 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOGNet: Towards a Global Oil and Gas Infrastructure Database using Deep Learning on Remotely Sensed Imagery
Nov 14, 2020
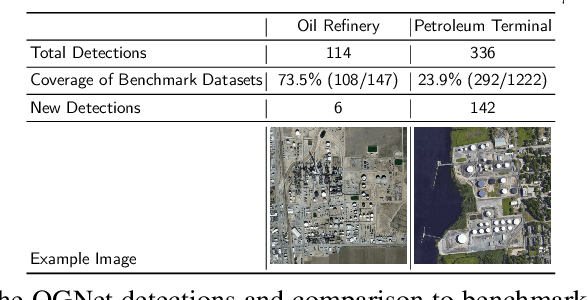
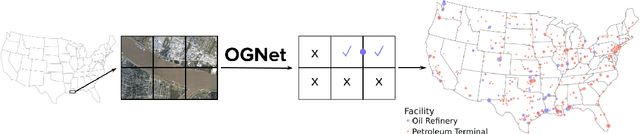
At least a quarter of the warming that the Earth is experiencing today is due to anthropogenic methane emissions. There are multiple satellites in orbit and planned for launch in the next few years which can detect and quantify these emissions; however, to attribute methane emissions to their sources on the ground, a comprehensive database of the locations and characteristics of emission sources worldwide is essential. In this work, we develop deep learning algorithms that leverage freely available high-resolution aerial imagery to automatically detect oil and gas infrastructure, one of the largest contributors to global methane emissions. We use the best algorithm, which we call OGNet, together with expert review to identify the locations of oil refineries and petroleum terminals in the U.S. We show that OGNet detects many facilities which are not present in four standard public datasets of oil and gas infrastructure. All detected facilities are associated with characteristics known to contribute to methane emissions, including the infrastructure type and the number of storage tanks. The data curated and produced in this study is freely available at http://stanfordmlgroup.github.io/projects/ognet .
ForestNet: Classifying Drivers of Deforestation in Indonesia using Deep Learning on Satellite Imagery
Nov 11, 2020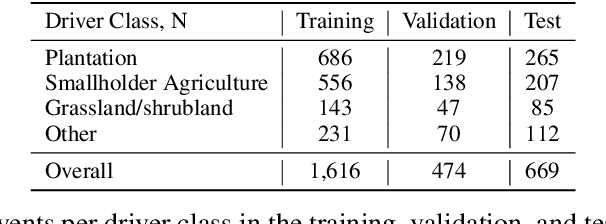
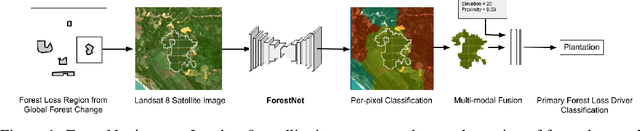
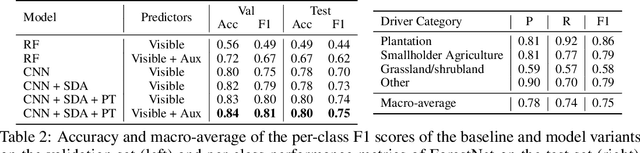
Characterizing the processes leading to deforestation is critical to the development and implementation of targeted forest conservation and management policies. In this work, we develop a deep learning model called ForestNet to classify the drivers of primary forest loss in Indonesia, a country with one of the highest deforestation rates in the world. Using satellite imagery, ForestNet identifies the direct drivers of deforestation in forest loss patches of any size. We curate a dataset of Landsat 8 satellite images of known forest loss events paired with driver annotations from expert interpreters. We use the dataset to train and validate the models and demonstrate that ForestNet substantially outperforms other standard driver classification approaches. In order to support future research on automated approaches to deforestation driver classification, the dataset curated in this study is publicly available at https://stanfordmlgroup.github.io/projects/forestnet .
Short-Term Solar Irradiance Forecasting Using Calibrated Probabilistic Models
Oct 14, 2020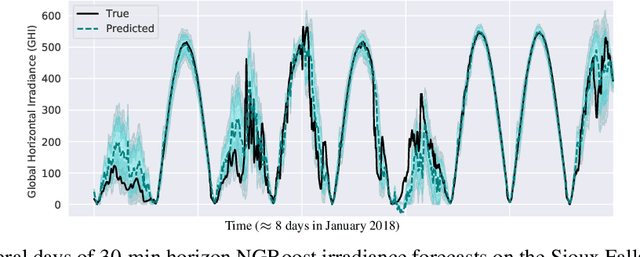
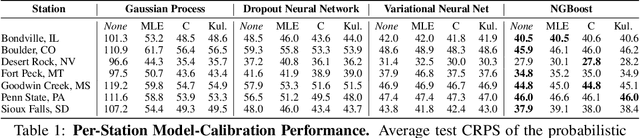
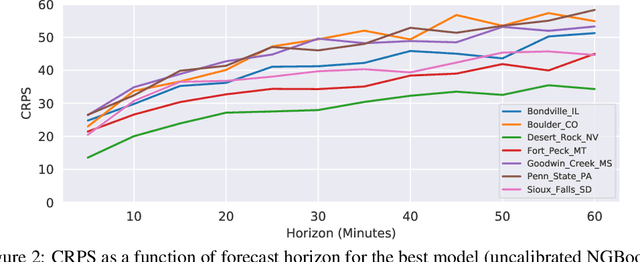
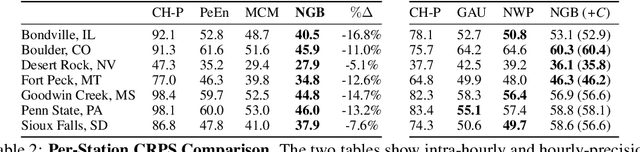
Advancing probabilistic solar forecasting methods is essential to supporting the integration of solar energy into the electricity grid. In this work, we develop a variety of state-of-the-art probabilistic models for forecasting solar irradiance. We investigate the use of post-hoc calibration techniques for ensuring well-calibrated probabilistic predictions. We train and evaluate the models using public data from seven stations in the SURFRAD network, and demonstrate that the best model, NGBoost, achieves higher performance at an intra-hourly resolution than the best benchmark solar irradiance forecasting model across all stations. Further, we show that NGBoost with CRUDE post-hoc calibration achieves comparable performance to a numerical weather prediction model on hourly-resolution forecasting.
Effective Data Fusion with Generalized Vegetation Index: Evidence from Land Cover Segmentation in Agriculture
May 07, 2020

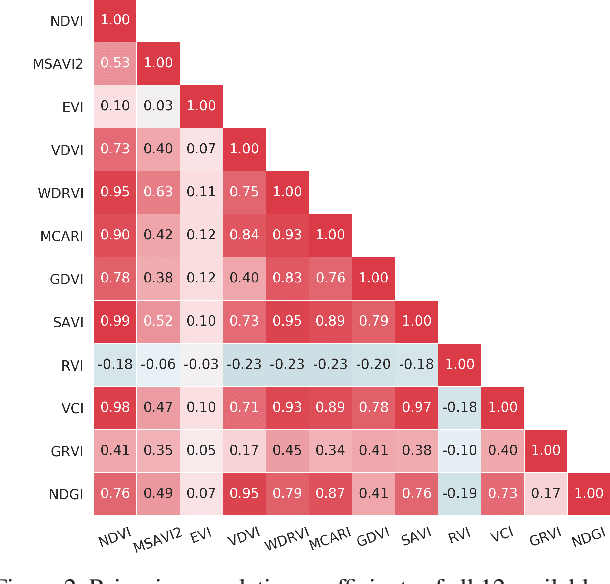
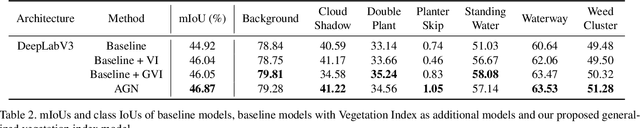
How can we effectively leverage the domain knowledge from remote sensing to better segment agriculture land cover from satellite images? In this paper, we propose a novel, model-agnostic, data-fusion approach for vegetation-related computer vision tasks. Motivated by the various Vegetation Indices (VIs), which are introduced by domain experts, we systematically reviewed the VIs that are widely used in remote sensing and their feasibility to be incorporated in deep neural networks. To fully leverage the Near-Infrared channel, the traditional Red-Green-Blue channels, and Vegetation Index or its variants, we propose a Generalized Vegetation Index (GVI), a lightweight module that can be easily plugged into many neural network architectures to serve as an additional information input. To smoothly train models with our GVI, we developed an Additive Group Normalization (AGN) module that does not require extra parameters of the prescribed neural networks. Our approach has improved the IoUs of vegetation-related classes by 0.9-1.3 percent and consistently improves the overall mIoU by 2 percent on our baseline.
The 1st Agriculture-Vision Challenge: Methods and Results
Apr 23, 2020
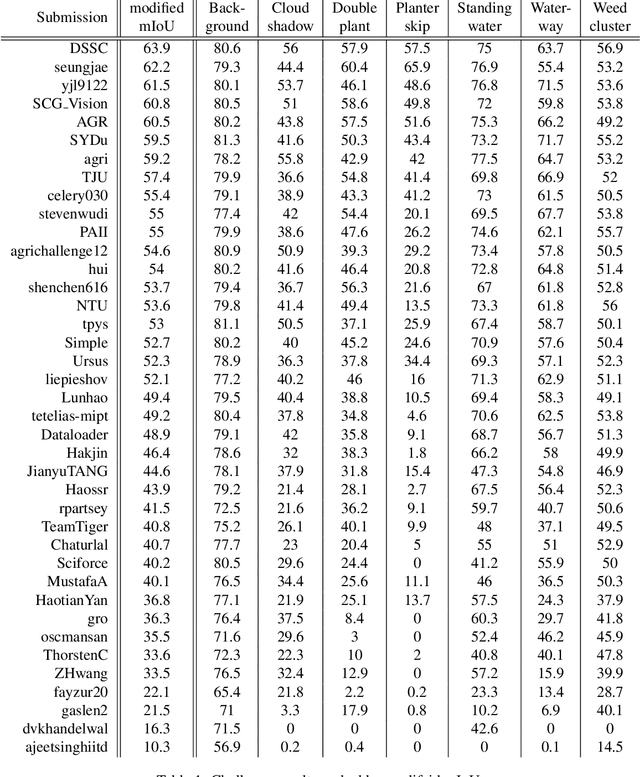
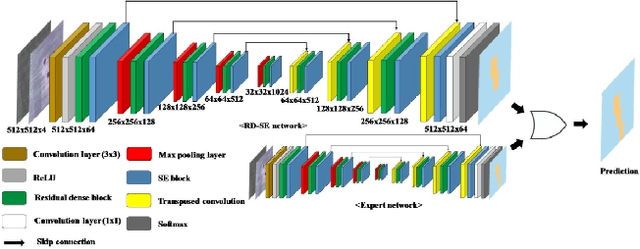
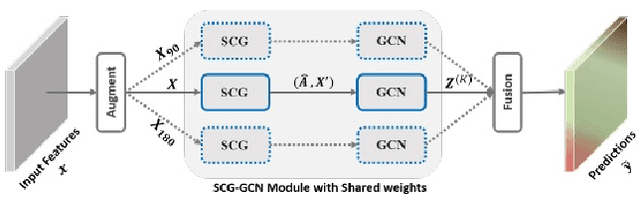
The first Agriculture-Vision Challenge aims to encourage research in developing novel and effective algorithms for agricultural pattern recognition from aerial images, especially for the semantic segmentation task associated with our challenge dataset. Around 57 participating teams from various countries compete to achieve state-of-the-art in aerial agriculture semantic segmentation. The Agriculture-Vision Challenge Dataset was employed, which comprises of 21,061 aerial and multi-spectral farmland images. This paper provides a summary of notable methods and results in the challenge. Our submission server and leaderboard will continue to open for researchers that are interested in this challenge dataset and task; the link can be found here.
PIV-Based 3D Fluid Flow Reconstruction Using Light Field Camera
Apr 15, 2019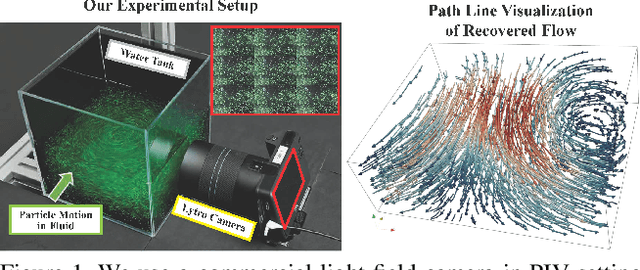

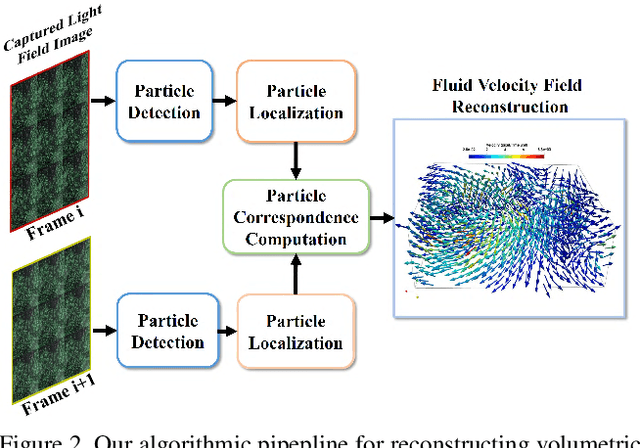
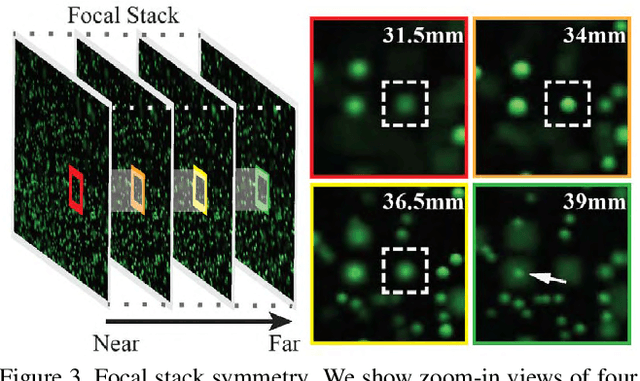
Particle Imaging Velocimetry (PIV) estimates the flow of fluid by analyzing the motion of injected particles. The problem is challenging as the particles lie at different depths but have similar appearance and tracking a large number of particles is particularly difficult. In this paper, we present a PIV solution that uses densely sampled light field to reconstruct and track 3D particles. We exploit the refocusing capability and focal symmetry constraint of the light field for reliable particle depth estimation. We further propose a new motion-constrained optical flow estimation scheme by enforcing local motion rigidity and the Navier-Stoke constraint. Comprehensive experiments on synthetic and real experiments show that using a single light field camera, our technique can recover dense and accurate 3D fluid flows in small to medium volumes.
Generic Multiview Visual Tracking
Apr 04, 2019
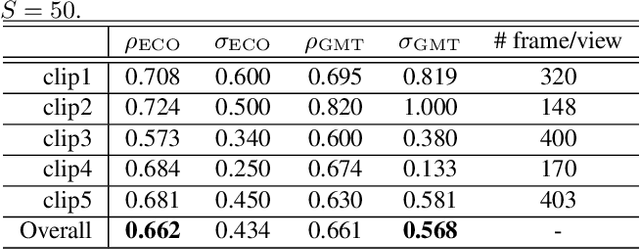
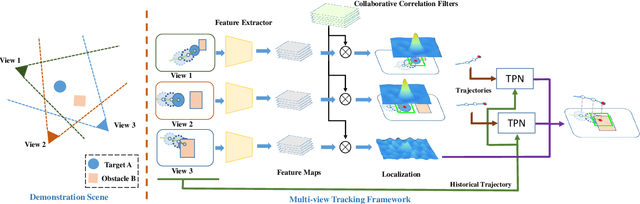
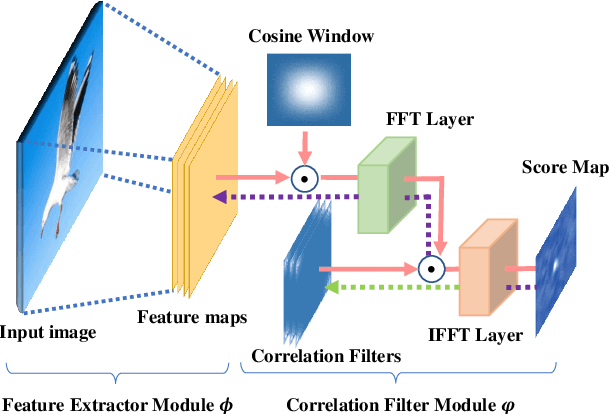
Recent progresses in visual tracking have greatly improved the tracking performance. However, challenges such as occlusion and view change remain obstacles in real world deployment. A natural solution to these challenges is to use multiple cameras with multiview inputs, though existing systems are mostly limited to specific targets (e.g. human), static cameras, and/or camera calibration. To break through these limitations, we propose a generic multiview tracking (GMT) framework that allows camera movement, while requiring neither specific object model nor camera calibration. A key innovation in our framework is a cross-camera trajectory prediction network (TPN), which implicitly and dynamically encodes camera geometric relations, and hence addresses missing target issues such as occlusion. Moreover, during tracking, we assemble information across different cameras to dynamically update a novel collaborative correlation filter (CCF), which is shared among cameras to achieve robustness against view change. The two components are integrated into a correlation filter tracking framework, where the features are trained offline using existing single view tracking datasets. For evaluation, we first contribute a new generic multiview tracking dataset (GMTD) with careful annotations, and then run experiments on GMTD and the PETS2009 datasets. On both datasets, the proposed GMT algorithm shows clear advantages over state-of-the-art ones.