 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling and Predicting Multi-Turn Answer Instability in Large Language Models
Nov 12, 2025



As large language models (LLMs) are adopted in an increasingly wide range of applications, user-model interactions have grown in both frequency and scale. Consequently, research has focused on evaluating the robustness of LLMs, an essential quality for real-world tasks. In this paper, we employ simple multi-turn follow-up prompts to evaluate models' answer changes, model accuracy dynamics across turns with Markov chains, and examine whether linear probes can predict these changes. Our results show significant vulnerabilities in LLM robustness: a simple "Think again" prompt led to an approximate 10% accuracy drop for Gemini 1.5 Flash over nine turns, while combining this prompt with a semantically equivalent reworded question caused a 7.5% drop for Claude 3.5 Haiku. Additionally, we find that model accuracy across turns can be effectively modeled using Markov chains, enabling the prediction of accuracy probabilities over time. This allows for estimation of the model's stationary (long-run) accuracy, which we find to be on average approximately 8% lower than its first-turn accuracy for Gemini 1.5 Flash. Our results from a model's hidden states also reveal evidence that linear probes can help predict future answer changes. Together, these results establish stationary accuracy as a principled robustness metric for interactive settings and expose the fragility of models under repeated questioning. Addressing this instability will be essential for deploying LLMs in high-stakes and interactive settings where consistent reasoning is as important as initial accuracy.
ForestNet: Classifying Drivers of Deforestation in Indonesia using Deep Learning on Satellite Imagery
Nov 11, 2020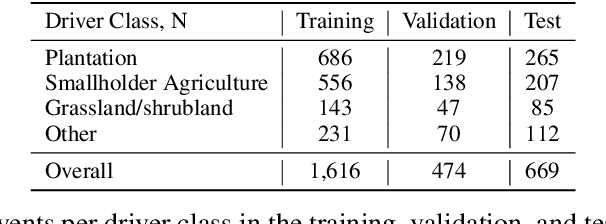
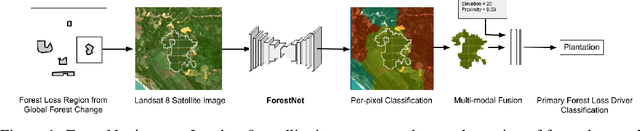
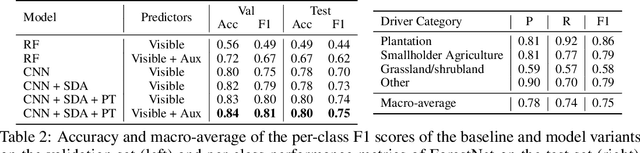
Characterizing the processes leading to deforestation is critical to the development and implementation of targeted forest conservation and management policies. In this work, we develop a deep learning model called ForestNet to classify the drivers of primary forest loss in Indonesia, a country with one of the highest deforestation rates in the world. Using satellite imagery, ForestNet identifies the direct drivers of deforestation in forest loss patches of any size. We curate a dataset of Landsat 8 satellite images of known forest loss events paired with driver annotations from expert interpreters. We use the dataset to train and validate the models and demonstrate that ForestNet substantially outperforms other standard driver classification approaches. In order to support future research on automated approaches to deforestation driver classification, the dataset curated in this study is publicly available at https://stanfordmlgroup.github.io/projects/forestnet .