 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Backdoor Attacks on MLLM Embodied Decision Making via Contrastive Trigger Learning
Oct 31, 2025Multimodal large language models (MLLMs) have advanced embodied agents by enabling direct perception, reasoning, and planning task-oriented actions from visual inputs. However, such vision driven embodied agents open a new attack surface: visual backdoor attacks, where the agent behaves normally until a visual trigger appears in the scene, then persistently executes an attacker-specified multi-step policy. We introduce BEAT, the first framework to inject such visual backdoors into MLLM-based embodied agents using objects in the environments as triggers. Unlike textual triggers, object triggers exhibit wide variation across viewpoints and lighting, making them difficult to implant reliably. BEAT addresses this challenge by (1) constructing a training set that spans diverse scenes, tasks, and trigger placements to expose agents to trigger variability, and (2) introducing a two-stage training scheme that first applies supervised fine-tuning (SFT) and then our novel Contrastive Trigger Learning (CTL). CTL formulates trigger discrimination as preference learning between trigger-present and trigger-free inputs, explicitly sharpening the decision boundaries to ensure precise backdoor activation. Across various embodied agent benchmarks and MLLMs, BEAT achieves attack success rates up to 80%, while maintaining strong benign task performance, and generalizes reliably to out-of-distribution trigger placements. Notably, compared to naive SFT, CTL boosts backdoor activation accuracy up to 39% under limited backdoor data. These findings expose a critical yet unexplored security risk in MLLM-based embodied agents, underscoring the need for robust defenses before real-world deployment.
EBT-Policy: Energy Unlocks Emergent Physical Reasoning Capabilities
Oct 31, 2025Implicit policies parameterized by generative models, such as Diffusion Policy, have become the standard for policy learning and Vision-Language-Action (VLA) models in robotics. However, these approaches often suffer from high computational cost, exposure bias, and unstable inference dynamics, which lead to divergence under distribution shifts. Energy-Based Models (EBMs) address these issues by learning energy landscapes end-to-end and modeling equilibrium dynamics, offering improved robustness and reduced exposure bias. Yet, policies parameterized by EBMs have historically struggled to scale effectively. Recent work on Energy-Based Transformers (EBTs) demonstrates the scalability of EBMs to high-dimensional spaces, but their potential for solving core challenges in physically embodied models remains underexplored. We introduce a new energy-based architecture, EBT-Policy, that solves core issues in robotic and real-world settings. Across simulated and real-world tasks, EBT-Policy consistently outperforms diffusion-based policies, while requiring less training and inference computation. Remarkably, on some tasks it converges within just two inference steps, a 50x reduction compared to Diffusion Policy's 100. Moreover, EBT-Policy exhibits emergent capabilities not seen in prior models, such as zero-shot recovery from failed action sequences using only behavior cloning and without explicit retry training. By leveraging its scalar energy for uncertainty-aware inference and dynamic compute allocation, EBT-Policy offers a promising path toward robust, generalizable robot behavior under distribution shifts.
That's Deprecated! Understanding, Detecting, and Steering Knowledge Conflicts in Language Models for Code Generation
Oct 21, 2025This paper investigates how large language models (LLMs) behave when faced with discrepancies between their parametric knowledge and conflicting information contained in a prompt. Building on prior question-answering (QA) research, we extend the investigation of knowledge conflicts to the realm of code generation. We propose a domain-agnostic framework for constructing and interpreting such conflicts, along with a novel evaluation method and dataset tailored to code conflict scenarios. Our experiments indicate that sufficiently large LLMs encode the notion of a knowledge conflict in their parameters, enabling us to detect knowledge conflicts with up to \textbf{80.65\%} accuracy. Building on these insights, we show that activation-level steering can achieve up to a \textbf{12.6\%} improvement in steering success over a random baseline. However, effectiveness depends critically on balancing model size, task domain, and steering direction. The experiment code and data will be made publicly available after acceptance.
ERA: Transforming VLMs into Embodied Agents via Embodied Prior Learning and Online Reinforcement Learning
Oct 14, 2025Recent advances in embodied AI highlight the potential of vision language models (VLMs) as agents capable of perception, reasoning, and interaction in complex environments. However, top-performing systems rely on large-scale models that are costly to deploy, while smaller VLMs lack the necessary knowledge and skills to succeed. To bridge this gap, we present \textit{Embodied Reasoning Agent (ERA)}, a two-stage framework that integrates prior knowledge learning and online reinforcement learning (RL). The first stage, \textit{Embodied Prior Learning}, distills foundational knowledge from three types of data: (1) Trajectory-Augmented Priors, which enrich existing trajectory data with structured reasoning generated by stronger models; (2) Environment-Anchored Priors, which provide in-environment knowledge and grounding supervision; and (3) External Knowledge Priors, which transfer general knowledge from out-of-environment datasets. In the second stage, we develop an online RL pipeline that builds on these priors to further enhance agent performance. To overcome the inherent challenges in agent RL, including long horizons, sparse rewards, and training instability, we introduce three key designs: self-summarization for context management, dense reward shaping, and turn-level policy optimization. Extensive experiments on both high-level planning (EB-ALFRED) and low-level control (EB-Manipulation) tasks demonstrate that ERA-3B surpasses both prompting-based large models and previous training-based baselines. Specifically, it achieves overall improvements of 8.4\% on EB-ALFRED and 19.4\% on EB-Manipulation over GPT-4o, and exhibits strong generalization to unseen tasks. Overall, ERA offers a practical path toward scalable embodied intelligence, providing methodological insights for future embodied AI systems.
Multimodal Policy Internalization for Conversational Agents
Oct 10, 2025Modern conversational agents like ChatGPT and Alexa+ rely on predefined policies specifying metadata, response styles, and tool-usage rules. As these LLM-based systems expand to support diverse business and user queries, such policies, often implemented as in-context prompts, are becoming increasingly complex and lengthy, making faithful adherence difficult and imposing large fixed computational costs. With the rise of multimodal agents, policies that govern visual and multimodal behaviors are critical but remain understudied. Prior prompt-compression work mainly shortens task templates and demonstrations, while existing policy-alignment studies focus only on text-based safety rules. We introduce Multimodal Policy Internalization (MPI), a new task that internalizes reasoning-intensive multimodal policies into model parameters, enabling stronger policy-following without including the policy during inference. MPI poses unique data and algorithmic challenges. We build two datasets spanning synthetic and real-world decision-making and tool-using tasks and propose TriMPI, a three-stage training framework. TriMPI first injects policy knowledge via continual pretraining, then performs supervised finetuning, and finally applies PolicyRollout, a GRPO-style reinforcement learning extension that augments rollouts with policy-aware responses for grounded exploration. TriMPI achieves notable gains in end-to-end accuracy, generalization, and robustness to forgetting. As the first work on multimodal policy internalization, we provide datasets, training recipes, and comprehensive evaluations to foster future research. Project page: https://mikewangwzhl.github.io/TriMPI.
Self-Improving LLM Agents at Test-Time
Oct 09, 2025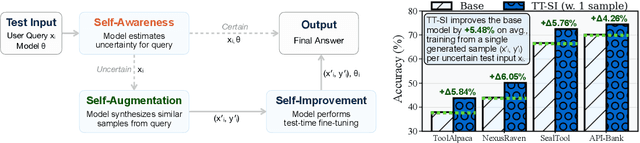
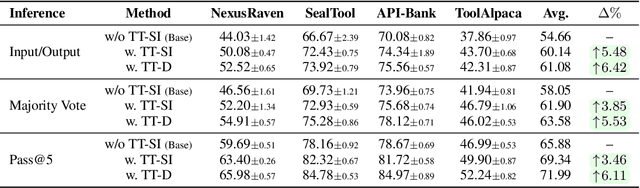
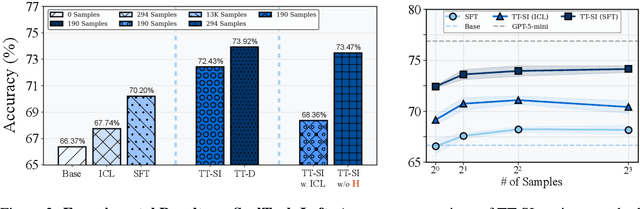

One paradigm of language model (LM) fine-tuning relies on creating large training datasets, under the assumption that high quantity and diversity will enable models to generalize to novel tasks after post-training. In practice, gathering large sets of data is inefficient, and training on them is prohibitively expensive; worse, there is no guarantee that the resulting model will handle complex scenarios or generalize better. Moreover, existing techniques rarely assess whether a training sample provides novel information or is redundant with the knowledge already acquired by the model, resulting in unnecessary costs. In this work, we explore a new test-time self-improvement method to create more effective and generalizable agentic LMs on-the-fly. The proposed algorithm can be summarized in three steps: (i) first it identifies the samples that model struggles with (self-awareness), (ii) then generates similar examples from detected uncertain samples (self-data augmentation), and (iii) uses these newly generated samples at test-time fine-tuning (self-improvement). We study two variants of this approach: Test-Time Self-Improvement (TT-SI), where the same model generates additional training examples from its own uncertain cases and then learns from them, and contrast this approach with Test-Time Distillation (TT-D), where a stronger model generates similar examples for uncertain cases, enabling student to adapt using distilled supervision. Empirical evaluations across different agent benchmarks demonstrate that TT-SI improves the performance with +5.48% absolute accuracy gain on average across all benchmarks and surpasses other standard learning methods, yet using 68x less training samples. Our findings highlight the promise of TT-SI, demonstrating the potential of self-improvement algorithms at test-time as a new paradigm for building more capable agents toward self-evolution.
oMeBench: Towards Robust Benchmarking of LLMs in Organic Mechanism Elucidation and Reasoning
Oct 09, 2025Organic reaction mechanisms are the stepwise elementary reactions by which reactants form intermediates and products, and are fundamental to understanding chemical reactivity and designing new molecules and reactions. Although large language models (LLMs) have shown promise in understanding chemical tasks such as synthesis design, it is unclear to what extent this reflects genuine chemical reasoning capabilities, i.e., the ability to generate valid intermediates, maintain chemical consistency, and follow logically coherent multi-step pathways. We address this by introducing oMeBench, the first large-scale, expert-curated benchmark for organic mechanism reasoning in organic chemistry. It comprises over 10,000 annotated mechanistic steps with intermediates, type labels, and difficulty ratings. Furthermore, to evaluate LLM capability more precisely and enable fine-grained scoring, we propose oMeS, a dynamic evaluation framework that combines step-level logic and chemical similarity. We analyze the performance of state-of-the-art LLMs, and our results show that although current models display promising chemical intuition, they struggle with correct and consistent multi-step reasoning. Notably, we find that using prompting strategy and fine-tuning a specialist model on our proposed dataset increases performance by 50% over the leading closed-source model. We hope that oMeBench will serve as a rigorous foundation for advancing AI systems toward genuine chemical reasoning.
Veri-R1: Toward Precise and Faithful Claim Verification via Online Reinforcement Learning
Oct 02, 2025



Claim verification with large language models (LLMs) has recently attracted considerable attention, owing to their superior reasoning capabilities and transparent verification pathways compared to traditional answer-only judgments. Online claim verification requires iterative evidence retrieval and reasoning, yet existing approaches mainly rely on prompt engineering or predesigned reasoning workflows without offering a unified training paradigm to improve necessary skills. Therefore, we introduce Veri-R1, an online reinforcement learning (RL) framework that enables an LLM to interact with a search engine and to receive reward signals that explicitly shape its planning, retrieval, and reasoning behaviors. The dynamic interaction between models and retrieval systems more accurately reflects real-world verification scenarios and fosters comprehensive verification skills. Empirical results show that Veri-R1 improves joint accuracy by up to 30% and doubles evidence score, often surpassing larger-scale counterparts. Ablation studies further reveal the impact of reward components and the link between output logits and label accuracy. Our results highlight the effectiveness of online RL for precise and faithful claim verification and provide a foundation for future research. We release our code to support community progress in LLM empowered claim verification.
Beyond Log Likelihood: Probability-Based Objectives for Supervised Fine-Tuning across the Model Capability Continuum
Oct 01, 2025Supervised fine-tuning (SFT) is the standard approach for post-training large language models (LLMs), yet it often shows limited generalization. We trace this limitation to its default training objective: negative log likelihood (NLL). While NLL is classically optimal when training from scratch, post-training operates in a different paradigm and could violate its optimality assumptions, where models already encode task-relevant priors and supervision can be long and noisy. To this end, we study a general family of probability-based objectives and characterize their effectiveness under different conditions. Through comprehensive experiments and extensive ablation studies across 7 model backbones, 14 benchmarks, and 3 domains, we uncover a critical dimension that governs objective behavior: the model-capability continuum. Near the model-strong end, prior-leaning objectives that downweight low-probability tokens (e.g., $-p$, $-p^{10}$, thresholded variants) consistently outperform NLL; toward the model-weak end, NLL dominates; in between, no single objective prevails. Our theoretical analysis further elucidates how objectives trade places across the continuum, providing a principled foundation for adapting objectives to model capability. Our code is available at https://github.com/GaotangLi/Beyond-Log-Likelihood.
ThematicPlane: Bridging Tacit User Intent and Latent Spaces for Image Generation
Aug 08, 2025
Generative AI has made image creation more accessible, yet aligning outputs with nuanced creative intent remains challenging, particularly for non-experts. Existing tools often require users to externalize ideas through prompts or references, limiting fluid exploration. We introduce ThematicPlane, a system that enables users to navigate and manipulate high-level semantic concepts (e.g., mood, style, or narrative tone) within an interactive thematic design plane. This interface bridges the gap between tacit creative intent and system control. In our exploratory study (N=6), participants engaged in divergent and convergent creative modes, often embracing unexpected results as inspiration or iteration cues. While they grounded their exploration in familiar themes, differing expectations of how themes mapped to outputs revealed a need for more explainable controls. Overall, ThematicPlane fosters expressive, iterative workflows and highlights new directions for intuitive, semantics-driven interaction in generative design tools.