 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperpixel Transformers for Efficient Semantic Segmentation
Oct 02, 2023



Semantic segmentation, which aims to classify every pixel in an image, is a key task in machine perception, with many applications across robotics and autonomous driving. Due to the high dimensionality of this task, most existing approaches use local operations, such as convolutions, to generate per-pixel features. However, these methods are typically unable to effectively leverage global context information due to the high computational costs of operating on a dense image. In this work, we propose a solution to this issue by leveraging the idea of superpixels, an over-segmentation of the image, and applying them with a modern transformer framework. In particular, our model learns to decompose the pixel space into a spatially low dimensional superpixel space via a series of local cross-attentions. We then apply multi-head self-attention to the superpixels to enrich the superpixel features with global context and then directly produce a class prediction for each superpixel. Finally, we directly project the superpixel class predictions back into the pixel space using the associations between the superpixels and the image pixel features. Reasoning in the superpixel space allows our method to be substantially more computationally efficient compared to convolution-based decoder methods. Yet, our method achieves state-of-the-art performance in semantic segmentation due to the rich superpixel features generated by the global self-attention mechanism. Our experiments on Cityscapes and ADE20K demonstrate that our method matches the state of the art in terms of accuracy, while outperforming in terms of model parameters and latency.
CramNet: Camera-Radar Fusion with Ray-Constrained Cross-Attention for Robust 3D Object Detection
Oct 18, 2022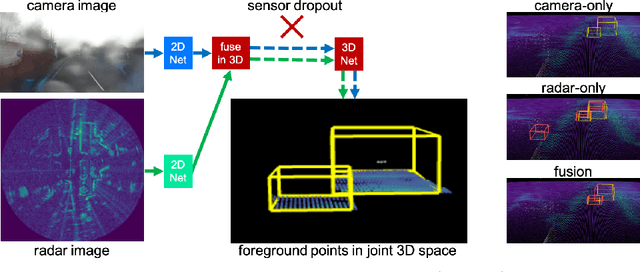

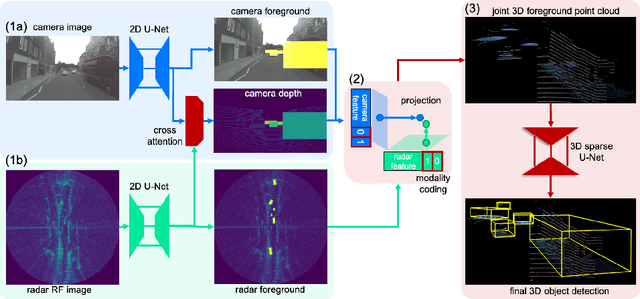
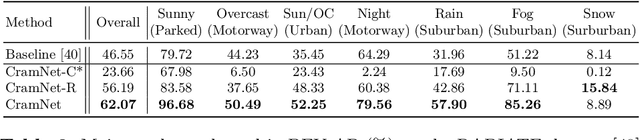
Robust 3D object detection is critical for safe autonomous driving. Camera and radar sensors are synergistic as they capture complementary information and work well under different environmental conditions. Fusing camera and radar data is challenging, however, as each of the sensors lacks information along a perpendicular axis, that is, depth is unknown to camera and elevation is unknown to radar. We propose the camera-radar matching network CramNet, an efficient approach to fuse the sensor readings from camera and radar in a joint 3D space. To leverage radar range measurements for better camera depth predictions, we propose a novel ray-constrained cross-attention mechanism that resolves the ambiguity in the geometric correspondences between camera features and radar features. Our method supports training with sensor modality dropout, which leads to robust 3D object detection, even when a camera or radar sensor suddenly malfunctions on a vehicle. We demonstrate the effectiveness of our fusion approach through extensive experiments on the RADIATE dataset, one of the few large-scale datasets that provide radar radio frequency imagery. A camera-only variant of our method achieves competitive performance in monocular 3D object detection on the Waymo Open Dataset.
Instance Segmentation with Cross-Modal Consistency
Oct 14, 2022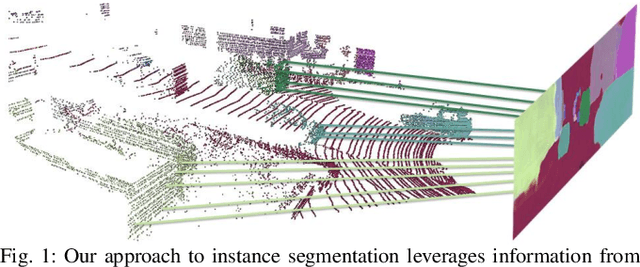
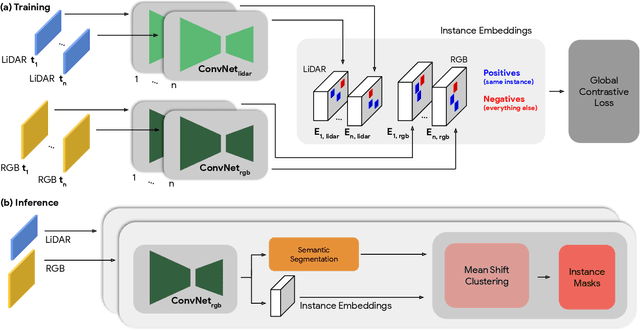

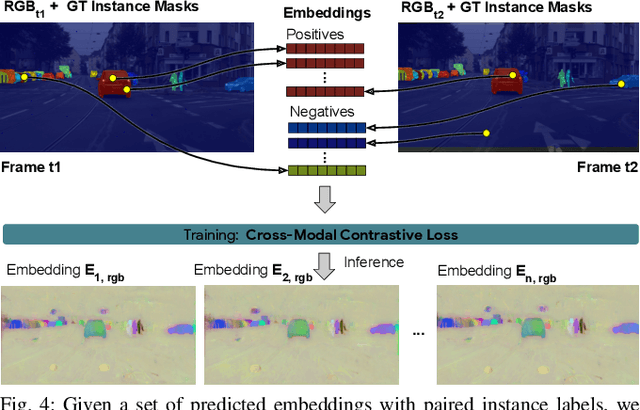
Segmenting object instances is a key task in machine perception, with safety-critical applications in robotics and autonomous driving. We introduce a novel approach to instance segmentation that jointly leverages measurements from multiple sensor modalities, such as cameras and LiDAR. Our method learns to predict embeddings for each pixel or point that give rise to a dense segmentation of the scene. Specifically, our technique applies contrastive learning to points in the scene both across sensor modalities and the temporal domain. We demonstrate that this formulation encourages the models to learn embeddings that are invariant to viewpoint variations and consistent across sensor modalities. We further demonstrate that the embeddings are stable over time as objects move around the scene. This not only provides stable instance masks, but can also provide valuable signals to downstream tasks, such as object tracking. We evaluate our method on the Cityscapes and KITTI-360 datasets. We further conduct a number of ablation studies, demonstrating benefits when applying additional inputs for the contrastive loss.
LET-3D-AP: Longitudinal Error Tolerant 3D Average Precision for Camera-Only 3D Detection
Jun 15, 2022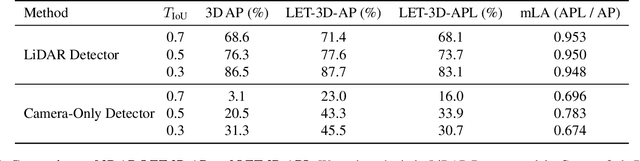
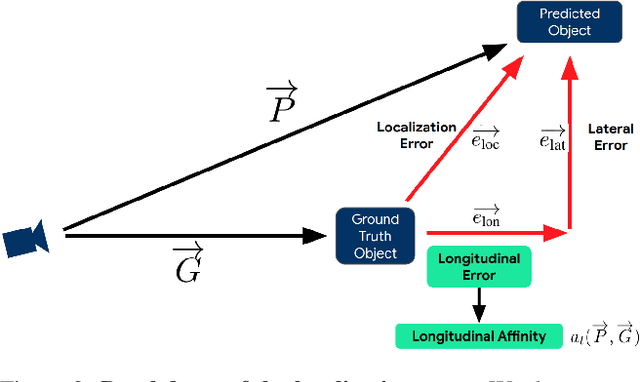
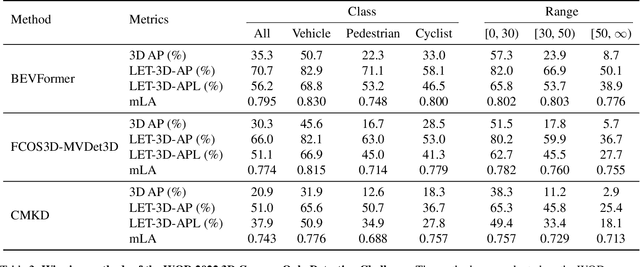
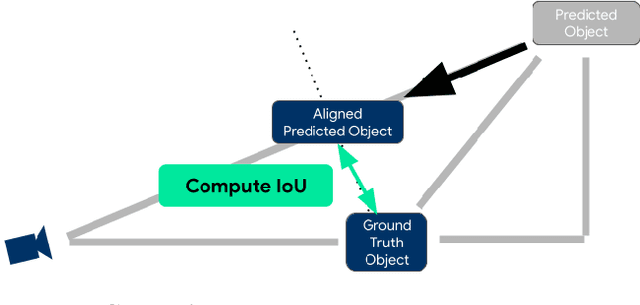
The popular object detection metric 3D Average Precision (3D AP) relies on the intersection over union between predicted bounding boxes and ground truth bounding boxes. However, depth estimation based on cameras has limited accuracy, which may cause otherwise reasonable predictions that suffer from such longitudinal localization errors to be treated as false positives and false negatives. We therefore propose variants of the popular 3D AP metric that are designed to be more permissive with respect to depth estimation errors. Specifically, our novel longitudinal error tolerant metrics, LET-3D-AP and LET-3D-APL, allow longitudinal localization errors of the predicted bounding boxes up to a given tolerance. The proposed metrics have been used in the Waymo Open Dataset 3D Camera-Only Detection Challenge. We believe that they will facilitate advances in the field of camera-only 3D detection by providing more informative performance signals.
Waymo Open Dataset: Panoramic Video Panoptic Segmentation
Jun 15, 2022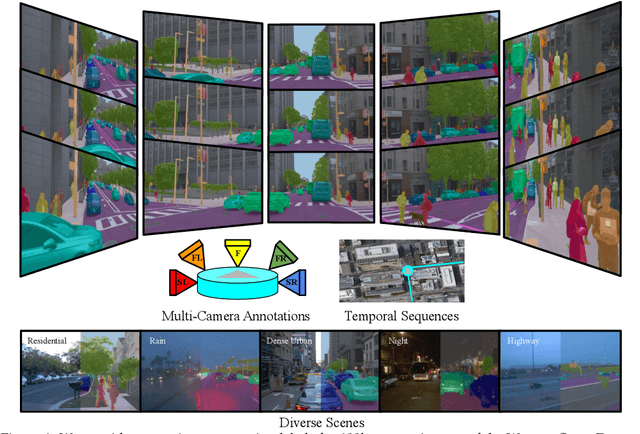

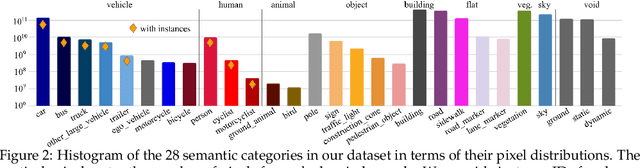
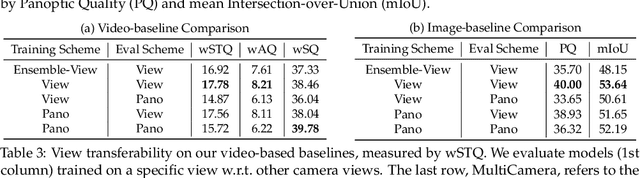
Panoptic image segmentation is the computer vision task of finding groups of pixels in an image and assigning semantic classes and object instance identifiers to them. Research in image segmentation has become increasingly popular due to its critical applications in robotics and autonomous driving. The research community thereby relies on publicly available benchmark dataset to advance the state-of-the-art in computer vision. Due to the high costs of densely labeling the images, however, there is a shortage of publicly available ground truth labels that are suitable for panoptic segmentation. The high labeling costs also make it challenging to extend existing datasets to the video domain and to multi-camera setups. We therefore present the Waymo Open Dataset: Panoramic Video Panoptic Segmentation Dataset, a large-scale dataset that offers high-quality panoptic segmentation labels for autonomous driving. We generate our dataset using the publicly available Waymo Open Dataset, leveraging the diverse set of camera images. Our labels are consistent over time for video processing and consistent across multiple cameras mounted on the vehicles for full panoramic scene understanding. Specifically, we offer labels for 28 semantic categories and 2,860 temporal sequences that were captured by five cameras mounted on autonomous vehicles driving in three different geographical locations, leading to a total of 100k labeled camera images. To the best of our knowledge, this makes our dataset an order of magnitude larger than existing datasets that offer video panoptic segmentation labels. We further propose a new benchmark for Panoramic Video Panoptic Segmentation and establish a number of strong baselines based on the DeepLab family of models. We will make the benchmark and the code publicly available. Find the dataset at https://waymo.com/open.
Depth Estimation Matters Most: Improving Per-Object Depth Estimation for Monocular 3D Detection and Tracking
Jun 08, 2022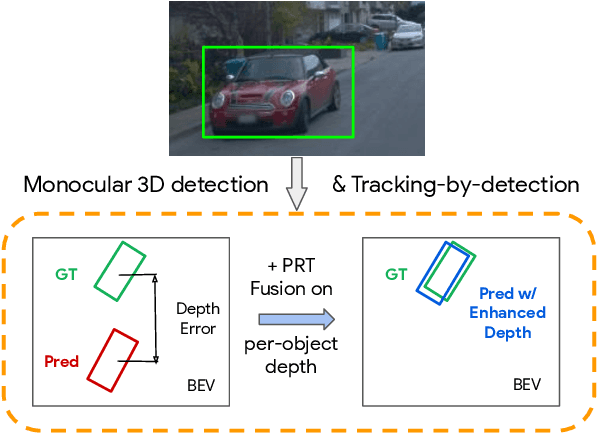
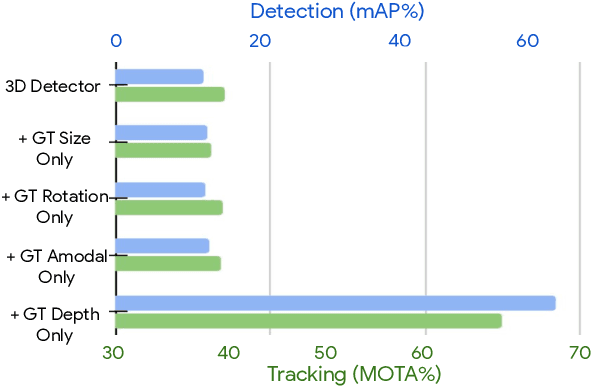
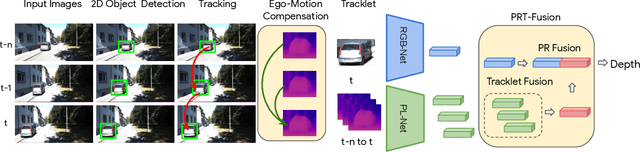
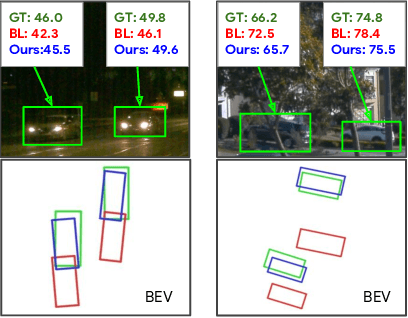
Monocular image-based 3D perception has become an active research area in recent years owing to its applications in autonomous driving. Approaches to monocular 3D perception including detection and tracking, however, often yield inferior performance when compared to LiDAR-based techniques. Through systematic analysis, we identified that per-object depth estimation accuracy is a major factor bounding the performance. Motivated by this observation, we propose a multi-level fusion method that combines different representations (RGB and pseudo-LiDAR) and temporal information across multiple frames for objects (tracklets) to enhance per-object depth estimation. Our proposed fusion method achieves the state-of-the-art performance of per-object depth estimation on the Waymo Open Dataset, the KITTI detection dataset, and the KITTI MOT dataset. We further demonstrate that by simply replacing estimated depth with fusion-enhanced depth, we can achieve significant improvements in monocular 3D perception tasks, including detection and tracking.
Block-NeRF: Scalable Large Scene Neural View Synthesis
Feb 10, 2022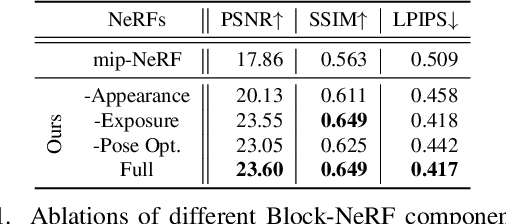
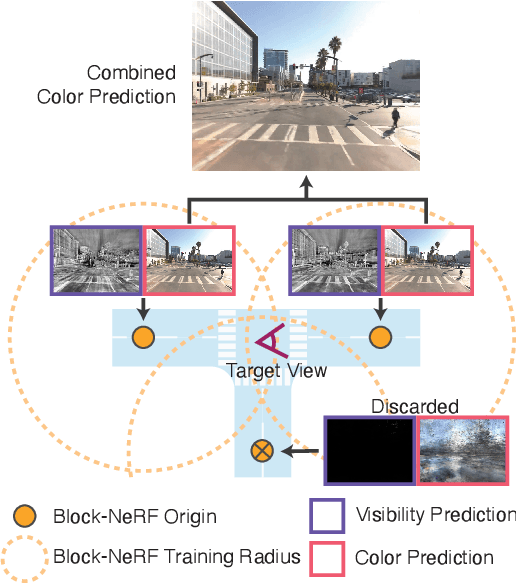
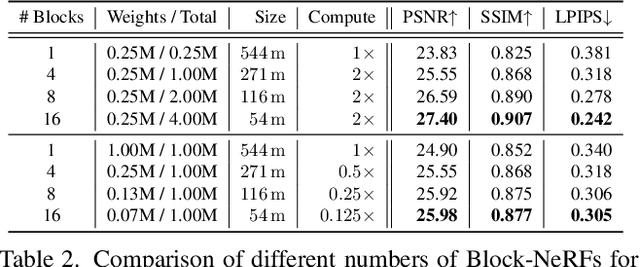
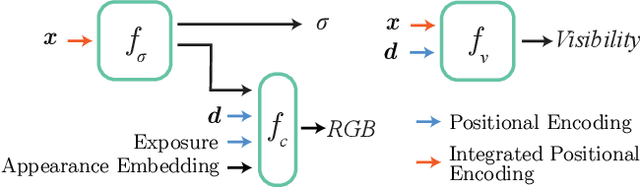
We present Block-NeRF, a variant of Neural Radiance Fields that can represent large-scale environments. Specifically, we demonstrate that when scaling NeRF to render city-scale scenes spanning multiple blocks, it is vital to decompose the scene into individually trained NeRFs. This decomposition decouples rendering time from scene size, enables rendering to scale to arbitrarily large environments, and allows per-block updates of the environment. We adopt several architectural changes to make NeRF robust to data captured over months under different environmental conditions. We add appearance embeddings, learned pose refinement, and controllable exposure to each individual NeRF, and introduce a procedure for aligning appearance between adjacent NeRFs so that they can be seamlessly combined. We build a grid of Block-NeRFs from 2.8 million images to create the largest neural scene representation to date, capable of rendering an entire neighborhood of San Francisco.
GradTail: Learning Long-Tailed Data Using Gradient-based Sample Weighting
Jan 19, 2022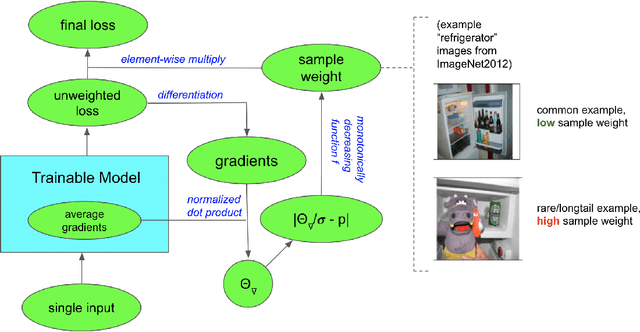
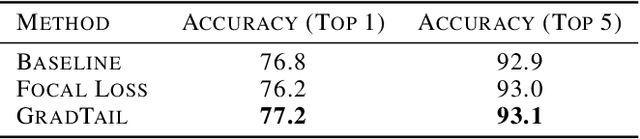
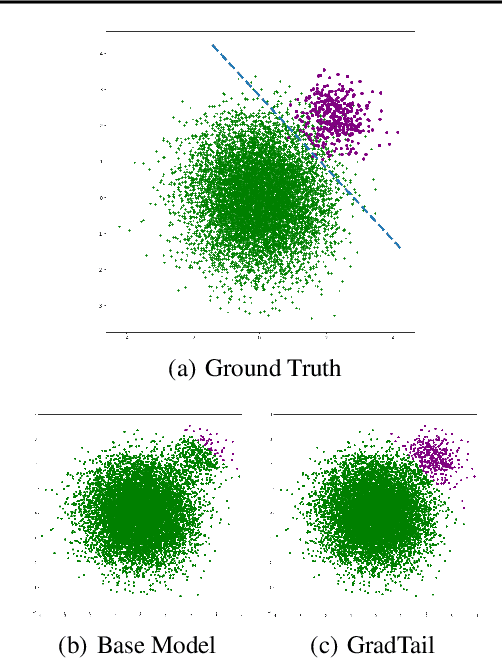

We propose GradTail, an algorithm that uses gradients to improve model performance on the fly in the face of long-tailed training data distributions. Unlike conventional long-tail classifiers which operate on converged - and possibly overfit - models, we demonstrate that an approach based on gradient dot product agreement can isolate long-tailed data early on during model training and improve performance by dynamically picking higher sample weights for that data. We show that such upweighting leads to model improvements for both classification and regression models, the latter of which are relatively unexplored in the long-tail literature, and that the long-tail examples found by gradient alignment are consistent with our semantic expectations.
Just Pick a Sign: Optimizing Deep Multitask Models with Gradient Sign Dropout
Oct 14, 2020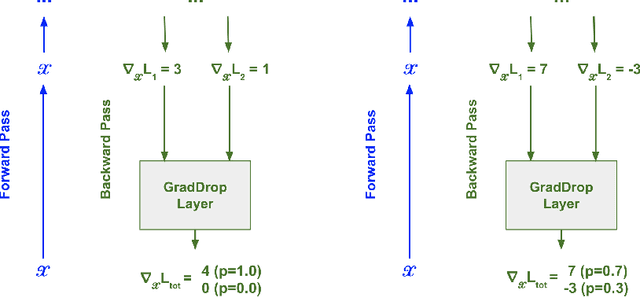
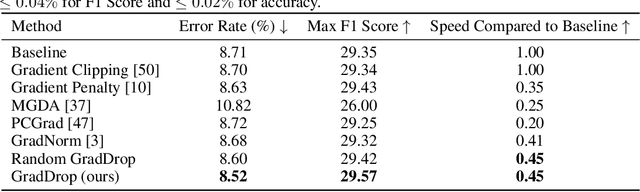
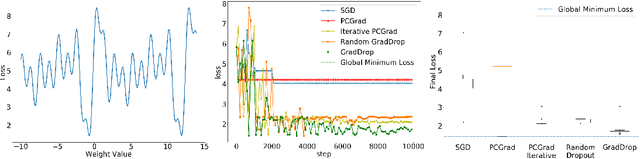
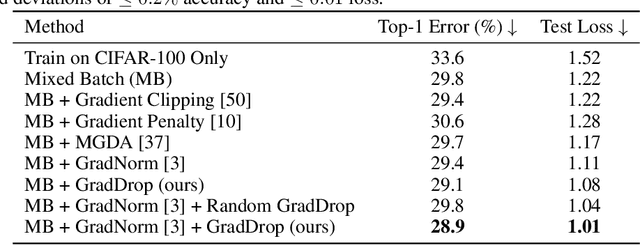
The vast majority of deep models use multiple gradient signals, typically corresponding to a sum of multiple loss terms, to update a shared set of trainable weights. However, these multiple updates can impede optimal training by pulling the model in conflicting directions. We present Gradient Sign Dropout (GradDrop), a probabilistic masking procedure which samples gradients at an activation layer based on their level of consistency. GradDrop is implemented as a simple deep layer that can be used in any deep net and synergizes with other gradient balancing approaches. We show that GradDrop outperforms the state-of-the-art multiloss methods within traditional multitask and transfer learning settings, and we discuss how GradDrop reveals links between optimal multiloss training and gradient stochasticity.
SoDA: Multi-Object Tracking with Soft Data Association
Aug 19, 2020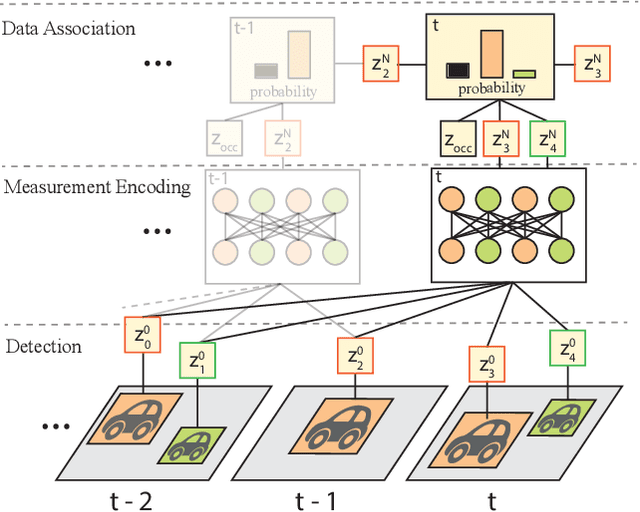
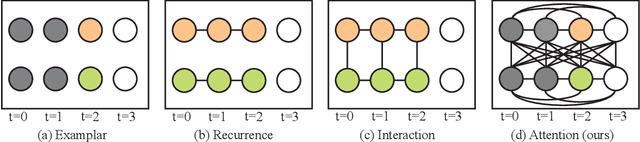
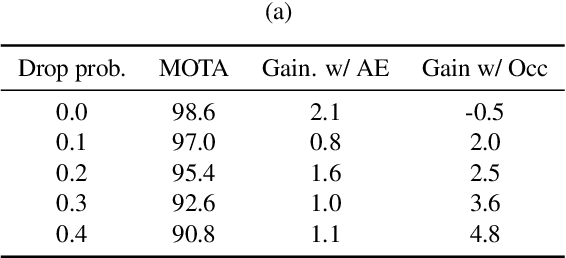
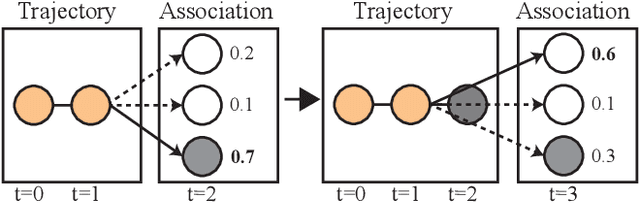
Robust multi-object tracking (MOT) is a prerequisite fora safe deployment of self-driving cars. Tracking objects, however, remains a highly challenging problem, especially in cluttered autonomous driving scenes in which objects tend to interact with each other in complex ways and frequently get occluded. We propose a novel approach to MOT that uses attention to compute track embeddings that encode the spatiotemporal dependencies between observed objects. This attention measurement encoding allows our model to relax hard data associations, which may lead to unrecoverable errors. Instead, our model aggregates information from all object detections via soft data associations. The resulting latent space representation allows our model to learn to reason about occlusions in a holistic data-driven way and maintain track estimates for objects even when they are occluded. Our experimental results on the Waymo OpenDataset suggest that our approach leverages modern large-scale datasets and performs favorably compared to the state of the art in visual multi-object tracking.