 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGood SFT Optimizes for SFT, Better SFT Prepares for Reinforcement Learning
Feb 01, 2026Post-training of reasoning LLMs is a holistic process that typically consists of an offline SFT stage followed by an online reinforcement learning (RL) stage. However, SFT is often optimized in isolation to maximize SFT performance alone. We show that, after identical RL training, models initialized from stronger SFT checkpoints can significantly underperform those initialized from weaker ones. We attribute this to a mismatch typical in current SFT-RL pipelines: the distribution that generates the offline SFT data can differ substantially from the policy optimized during online RL, which learns from its own rollouts. We propose PEAR (Policy Evaluation-inspired Algorithm for Offline Learning Loss Re-weighting), an SFT-stage method that corrects this mismatch and better prepares the model for RL. PEAR uses importance sampling to reweight the SFT loss, with three variants operating at the token, block, and sequence levels. It can be used to augment standard SFT objectives and incurs little additional training overhead once probabilities for the offline data are collected. We conduct controlled experiments on verifiable reasoning games and mathematical reasoning tasks on Qwen 2.5 and 3 and DeepSeek-distilled models. PEAR consistently improves post-RL performance over canonical SFT, with pass at 8 gains up to a 14.6 percent on AIME2025. Our results suggest that PEAR is an effective step toward more holistic LLM post-training by designing and evaluating SFT with downstream RL in mind rather than in isolation.
On the Paradoxical Interference between Instruction-Following and Task Solving
Jan 29, 2026Instruction following aims to align Large Language Models (LLMs) with human intent by specifying explicit constraints on how tasks should be performed. However, we reveal a counterintuitive phenomenon: instruction following can paradoxically interfere with LLMs' task-solving capability. We propose a metric, SUSTAINSCORE, to quantify the interference of instruction following with task solving. It measures task performance drop after inserting into the instruction a self-evident constraint, which is naturally met by the original successful model output and extracted from it. Experiments on current LLMs in mathematics, multi-hop QA, and code generation show that adding the self-evident constraints leads to substantial performance drops, even for advanced models such as Claude-Sonnet-4.5. We validate the generality of the interference across constraint types and scales. Furthermore, we identify common failure patterns, and by investigating the mechanisms of interference, we observe that failed cases allocate significantly more attention to constraints compared to successful ones. Finally, we use SUSTAINSCORE to conduct an initial investigation into how distinct post-training paradigms affect the interference, presenting empirical observations on current alignment strategies. We will release our code and data to facilitate further research
Latent Chain-of-Thought as Planning: Decoupling Reasoning from Verbalization
Jan 29, 2026Chain-of-Thought (CoT) empowers Large Language Models (LLMs) to tackle complex problems, but remains constrained by the computational cost and reasoning path collapse when grounded in discrete token spaces. Recent latent reasoning approaches attempt to optimize efficiency by performing reasoning within continuous hidden states. However, these methods typically operate as opaque end-to-end mappings from explicit reasoning steps to latent states, and often require a pre-defined number of latent steps during inference. In this work, we introduce PLaT (Planning with Latent Thoughts), a framework that reformulates latent reasoning as planning by fundamentally decouple reasoning from verbalization. We model reasoning as a deterministic trajectory of latent planning states, while a separate Decoder grounds these thoughts into text when necessary. This decoupling allows the model to dynamically determine when to terminate reasoning rather than relying on fixed hyperparameters. Empirical results on mathematical benchmarks reveal a distinct trade-off: while PLaT achieves lower greedy accuracy than baselines, it demonstrates superior scalability in terms of reasoning diversity. This indicates that PLaT learns a robust, broader solution space, offering a transparent and scalable foundation for inference-time search.
MuVaC: AVariational Causal Framework for Multimodal Sarcasm Understanding in Dialogues
Jan 28, 2026The prevalence of sarcasm in multimodal dialogues on the social platforms presents a crucial yet challenging task for understanding the true intent behind online content. Comprehensive sarcasm analysis requires two key aspects: Multimodal Sarcasm Detection (MSD) and Multimodal Sarcasm Explanation (MuSE). Intuitively, the act of detection is the result of the reasoning process that explains the sarcasm. Current research predominantly focuses on addressing either MSD or MuSE as a single task. Even though some recent work has attempted to integrate these tasks, their inherent causal dependency is often overlooked. To bridge this gap, we propose MuVaC, a variational causal inference framework that mimics human cognitive mechanisms for understanding sarcasm, enabling robust multimodal feature learning to jointly optimize MSD and MuSE. Specifically, we first model MSD and MuSE from the perspective of structural causal models, establishing variational causal pathways to define the objectives for joint optimization. Next, we design an alignment-then-fusion approach to integrate multimodal features, providing robust fusion representations for sarcasm detection and explanation generation. Finally, we enhance the reasoning trustworthiness by ensuring consistency between detection results and explanations. Experimental results demonstrate the superiority of MuVaC in public datasets, offering a new perspective for understanding multimodal sarcasm.
Gaming the Judge: Unfaithful Chain-of-Thought Can Undermine Agent Evaluation
Jan 21, 2026Large language models (LLMs) are increasingly used as judges to evaluate agent performance, particularly in non-verifiable settings where judgments rely on agent trajectories including chain-of-thought (CoT) reasoning. This paradigm implicitly assumes that the agent's CoT faithfully reflects both its internal reasoning and the underlying environment state. We show this assumption is brittle: LLM judges are highly susceptible to manipulation of agent reasoning traces. By systematically rewriting agent CoTs while holding actions and observations fixed, we demonstrate that manipulated reasoning alone can inflate false positive rates of state-of-the-art VLM judges by up to 90% across 800 trajectories spanning diverse web tasks. We study manipulation strategies spanning style-based approaches that alter only the presentation of reasoning and content-based approaches that fabricate signals of task progress, and find that content-based manipulations are consistently more effective. We evaluate prompting-based techniques and scaling judge-time compute, which reduce but do not fully eliminate susceptibility to manipulation. Our findings reveal a fundamental vulnerability in LLM-based evaluation and highlight the need for judging mechanisms that verify reasoning claims against observable evidence.
Watching, Reasoning, and Searching: A Video Deep Research Benchmark on Open Web for Agentic Video Reasoning
Jan 11, 2026In real-world video question answering scenarios, videos often provide only localized visual cues, while verifiable answers are distributed across the open web; models therefore need to jointly perform cross-frame clue extraction, iterative retrieval, and multi-hop reasoning-based verification. To bridge this gap, we construct the first video deep research benchmark, VideoDR. VideoDR centers on video-conditioned open-domain video question answering, requiring cross-frame visual anchor extraction, interactive web retrieval, and multi-hop reasoning over joint video-web evidence; through rigorous human annotation and quality control, we obtain high-quality video deep research samples spanning six semantic domains. We evaluate multiple closed-source and open-source multimodal large language models under both the Workflow and Agentic paradigms, and the results show that Agentic is not consistently superior to Workflow: its gains depend on a model's ability to maintain the initial video anchors over long retrieval chains. Further analysis indicates that goal drift and long-horizon consistency are the core bottlenecks. In sum, VideoDR provides a systematic benchmark for studying video agents in open-web settings and reveals the key challenges for next-generation video deep research agents.
Generalization of RLVR Using Causal Reasoning as a Testbed
Dec 23, 2025Reinforcement learning with verifiable rewards (RLVR) has emerged as a promising paradigm for post-training large language models (LLMs) on complex reasoning tasks. Yet, the conditions under which RLVR yields robust generalization remain poorly understood. This paper provides an empirical study of RLVR generalization in the setting of probabilistic inference over causal graphical models. This setting offers two natural axes along which to examine generalization: (i) the level of the probabilistic query -- associational, interventional, or counterfactual -- and (ii) the structural complexity of the query, measured by the size of its relevant subgraph. We construct datasets of causal graphs and queries spanning these difficulty axes and fine-tune Qwen-2.5-Instruct models using RLVR or supervised fine-tuning (SFT). We vary both the model scale (3B-32B) and the query level included in training. We find that RLVR yields stronger within-level and across-level generalization than SFT, but only for specific combinations of model size and training query level. Further analysis shows that RLVR's effectiveness depends on the model's initial reasoning competence. With sufficient initial competence, RLVR improves an LLM's marginalization strategy and reduces errors in intermediate probability calculations, producing substantial accuracy gains, particularly on more complex queries. These findings show that RLVR can improve specific causal reasoning subskills, with its benefits emerging only when the model has sufficient initial competence.
MixKVQ: Query-Aware Mixed-Precision KV Cache Quantization for Long-Context Reasoning
Dec 22, 2025Long Chain-of-Thought (CoT) reasoning has significantly advanced the capabilities of Large Language Models (LLMs), but this progress is accompanied by substantial memory and latency overhead from the extensive Key-Value (KV) cache. Although KV cache quantization is a promising compression technique, existing low-bit quantization methods often exhibit severe performance degradation on complex reasoning tasks. Fixed-precision quantization struggles to handle outlier channels in the key cache, while current mixed-precision strategies fail to accurately identify components requiring high-precision representation. We find that an effective low-bit KV cache quantization strategy must consider two factors: a key channel's intrinsic quantization difficulty and its relevance to the query. Based on this insight, we propose MixKVQ, a novel plug-and-play method that introduces a lightweight, query-aware algorithm to identify and preserve critical key channels that need higher precision, while applying per-token quantization for value cache. Experiments on complex reasoning datasets demonstrate that our approach significantly outperforms existing low-bit methods, achieving performance comparable to a full-precision baseline at a substantially reduced memory footprint.
Adaptation of Agentic AI
Dec 22, 2025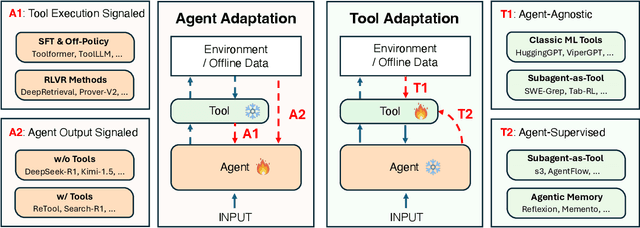
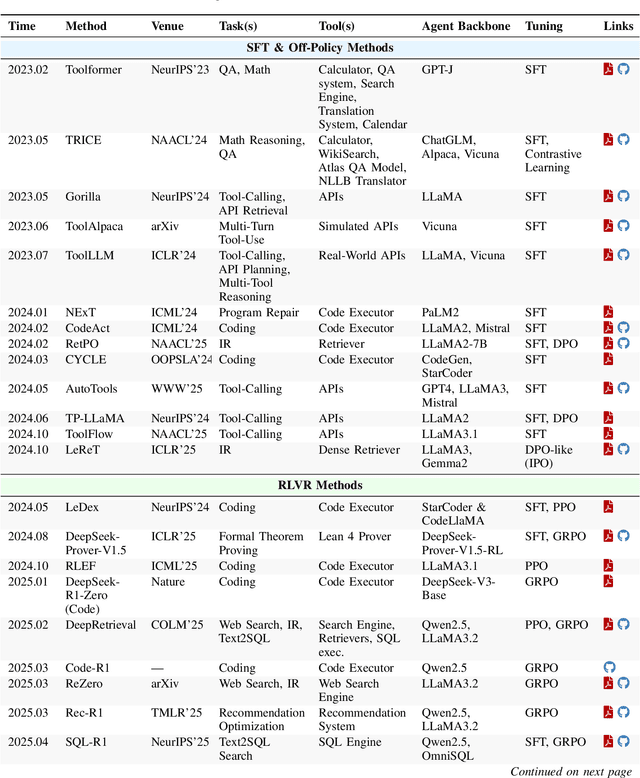
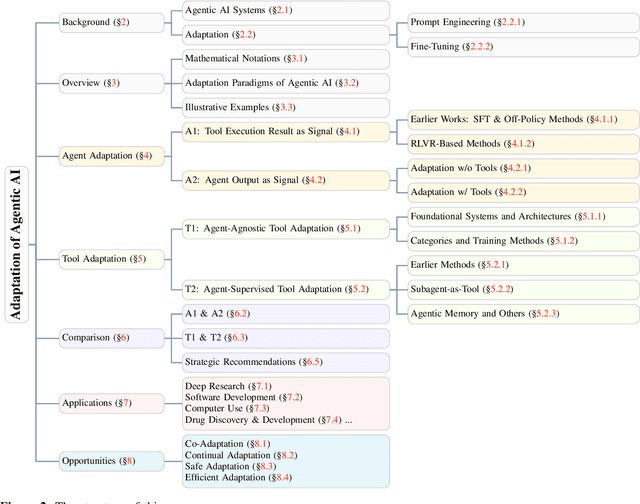
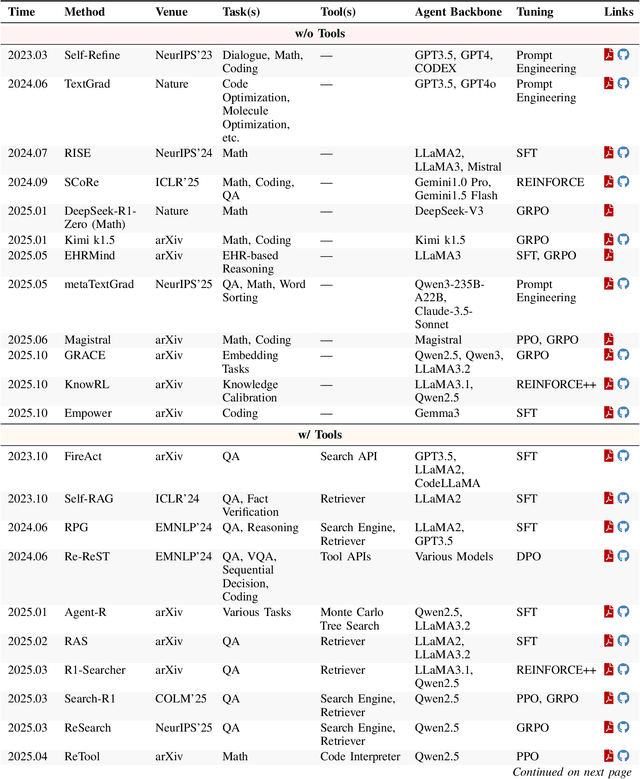
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
Do Not Merge My Model! Safeguarding Open-Source LLMs Against Unauthorized Model Merging
Nov 13, 2025Model merging has emerged as an efficient technique for expanding large language models (LLMs) by integrating specialized expert models. However, it also introduces a new threat: model merging stealing, where free-riders exploit models through unauthorized model merging. Unfortunately, existing defense mechanisms fail to provide effective protection. Specifically, we identify three critical protection properties that existing methods fail to simultaneously satisfy: (1) proactively preventing unauthorized merging; (2) ensuring compatibility with general open-source settings; (3) achieving high security with negligible performance loss. To address the above issues, we propose MergeBarrier, a plug-and-play defense that proactively prevents unauthorized merging. The core design of MergeBarrier is to disrupt the Linear Mode Connectivity (LMC) between the protected model and its homologous counterparts, thereby eliminating the low-loss path required for effective model merging. Extensive experiments show that MergeBarrier effectively prevents model merging stealing with negligible accuracy loss.