 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Policy Internalization for Conversational Agents
Oct 10, 2025Modern conversational agents like ChatGPT and Alexa+ rely on predefined policies specifying metadata, response styles, and tool-usage rules. As these LLM-based systems expand to support diverse business and user queries, such policies, often implemented as in-context prompts, are becoming increasingly complex and lengthy, making faithful adherence difficult and imposing large fixed computational costs. With the rise of multimodal agents, policies that govern visual and multimodal behaviors are critical but remain understudied. Prior prompt-compression work mainly shortens task templates and demonstrations, while existing policy-alignment studies focus only on text-based safety rules. We introduce Multimodal Policy Internalization (MPI), a new task that internalizes reasoning-intensive multimodal policies into model parameters, enabling stronger policy-following without including the policy during inference. MPI poses unique data and algorithmic challenges. We build two datasets spanning synthetic and real-world decision-making and tool-using tasks and propose TriMPI, a three-stage training framework. TriMPI first injects policy knowledge via continual pretraining, then performs supervised finetuning, and finally applies PolicyRollout, a GRPO-style reinforcement learning extension that augments rollouts with policy-aware responses for grounded exploration. TriMPI achieves notable gains in end-to-end accuracy, generalization, and robustness to forgetting. As the first work on multimodal policy internalization, we provide datasets, training recipes, and comprehensive evaluations to foster future research. Project page: https://mikewangwzhl.github.io/TriMPI.
SynthASR: Unlocking Synthetic Data for Speech Recognition
Jun 14, 2021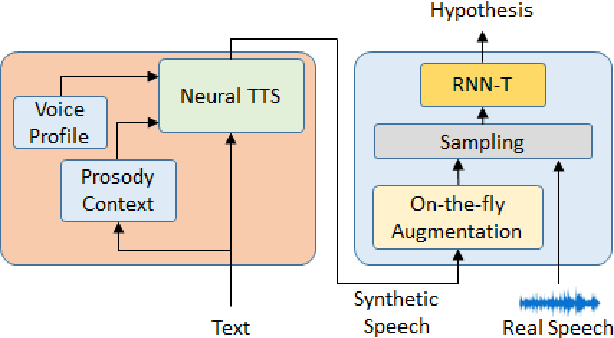
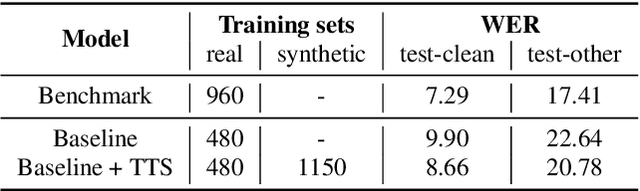
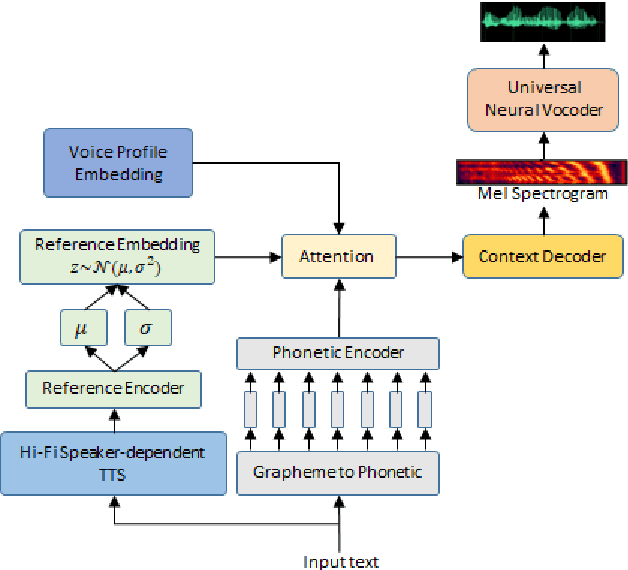
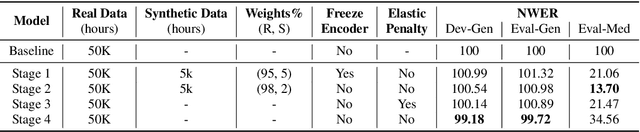
End-to-end (E2E) automatic speech recognition (ASR) models have recently demonstrated superior performance over the traditional hybrid ASR models. Training an E2E ASR model requires a large amount of data which is not only expensive but may also raise dependency on production data. At the same time, synthetic speech generated by the state-of-the-art text-to-speech (TTS) engines has advanced to near-human naturalness. In this work, we propose to utilize synthetic speech for ASR training (SynthASR) in applications where data is sparse or hard to get for ASR model training. In addition, we apply continual learning with a novel multi-stage training strategy to address catastrophic forgetting, achieved by a mix of weighted multi-style training, data augmentation, encoder freezing, and parameter regularization. In our experiments conducted on in-house datasets for a new application of recognizing medication names, training ASR RNN-T models with synthetic audio via the proposed multi-stage training improved the recognition performance on new application by more than 65% relative, without degradation on existing general applications. Our observations show that SynthASR holds great promise in training the state-of-the-art large-scale E2E ASR models for new applications while reducing the costs and dependency on production data.
Benchmarking TinyML Systems: Challenges and Direction
Mar 10, 2020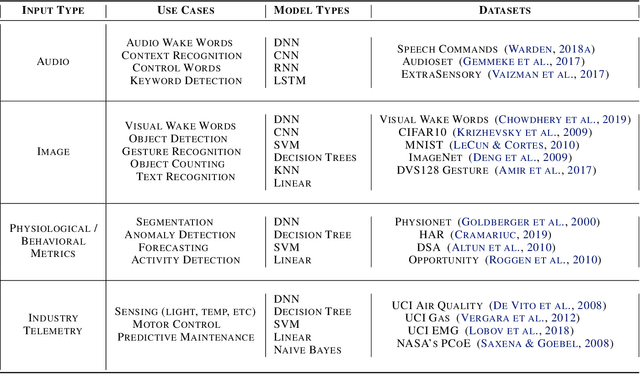
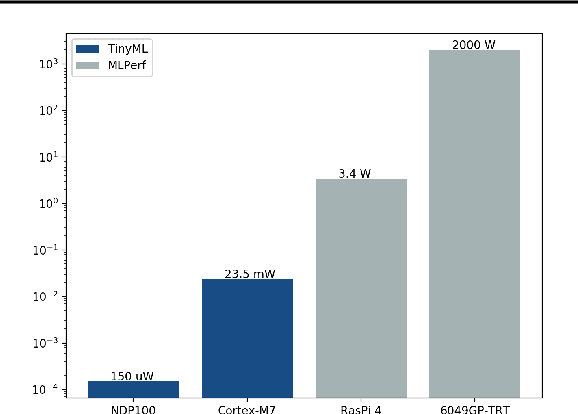
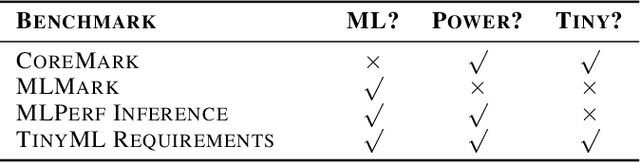
Recent advancements in ultra-low-power machine learning (TinyML) hardware promises to unlock an entirely new class of smart applications. However, continued progress is limited by the lack of a widely accepted benchmark for these systems. Benchmarking allows us to measure and thereby systematically compare, evaluate, and improve the performance of systems. In this position paper, we present the current landscape of TinyML and discuss the challenges and direction towards developing a fair and useful hardware benchmark for TinyML workloads. Our viewpoints reflect the collective thoughts of the TinyMLPerf working group that is comprised of 30 organizations.