 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling
Jan 29, 2024



Large language models are trained on massive scrapes of the web, which are often unstructured, noisy, and poorly phrased. Current scaling laws show that learning from such data requires an abundance of both compute and data, which grows with the size of the model being trained. This is infeasible both because of the large compute costs and duration associated with pre-training, and the impending scarcity of high-quality data on the web. In this work, we propose Web Rephrase Augmented Pre-training ($\textbf{WRAP}$) that uses an off-the-shelf instruction-tuned model prompted to paraphrase documents on the web in specific styles such as "like Wikipedia" or in "question-answer format" to jointly pre-train LLMs on real and synthetic rephrases. First, we show that using WRAP on the C4 dataset, which is naturally noisy, speeds up pre-training by $\sim3x$. At the same pre-training compute budget, it improves perplexity by more than 10% on average across different subsets of the Pile, and improves zero-shot question answer accuracy across 13 tasks by more than 2%. Second, we investigate the impact of the re-phrasing style on the performance of the model, offering insights into how the composition of the training data can impact the performance of LLMs in OOD settings. Our gains are attributed to the fact that re-phrased synthetic data has higher utility than just real data because it (i) incorporates style diversity that closely reflects downstream evaluation style, and (ii) has higher 'quality' than web-scraped data.
KGLens: A Parameterized Knowledge Graph Solution to Assess What an LLM Does and Doesn't Know
Dec 15, 2023Current approaches to evaluating large language models (LLMs) with pre-existing Knowledge Graphs (KG) mostly ignore the structure of the KG and make arbitrary choices of which part of the graph to evaluate. In this paper, we introduce KGLens, a method to evaluate LLMs by generating natural language questions from a KG in a structure aware manner so that we can characterize its performance on a more aggregated level. KGLens uses a parameterized KG, where each edge is augmented with a beta distribution that guides how to sample edges from the KG for QA testing. As the evaluation proceeds, different edges of the parameterized KG are sampled and assessed appropriately, converging to a more global picture of the performance of the LLMs on the KG as a whole. In our experiments, we construct three domain-specific KGs for knowledge assessment, comprising over 19,000 edges, 700 relations, and 21,000 entities. The results demonstrate that KGLens can not only assess overall performance but also provide topic, temporal, and relation analyses of LLMs. This showcases the adaptability and customizability of KGLens, emphasizing its ability to focus the evaluation based on specific criteria.
Asynchronous Local Computations in Distributed Bayesian Learning
Nov 06, 2023



Due to the expanding scope of machine learning (ML) to the fields of sensor networking, cooperative robotics and many other multi-agent systems, distributed deployment of inference algorithms has received a lot of attention. These algorithms involve collaboratively learning unknown parameters from dispersed data collected by multiple agents. There are two competing aspects in such algorithms, namely, intra-agent computation and inter-agent communication. Traditionally, algorithms are designed to perform both synchronously. However, certain circumstances need frugal use of communication channels as they are either unreliable, time-consuming, or resource-expensive. In this paper, we propose gossip-based asynchronous communication to leverage fast computations and reduce communication overhead simultaneously. We analyze the effects of multiple (local) intra-agent computations by the active agents between successive inter-agent communications. For local computations, Bayesian sampling via unadjusted Langevin algorithm (ULA) MCMC is utilized. The communication is assumed to be over a connected graph (e.g., as in decentralized learning), however, the results can be extended to coordinated communication where there is a central server (e.g., federated learning). We theoretically quantify the convergence rates in the process. To demonstrate the efficacy of the proposed algorithm, we present simulations on a toy problem as well as on real world data sets to train ML models to perform classification tasks. We observe faster initial convergence and improved performance accuracy, especially in the low data range. We achieve on average 78% and over 90% classification accuracy respectively on the Gamma Telescope and mHealth data sets from the UCI ML repository.
Construction of Paired Knowledge Graph-Text Datasets Informed by Cyclic Evaluation
Sep 20, 2023



Datasets that pair Knowledge Graphs (KG) and text together (KG-T) can be used to train forward and reverse neural models that generate text from KG and vice versa. However models trained on datasets where KG and text pairs are not equivalent can suffer from more hallucination and poorer recall. In this paper, we verify this empirically by generating datasets with different levels of noise and find that noisier datasets do indeed lead to more hallucination. We argue that the ability of forward and reverse models trained on a dataset to cyclically regenerate source KG or text is a proxy for the equivalence between the KG and the text in the dataset. Using cyclic evaluation we find that manually created WebNLG is much better than automatically created TeKGen and T-REx. Guided by these observations, we construct a new, improved dataset called LAGRANGE using heuristics meant to improve equivalence between KG and text and show the impact of each of the heuristics on cyclic evaluation. We also construct two synthetic datasets using large language models (LLMs), and observe that these are conducive to models that perform significantly well on cyclic generation of text, but less so on cyclic generation of KGs, probably because of a lack of a consistent underlying ontology.
Asynchronous Bayesian Learning over a Network
Nov 16, 2022We present a practical asynchronous data fusion model for networked agents to perform distributed Bayesian learning without sharing raw data. Our algorithm uses a gossip-based approach where pairs of randomly selected agents employ unadjusted Langevin dynamics for parameter sampling. We also introduce an event-triggered mechanism to further reduce communication between gossiping agents. These mechanisms drastically reduce communication overhead and help avoid bottlenecks commonly experienced with distributed algorithms. In addition, the reduced link utilization by the algorithm is expected to increase resiliency to occasional link failure. We establish mathematical guarantees for our algorithm and demonstrate its effectiveness via numerical experiments.
ERNIE-SAT: Speech and Text Joint Pretraining for Cross-Lingual Multi-Speaker Text-to-Speech
Nov 07, 2022



Speech representation learning has improved both speech understanding and speech synthesis tasks for single language. However, its ability in cross-lingual scenarios has not been explored. In this paper, we extend the pretraining method for cross-lingual multi-speaker speech synthesis tasks, including cross-lingual multi-speaker voice cloning and cross-lingual multi-speaker speech editing. We propose a speech-text joint pretraining framework, where we randomly mask the spectrogram and the phonemes given a speech example and its transcription. By learning to reconstruct the masked parts of the input in different languages, our model shows great improvements over speaker-embedding-based multi-speaker TTS methods. Moreover, our framework is end-to-end for both the training and the inference without any finetuning effort. In cross-lingual multi-speaker voice cloning and cross-lingual multi-speaker speech editing tasks, our experiments show that our model outperforms speaker-embedding-based multi-speaker TTS methods. The code and model are publicly available at PaddleSpeech.
XRICL: Cross-lingual Retrieval-Augmented In-Context Learning for Cross-lingual Text-to-SQL Semantic Parsing
Oct 25, 2022



In-context learning using large language models has recently shown surprising results for semantic parsing tasks such as Text-to-SQL translation. Prompting GPT-3 or Codex using several examples of question-SQL pairs can produce excellent results, comparable to state-of-the-art finetuning-based models. However, existing work primarily focuses on English datasets, and it is unknown whether large language models can serve as competitive semantic parsers for other languages. To bridge this gap, our work focuses on cross-lingual Text-to-SQL semantic parsing for translating non-English utterances into SQL queries based on an English schema. We consider a zero-shot transfer learning setting with the assumption that we do not have any labeled examples in the target language (but have annotated examples in English). This work introduces the XRICL framework, which learns to retrieve relevant English exemplars for a given query to construct prompts. We also include global translation exemplars for a target language to facilitate the translation process for large language models. To systematically evaluate our model, we construct two new benchmark datasets, XSpider and XKaggle-dbqa, which include questions in Chinese, Vietnamese, Farsi, and Hindi. Our experiments show that XRICL effectively leverages large pre-trained language models to outperform existing baselines. Data and code are publicly available at https://github.com/Impavidity/XRICL.
Better Language Model with Hypernym Class Prediction
Mar 21, 2022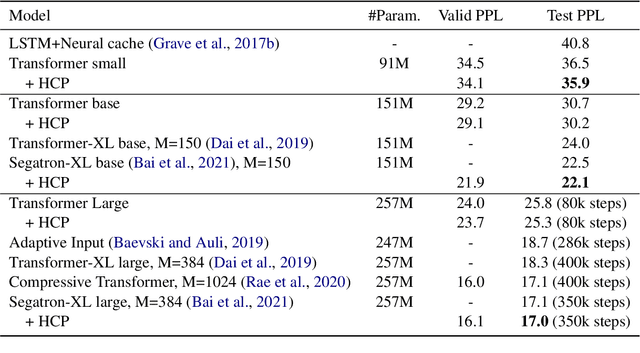
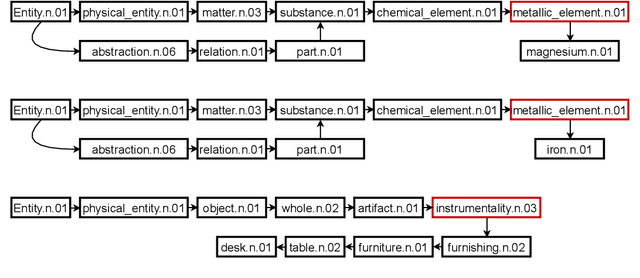
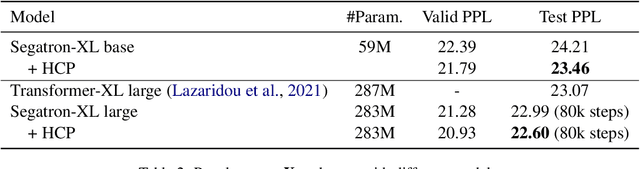
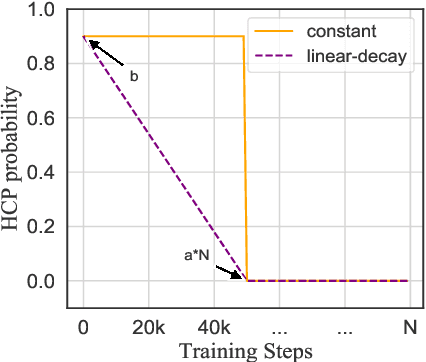
Class-based language models (LMs) have been long devised to address context sparsity in $n$-gram LMs. In this study, we revisit this approach in the context of neural LMs. We hypothesize that class-based prediction leads to an implicit context aggregation for similar words and thus can improve generalization for rare words. We map words that have a common WordNet hypernym to the same class and train large neural LMs by gradually annealing from predicting the class to token prediction during training. Empirically, this curriculum learning strategy consistently improves perplexity over various large, highly-performant state-of-the-art Transformer-based models on two datasets, WikiText-103 and Arxiv. Our analysis shows that the performance improvement is achieved without sacrificing performance on rare words. Finally, we document other attempts that failed to yield empirical gains, and discuss future directions for the adoption of class-based LMs on a larger scale.
A$^3$T: Alignment-Aware Acoustic and Text Pretraining for Speech Synthesis and Editing
Mar 18, 2022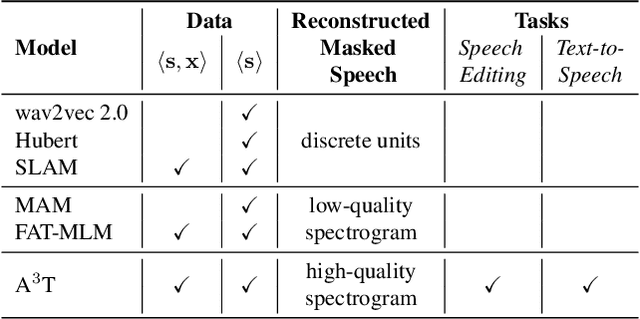
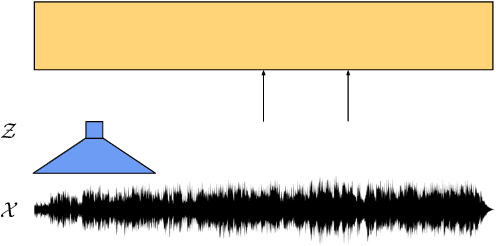
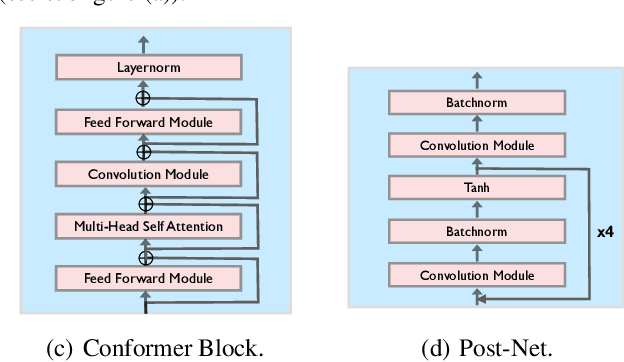

Recently, speech representation learning has improved many speech-related tasks such as speech recognition, speech classification, and speech-to-text translation. However, all the above tasks are in the direction of speech understanding, but for the inverse direction, speech synthesis, the potential of representation learning is yet to be realized, due to the challenging nature of generating high-quality speech. To address this problem, we propose our framework, Alignment-Aware Acoustic-Text Pretraining (A$^3$T), which reconstructs masked acoustic signals with text input and acoustic-text alignment during training. In this way, the pretrained model can generate high quality of reconstructed spectrogram, which can be applied to the speech editing and unseen speaker TTS directly. Experiments show A$^3$T outperforms SOTA models on speech editing, and improves multi-speaker speech synthesis without the external speaker verification model.
A Scalable Graph-Theoretic Distributed Framework for Cooperative Multi-Agent Reinforcement Learning
Mar 01, 2022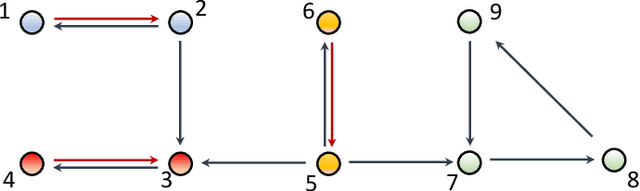
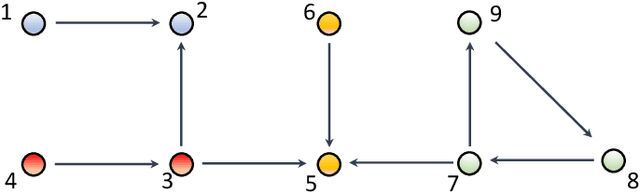
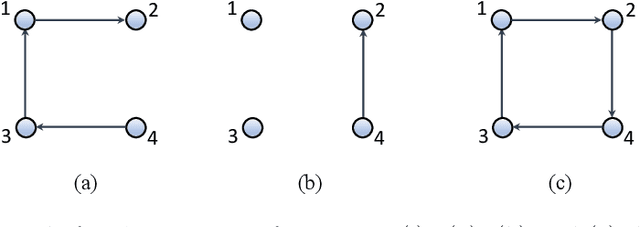
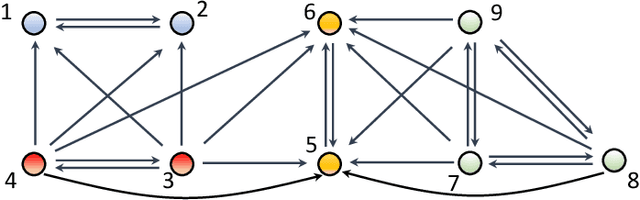
The main challenge of large-scale cooperative multi-agent reinforcement learning (MARL) is two-fold: (i) the RL algorithm is desired to be distributed due to limited resource for each individual agent; (ii) issues on convergence or computational complexity emerge due to the curse of dimensionality. Unfortunately, most of existing distributed RL references only focus on ensuring that the individual policy-seeking process of each agent is based on local information, but fail to solve the scalability issue induced by high dimensions of the state and action spaces when facing large-scale networks. In this paper, we propose a general distributed framework for cooperative MARL by utilizing the structures of graphs involved in this problem. We introduce three graphs in MARL, namely, the coordination graph, the observation graph and the reward graph. Based on these three graphs, and a given communication graph, we propose two distributed RL approaches. The first approach utilizes the inherent decomposability property of the problem itself, whose efficiency depends on the structures of the aforementioned four graphs, and is able to produce a high performance under specific graphical conditions. The second approach provides an approximate solution and is applicable for any graphs. Here the approximation error depends on an artificially designed index. The choice of this index is a trade-off between minimizing the approximation error and reducing the computational complexity. Simulations show that our RL algorithms have a significantly improved scalability to large-scale MASs compared with centralized and consensus-based distributed RL algorithms.