 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHao Sun
Propagation Map Reconstruction via Interpolation Assisted Matrix Completion
Jul 27, 2022
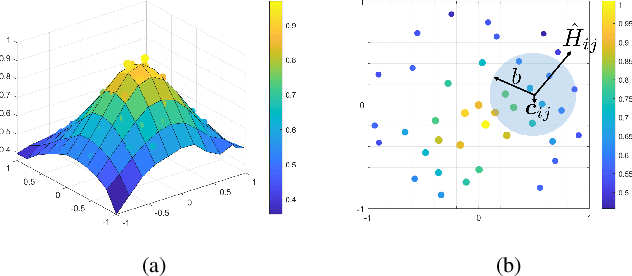
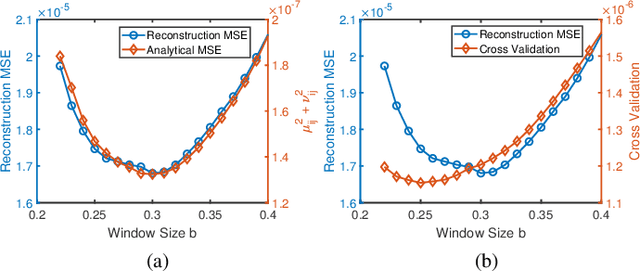
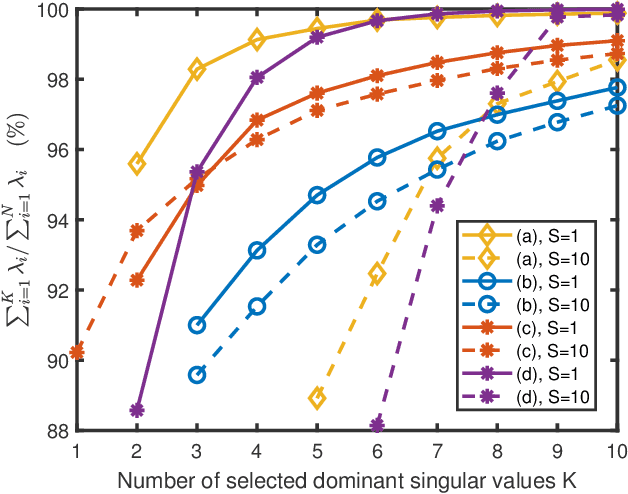
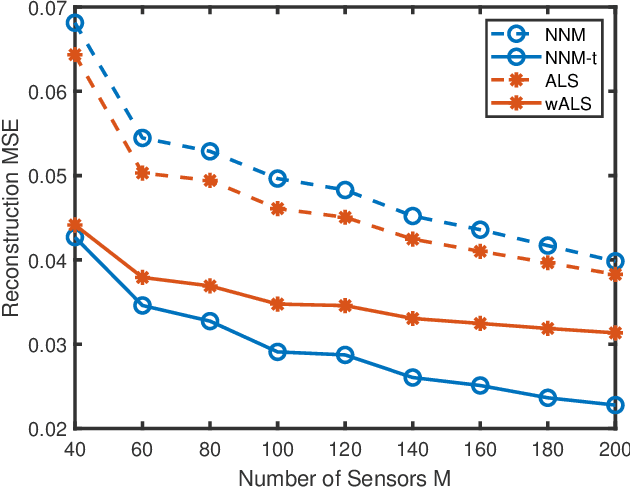
Constructing a propagation map from a set of scattered measurements finds important applications in many areas, such as localization, spectrum monitoring and management. Classical interpolation-type methods have poor performance in regions with very sparse measurements. Recent advance in matrix completion has the potential to reconstruct a propagation map from sparse measurements, but the spatial resolution is limited. This paper proposes to integrate interpolation with matrix completion to exploit both the spatial correlation and the potential low rank structure of the propagation map. The proposed method first enriches matrix observations using interpolation, and develops the statistics of the interpolation error based on a local polynomial regression model. Then, two uncertainty aware matrix completion algorithms are developed to exploit the interpolation error statistics. It is numerically demonstrated that the proposed method significantly reduces the mean squared error (MSE) of propagation map reconstruction by 50% from Kriging and other state-of-the-art schemes in the regime of very sparse sensor measurements, where the baseline schemes will need to at least double the number of measurements to achieve the same MSE.
A Survey on Collaborative DNN Inference for Edge Intelligence
Jul 16, 2022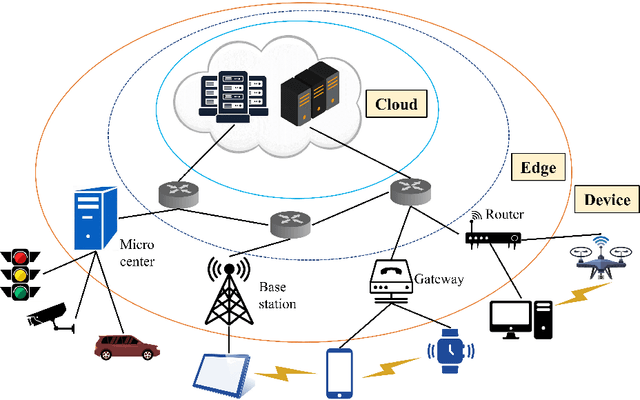
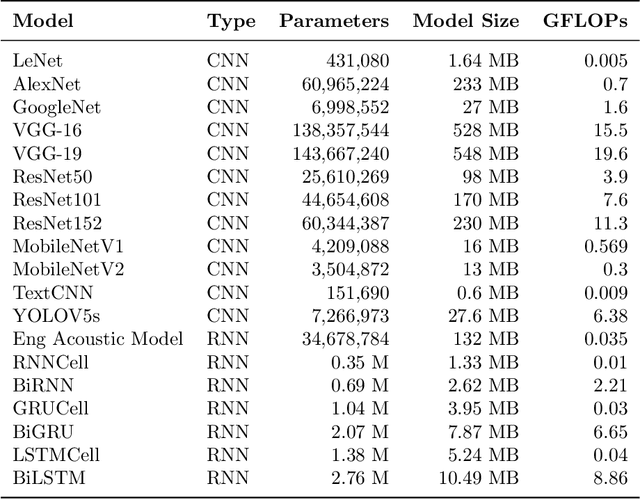
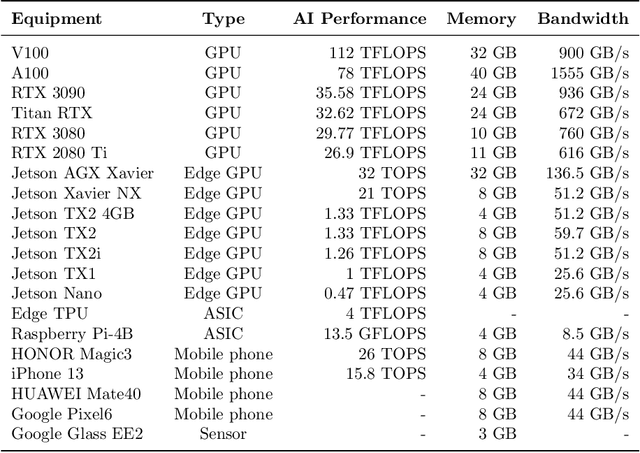
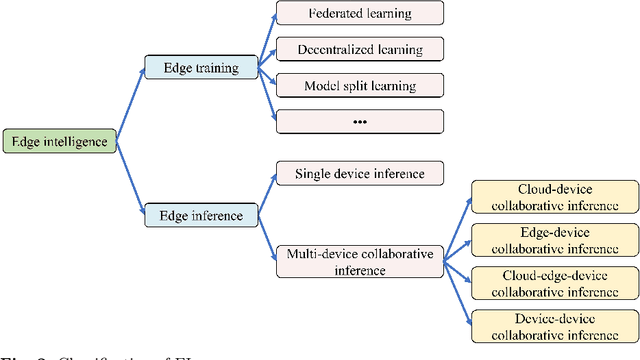
With the vigorous development of artificial intelligence (AI), the intelligent applications based on deep neural network (DNN) change people's lifestyles and the production efficiency. However, the huge amount of computation and data generated from the network edge becomes the major bottleneck, and traditional cloud-based computing mode has been unable to meet the requirements of real-time processing tasks. To solve the above problems, by embedding AI model training and inference capabilities into the network edge, edge intelligence (EI) becomes a cutting-edge direction in the field of AI. Furthermore, collaborative DNN inference among the cloud, edge, and end device provides a promising way to boost the EI. Nevertheless, at present, EI oriented collaborative DNN inference is still in its early stage, lacking a systematic classification and discussion of existing research efforts. Thus motivated, we have made a comprehensive investigation on the recent studies about EI oriented collaborative DNN inference. In this paper, we firstly review the background and motivation of EI. Then, we classify four typical collaborative DNN inference paradigms for EI, and analyze the characteristics and key technologies of them. Finally, we summarize the current challenges of collaborative DNN inference, discuss the future development trend and provide the future research direction.
DAUX: a Density-based Approach for Uncertainty eXplanations
Jul 11, 2022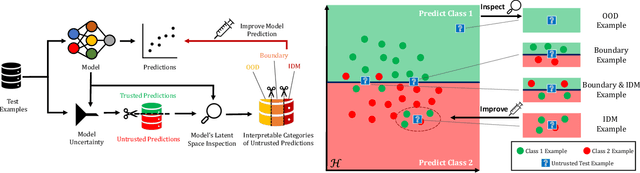
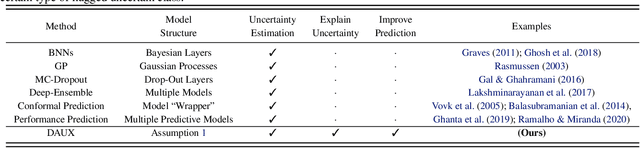

Uncertainty quantification (UQ) is essential for creating trustworthy machine learning models. Recent years have seen a steep rise in UQ methods that can flag suspicious examples, however, it is often unclear what exactly these methods identify. In this work, we propose an assumption-light method for interpreting UQ models themselves. We introduce the confusion density matrix -- a kernel-based approximation of the misclassification density -- and use this to categorize suspicious examples identified by a given UQ method into three classes: out-of-distribution (OOD) examples, boundary (Bnd) examples, and examples in regions of high in-distribution misclassification (IDM). Through extensive experiments, we shed light on existing UQ methods and show that the cause of the uncertainty differs across models. Additionally, we show how the proposed framework can make use of the categorized examples to improve predictive performance.
A Neural Corpus Indexer for Document Retrieval
Jun 06, 2022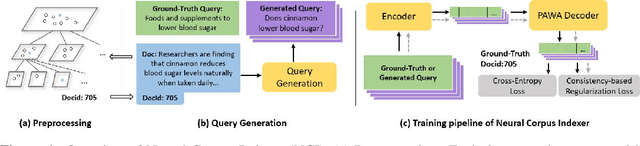
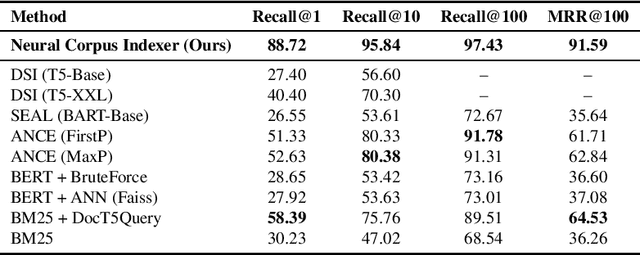
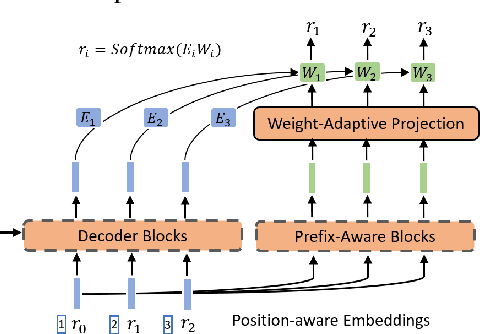
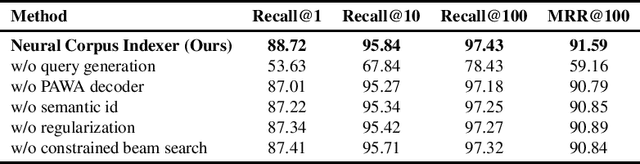
Current state-of-the-art document retrieval solutions mainly follow an index-retrieve paradigm, where the index is hard to be optimized for the final retrieval target. In this paper, we aim to show that an end-to-end deep neural network unifying training and indexing stages can significantly improve the recall performance of traditional methods. To this end, we propose Neural Corpus Indexer (NCI), a sequence-to-sequence network that generates relevant document identifiers directly for a designated query. To optimize the recall performance of NCI, we invent a prefix-aware weight-adaptive decoder architecture, and leverage tailored techniques including query generation, semantic document identifiers and consistency-based regularization. Empirical studies demonstrated the superiority of NCI on a commonly used academic benchmark, achieving +51.9% relative improvement on NQ320k dataset compared to the best baseline.
Symbolic Physics Learner: Discovering governing equations via Monte Carlo tree search
May 26, 2022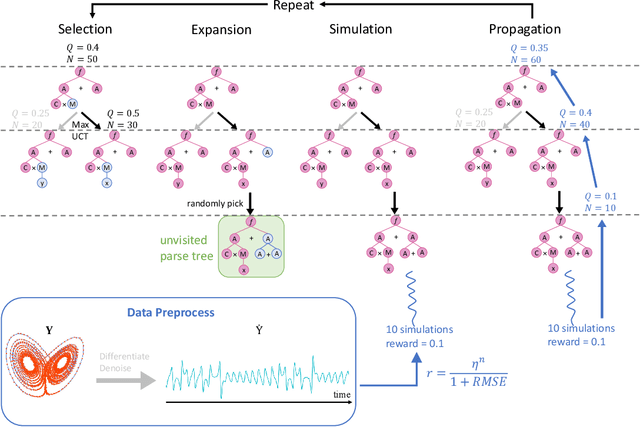
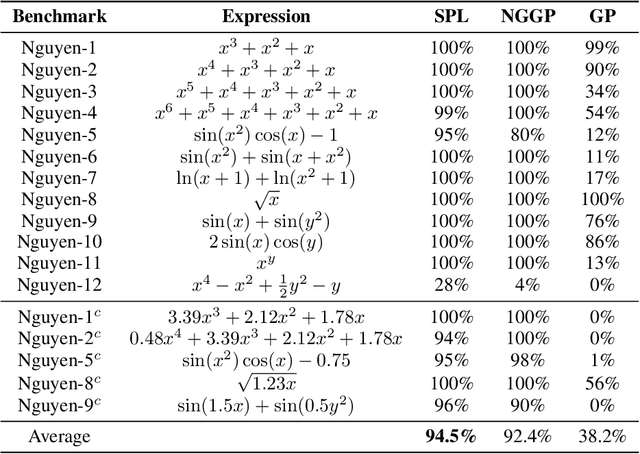
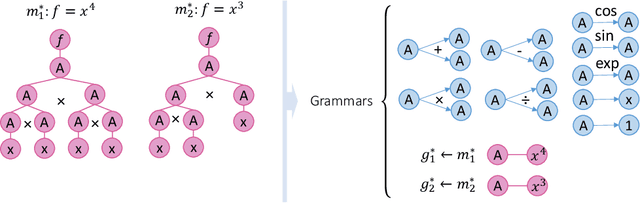

Nonlinear dynamics is ubiquitous in nature and commonly seen in various science and engineering disciplines. Distilling analytical expressions that govern nonlinear dynamics from limited data remains vital but challenging. To tackle this fundamental issue, we propose a novel Symbolic Physics Learner (SPL) machine to discover the mathematical structure of nonlinear dynamics. The key concept is to interpret mathematical operations and system state variables by computational rules and symbols, establish symbolic reasoning of mathematical formulas via expression trees, and employ a Monte Carlo tree search (MCTS) agent to explore optimal expression trees based on measurement data. The MCTS agent obtains an optimistic selection policy through the traversal of expression trees, featuring the one that maps to the arithmetic expression of underlying physics. Salient features of the proposed framework include search flexibility and enforcement of parsimony for discovered equations. The efficacy and superiority of the PSL machine are demonstrated by numerical examples, compared with state-of-the-art baselines.
Predicting parametric spatiotemporal dynamics by multi-resolution PDE structure-preserved deep learning
May 09, 2022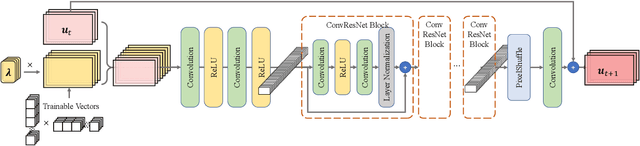
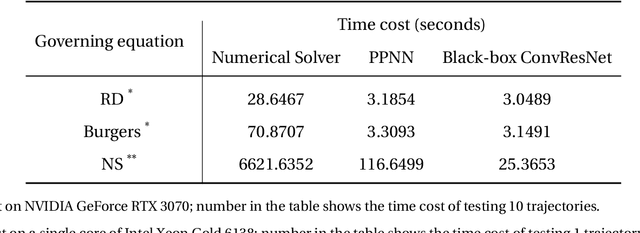
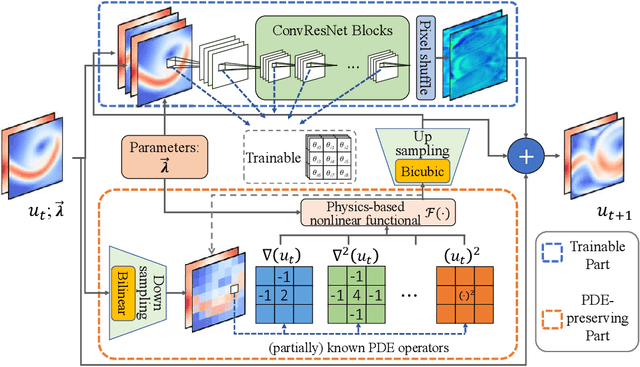
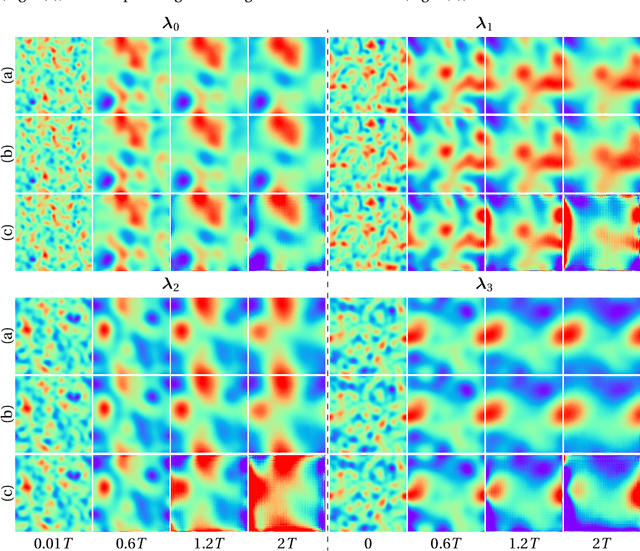
Although recent advances in deep learning (DL) have shown a great promise for learning physics exhibiting complex spatiotemporal dynamics, the high training cost, unsatisfying extrapolability for long-term predictions, and poor generalizability in out-of-sample regimes significantly limit their applications in science/engineering problems. A more promising way is to leverage available physical prior and domain knowledge to develop scientific DL models, known as physics-informed deep learning (PiDL). In most existing PiDL frameworks, e.g., physics-informed neural networks, the physics prior is mainly utilized to regularize neural network training by incorporating governing equations into the loss function in a soft manner. In this work, we propose a new direction to leverage physics prior knowledge by baking the mathematical structures of governing equations into the neural network architecture design. In particular, we develop a novel PDE-preserved neural network (PPNN) for rapidly predicting parametric spatiotemporal dynamics, given the governing PDEs are (partially) known. The discretized PDE structures are preserved in PPNN as convolutional residual network (ConvResNet) blocks, which are formulated in a multi-resolution setting. This physics-inspired learning architecture design endows PPNN with excellent generalizability and long-term prediction accuracy compared to the state-of-the-art black-box ConvResNet baseline. The effectiveness and merit of the proposed methods have been demonstrated over a handful of spatiotemporal dynamical systems governed by unsteady PDEs, including reaction-diffusion, Burgers', and Navier-Stokes equations.
Distilling Governing Laws and Source Input for Dynamical Systems from Videos
May 03, 2022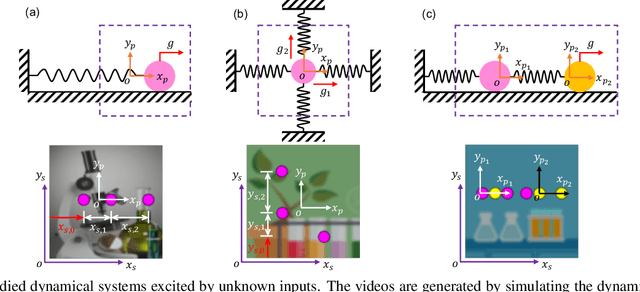
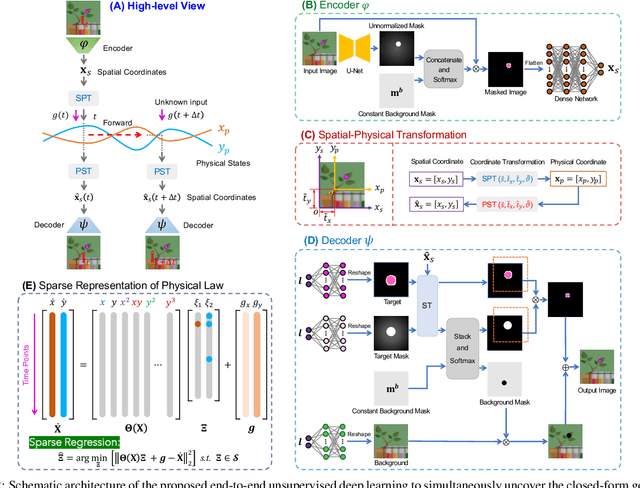
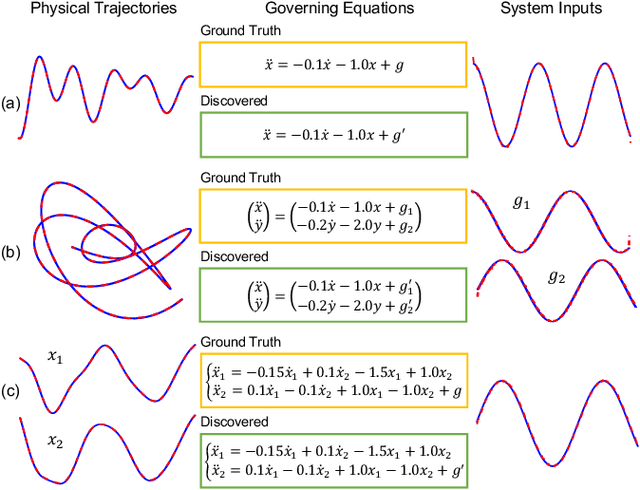
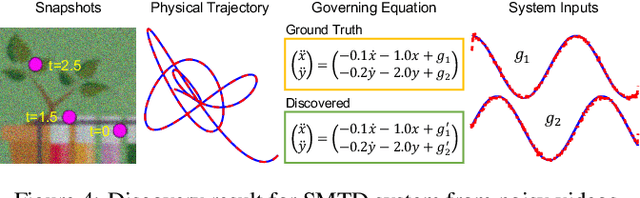
Distilling interpretable physical laws from videos has led to expanded interest in the computer vision community recently thanks to the advances in deep learning, but still remains a great challenge. This paper introduces an end-to-end unsupervised deep learning framework to uncover the explicit governing equations of dynamics presented by moving object(s), based on recorded videos. Instead in the pixel (spatial) coordinate system of image space, the physical law is modeled in a regressed underlying physical coordinate system where the physical states follow potential explicit governing equations. A numerical integrator-based sparse regression module is designed and serves as a physical constraint to the autoencoder and coordinate system regression, and, in the meanwhile, uncover the parsimonious closed-form governing equations from the learned physical states. Experiments on simulated dynamical scenes show that the proposed method is able to distill closed-form governing equations and simultaneously identify unknown excitation input for several dynamical systems recorded by videos, which fills in the gap in literature where no existing methods are available and applicable for solving this type of problem.
* 7 pages, 6 figures, IJCAI-2022. arXiv admin note: text overlap with arXiv:2106.04776
A Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
Distill-VQ: Learning Retrieval Oriented Vector Quantization By Distilling Knowledge from Dense Embeddings
Apr 01, 2022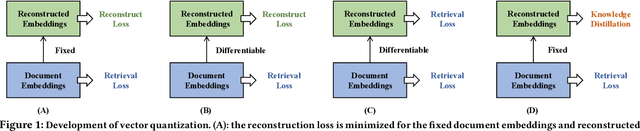
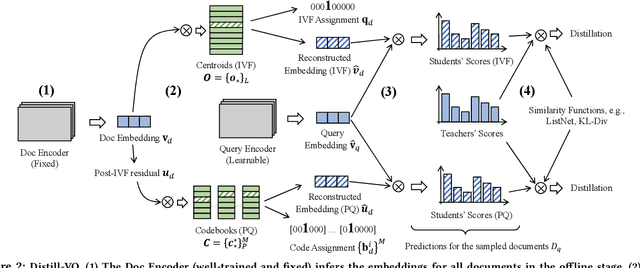
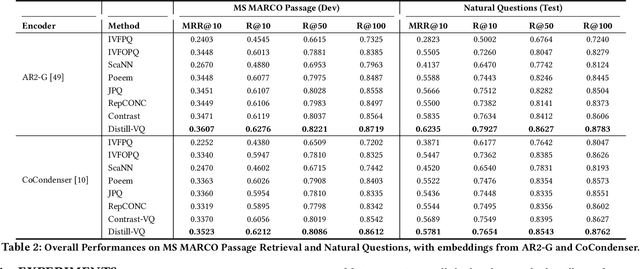
Vector quantization (VQ) based ANN indexes, such as Inverted File System (IVF) and Product Quantization (PQ), have been widely applied to embedding based document retrieval thanks to the competitive time and memory efficiency. Originally, VQ is learned to minimize the reconstruction loss, i.e., the distortions between the original dense embeddings and the reconstructed embeddings after quantization. Unfortunately, such an objective is inconsistent with the goal of selecting ground-truth documents for the input query, which may cause severe loss of retrieval quality. Recent works identify such a defect, and propose to minimize the retrieval loss through contrastive learning. However, these methods intensively rely on queries with ground-truth documents, whose performance is limited by the insufficiency of labeled data. In this paper, we propose Distill-VQ, which unifies the learning of IVF and PQ within a knowledge distillation framework. In Distill-VQ, the dense embeddings are leveraged as "teachers", which predict the query's relevance to the sampled documents. The VQ modules are treated as the "students", which are learned to reproduce the predicted relevance, such that the reconstructed embeddings may fully preserve the retrieval result of the dense embeddings. By doing so, Distill-VQ is able to derive substantial training signals from the massive unlabeled data, which significantly contributes to the retrieval quality. We perform comprehensive explorations for the optimal conduct of knowledge distillation, which may provide useful insights for the learning of VQ based ANN index. We also experimentally show that the labeled data is no longer a necessity for high-quality vector quantization, which indicates Distill-VQ's strong applicability in practice.
EVA2.0: Investigating Open-Domain Chinese Dialogue Systems with Large-Scale Pre-Training
Mar 17, 2022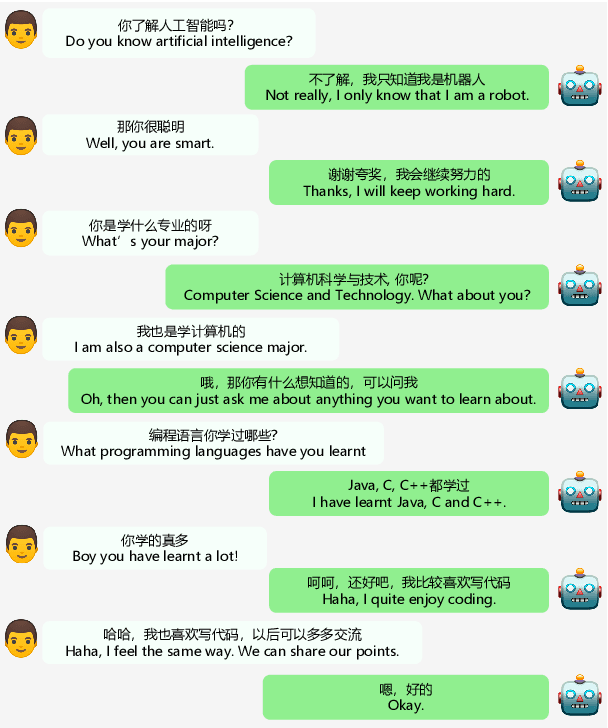


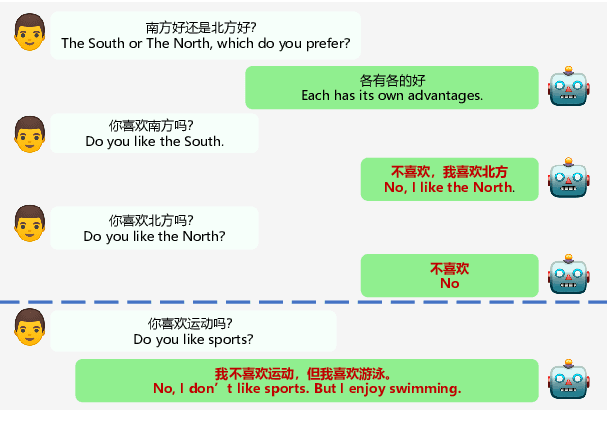
Large-scale pre-training has shown remarkable performance in building open-domain dialogue systems. However, previous works mainly focus on showing and evaluating the conversational performance of the released dialogue model, ignoring the discussion of some key factors towards a powerful human-like chatbot, especially in Chinese scenarios. In this paper, we conduct extensive experiments to investigate these under-explored factors, including data quality control, model architecture designs, training approaches, and decoding strategies. We propose EVA2.0, a large-scale pre-trained open-domain Chinese dialogue model with 2.8 billion parameters, and make our models and code publicly available. To our knowledge, EVA2.0 is the largest open-source Chinese dialogue model. Automatic and human evaluations show that our model significantly outperforms other open-source counterparts. We also discuss the limitations of this work by presenting some failure cases and pose some future directions.