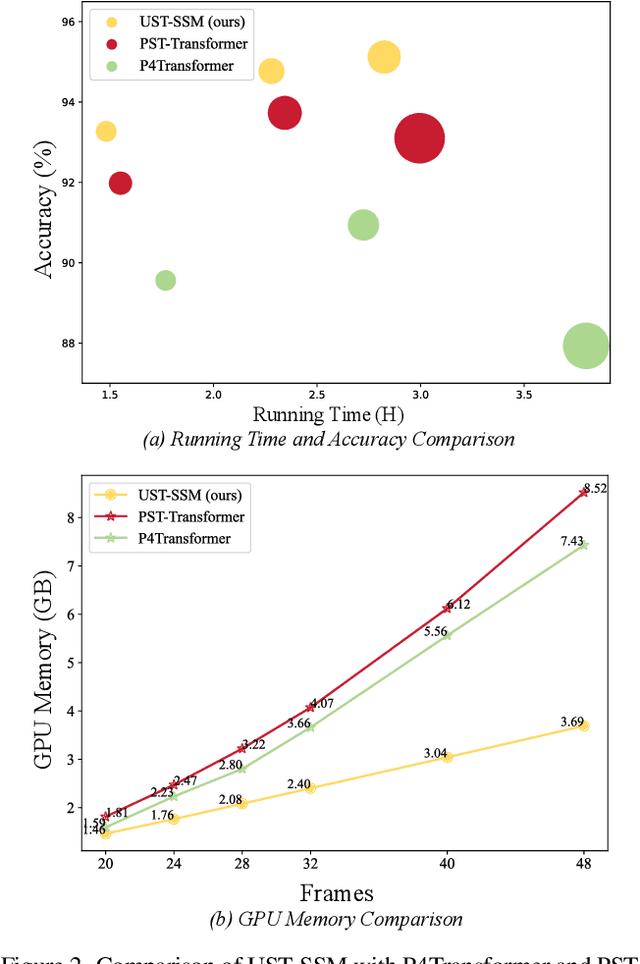
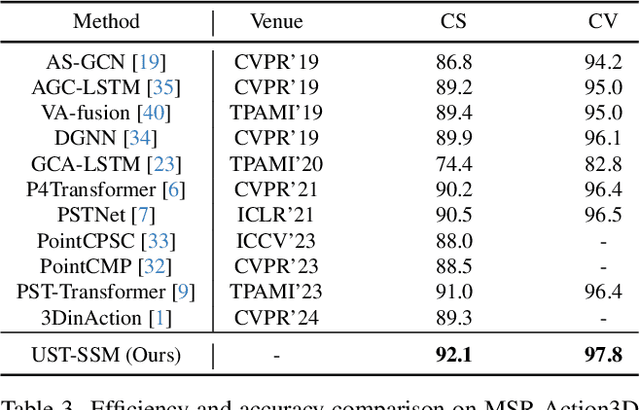
Point cloud videos capture dynamic 3D motion while reducing the effects of lighting and viewpoint variations, making them highly effective for recognizing subtle and continuous human actions. Although Selective State Space Models (SSMs) have shown good performance in sequence modeling with linear complexity, the spatio-temporal disorder of point cloud videos hinders their unidirectional modeling when directly unfolding the point cloud video into a 1D sequence through temporally sequential scanning. To address this challenge, we propose the Unified Spatio-Temporal State Space Model (UST-SSM), which extends the latest advancements in SSMs to point cloud videos. Specifically, we introduce Spatial-Temporal Selection Scanning (STSS), which reorganizes unordered points into semantic-aware sequences through prompt-guided clustering, thereby enabling the effective utilization of points that are spatially and temporally distant yet similar within the sequence. For missing 4D geometric and motion details, Spatio-Temporal Structure Aggregation (STSA) aggregates spatio-temporal features and compensates. To improve temporal interaction within the sampled sequence, Temporal Interaction Sampling (TIS) enhances fine-grained temporal dependencies through non-anchor frame utilization and expanded receptive fields. Experimental results on the MSR-Action3D, NTU RGB+D, and Synthia 4D datasets validate the effectiveness of our method. Our code is available at https://github.com/wangzy01/UST-SSM.
Masked Clustering Prediction for Unsupervised Point Cloud Pre-training
Aug 12, 2025



Vision transformers (ViTs) have recently been widely applied to 3D point cloud understanding, with masked autoencoding as the predominant pre-training paradigm. However, the challenge of learning dense and informative semantic features from point clouds via standard ViTs remains underexplored. We propose MaskClu, a novel unsupervised pre-training method for ViTs on 3D point clouds that integrates masked point modeling with clustering-based learning. MaskClu is designed to reconstruct both cluster assignments and cluster centers from masked point clouds, thus encouraging the model to capture dense semantic information. Additionally, we introduce a global contrastive learning mechanism that enhances instance-level feature learning by contrasting different masked views of the same point cloud. By jointly optimizing these complementary objectives, i.e., dense semantic reconstruction, and instance-level contrastive learning. MaskClu enables ViTs to learn richer and more semantically meaningful representations from 3D point clouds. We validate the effectiveness of our method via multiple 3D tasks, including part segmentation, semantic segmentation, object detection, and classification, where MaskClu sets new competitive results. The code and models will be released at:https://github.com/Amazingren/maskclu.
Recognizing Actions from Robotic View for Natural Human-Robot Interaction
Jul 30, 2025



Natural Human-Robot Interaction (N-HRI) requires robots to recognize human actions at varying distances and states, regardless of whether the robot itself is in motion or stationary. This setup is more flexible and practical than conventional human action recognition tasks. However, existing benchmarks designed for traditional action recognition fail to address the unique complexities in N-HRI due to limited data, modalities, task categories, and diversity of subjects and environments. To address these challenges, we introduce ACTIVE (Action from Robotic View), a large-scale dataset tailored specifically for perception-centric robotic views prevalent in mobile service robots. ACTIVE comprises 30 composite action categories, 80 participants, and 46,868 annotated video instances, covering both RGB and point cloud modalities. Participants performed various human actions in diverse environments at distances ranging from 3m to 50m, while the camera platform was also mobile, simulating real-world scenarios of robot perception with varying camera heights due to uneven ground. This comprehensive and challenging benchmark aims to advance action and attribute recognition research in N-HRI. Furthermore, we propose ACTIVE-PC, a method that accurately perceives human actions at long distances using Multilevel Neighborhood Sampling, Layered Recognizers, Elastic Ellipse Query, and precise decoupling of kinematic interference from human actions. Experimental results demonstrate the effectiveness of ACTIVE-PC. Our code is available at: https://github.com/wangzy01/ACTIVE-Action-from-Robotic-View.
QuMAB: Query-based Multi-annotator Behavior Pattern Learning
Jul 23, 2025Multi-annotator learning traditionally aggregates diverse annotations to approximate a single ground truth, treating disagreements as noise. However, this paradigm faces fundamental challenges: subjective tasks often lack absolute ground truth, and sparse annotation coverage makes aggregation statistically unreliable. We introduce a paradigm shift from sample-wise aggregation to annotator-wise behavior modeling. By treating annotator disagreements as valuable information rather than noise, modeling annotator-specific behavior patterns can reconstruct unlabeled data to reduce annotation cost, enhance aggregation reliability, and explain annotator decision behavior. To this end, we propose QuMATL (Query-based Multi-Annotator Behavior Pattern Learning), which uses light-weight queries to model individual annotators while capturing inter-annotator correlations as implicit regularization, preventing overfitting to sparse individual data while maintaining individualization and improving generalization, with a visualization of annotator focus regions offering an explainable analysis of behavior understanding. We contribute two large-scale datasets with dense per-annotator labels: STREET (4,300 labels/annotator) and AMER (average 3,118 labels/annotator), the first multimodal multi-annotator dataset.
DCIRNet: Depth Completion with Iterative Refinement for Dexterous Grasping of Transparent and Reflective Objects
Jun 11, 2025Transparent and reflective objects in everyday environments pose significant challenges for depth sensors due to their unique visual properties, such as specular reflections and light transmission. These characteristics often lead to incomplete or inaccurate depth estimation, which severely impacts downstream geometry-based vision tasks, including object recognition, scene reconstruction, and robotic manipulation. To address the issue of missing depth information in transparent and reflective objects, we propose DCIRNet, a novel multimodal depth completion network that effectively integrates RGB images and depth maps to enhance depth estimation quality. Our approach incorporates an innovative multimodal feature fusion module designed to extract complementary information between RGB images and incomplete depth maps. Furthermore, we introduce a multi-stage supervision and depth refinement strategy that progressively improves depth completion and effectively mitigates the issue of blurred object boundaries. We integrate our depth completion model into dexterous grasping frameworks and achieve a $44\%$ improvement in the grasp success rate for transparent and reflective objects. We conduct extensive experiments on public datasets, where DCIRNet demonstrates superior performance. The experimental results validate the effectiveness of our approach and confirm its strong generalization capability across various transparent and reflective objects.
HTMNet: A Hybrid Network with Transformer-Mamba Bottleneck Multimodal Fusion for Transparent and Reflective Objects Depth Completion
May 28, 2025Transparent and reflective objects pose significant challenges for depth sensors, resulting in incomplete depth information that adversely affects downstream robotic perception and manipulation tasks. To address this issue, we propose HTMNet, a novel hybrid model integrating Transformer, CNN, and Mamba architectures. The encoder is based on a dual-branch CNN-Transformer framework, the bottleneck fusion module adopts a Transformer-Mamba architecture, and the decoder is built upon a multi-scale fusion module. We introduce a novel multimodal fusion module grounded in self-attention mechanisms and state space models, marking the first application of the Mamba architecture in the field of transparent object depth completion and revealing its promising potential. Additionally, we design an innovative multi-scale fusion module for the decoder that combines channel attention, spatial attention, and multi-scale feature extraction techniques to effectively integrate multi-scale features through a down-fusion strategy. Extensive evaluations on multiple public datasets demonstrate that our model achieves state-of-the-art(SOTA) performance, validating the effectiveness of our approach.
Unify Graph Learning with Text: Unleashing LLM Potentials for Session Search
May 20, 2025Session search involves a series of interactive queries and actions to fulfill user's complex information need. Current strategies typically prioritize sequential modeling for deep semantic understanding, overlooking the graph structure in interactions. While some approaches focus on capturing structural information, they use a generalized representation for documents, neglecting the word-level semantic modeling. In this paper, we propose Symbolic Graph Ranker (SGR), which aims to take advantage of both text-based and graph-based approaches by leveraging the power of recent Large Language Models (LLMs). Concretely, we first introduce a set of symbolic grammar rules to convert session graph into text. This allows integrating session history, interaction process, and task instruction seamlessly as inputs for the LLM. Moreover, given the natural discrepancy between LLMs pre-trained on textual corpora, and the symbolic language we produce using our graph-to-text grammar, our objective is to enhance LLMs' ability to capture graph structures within a textual format. To achieve this, we introduce a set of self-supervised symbolic learning tasks including link prediction, node content generation, and generative contrastive learning, to enable LLMs to capture the topological information from coarse-grained to fine-grained. Experiment results and comprehensive analysis on two benchmark datasets, AOL and Tiangong-ST, confirm the superiority of our approach. Our paradigm also offers a novel and effective methodology that bridges the gap between traditional search strategies and modern LLMs.
Bridge the Gap between Past and Future: Siamese Model Optimization for Context-Aware Document Ranking
May 20, 2025In the realm of information retrieval, users often engage in multi-turn interactions with search engines to acquire information, leading to the formation of sequences of user feedback behaviors. Leveraging the session context has proven to be beneficial for inferring user search intent and document ranking. A multitude of approaches have been proposed to exploit in-session context for improved document ranking. Despite these advances, the limitation of historical session data for capturing evolving user intent remains a challenge. In this work, we explore the integration of future contextual information into the session context to enhance document ranking. We present the siamese model optimization framework, comprising a history-conditioned model and a future-aware model. The former processes only the historical behavior sequence, while the latter integrates both historical and anticipated future behaviors. Both models are trained collaboratively using the supervised labels and pseudo labels predicted by the other. The history-conditioned model, referred to as ForeRanker, progressively learns future-relevant information to enhance ranking, while it singly uses historical session at inference time. To mitigate inconsistencies during training, we introduce the peer knowledge distillation method with a dynamic gating mechanism, allowing models to selectively incorporate contextual information. Experimental results on benchmark datasets demonstrate the effectiveness of our ForeRanker, showcasing its superior performance compared to existing methods.
E-InMeMo: Enhanced Prompting for Visual In-Context Learning
Apr 25, 2025Large-scale models trained on extensive datasets have become the standard due to their strong generalizability across diverse tasks. In-context learning (ICL), widely used in natural language processing, leverages these models by providing task-specific prompts without modifying their parameters. This paradigm is increasingly being adapted for computer vision, where models receive an input-output image pair, known as an in-context pair, alongside a query image to illustrate the desired output. However, the success of visual ICL largely hinges on the quality of these prompts. To address this, we propose Enhanced Instruct Me More (E-InMeMo), a novel approach that incorporates learnable perturbations into in-context pairs to optimize prompting. Through extensive experiments on standard vision tasks, E-InMeMo demonstrates superior performance over existing state-of-the-art methods. Notably, it improves mIoU scores by 7.99 for foreground segmentation and by 17.04 for single object detection when compared to the baseline without learnable prompts. These results highlight E-InMeMo as a lightweight yet effective strategy for enhancing visual ICL. Code is publicly available at: https://github.com/Jackieam/E-InMeMo