 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathCoder-VL: Bridging Vision and Code for Enhanced Multimodal Mathematical Reasoning
May 15, 2025Natural language image-caption datasets, widely used for training Large Multimodal Models, mainly focus on natural scenarios and overlook the intricate details of mathematical figures that are critical for problem-solving, hindering the advancement of current LMMs in multimodal mathematical reasoning. To this end, we propose leveraging code as supervision for cross-modal alignment, since code inherently encodes all information needed to generate corresponding figures, establishing a precise connection between the two modalities. Specifically, we co-develop our image-to-code model and dataset with model-in-the-loop approach, resulting in an image-to-code model, FigCodifier and ImgCode-8.6M dataset, the largest image-code dataset to date. Furthermore, we utilize FigCodifier to synthesize novel mathematical figures and then construct MM-MathInstruct-3M, a high-quality multimodal math instruction fine-tuning dataset. Finally, we present MathCoder-VL, trained with ImgCode-8.6M for cross-modal alignment and subsequently fine-tuned on MM-MathInstruct-3M for multimodal math problem solving. Our model achieves a new open-source SOTA across all six metrics. Notably, it surpasses GPT-4o and Claude 3.5 Sonnet in the geometry problem-solving subset of MathVista, achieving improvements of 8.9% and 9.2%. The dataset and models will be released at https://github.com/mathllm/MathCoder.
Adaptive Markup Language Generation for Contextually-Grounded Visual Document Understanding
May 08, 2025



Visual Document Understanding has become essential with the increase of text-rich visual content. This field poses significant challenges due to the need for effective integration of visual perception and textual comprehension, particularly across diverse document types with complex layouts. Moreover, existing fine-tuning datasets for this domain often fall short in providing the detailed contextual information for robust understanding, leading to hallucinations and limited comprehension of spatial relationships among visual elements. To address these challenges, we propose an innovative pipeline that utilizes adaptive generation of markup languages, such as Markdown, JSON, HTML, and TiKZ, to build highly structured document representations and deliver contextually-grounded responses. We introduce two fine-grained structured datasets: DocMark-Pile, comprising approximately 3.8M pretraining data pairs for document parsing, and DocMark-Instruct, featuring 624k fine-tuning data annotations for grounded instruction following. Extensive experiments demonstrate that our proposed model significantly outperforms existing state-of-theart MLLMs across a range of visual document understanding benchmarks, facilitating advanced reasoning and comprehension capabilities in complex visual scenarios. Our code and models are released at https://github. com/Euphoria16/DocMark.
WebGen-Bench: Evaluating LLMs on Generating Interactive and Functional Websites from Scratch
May 06, 2025
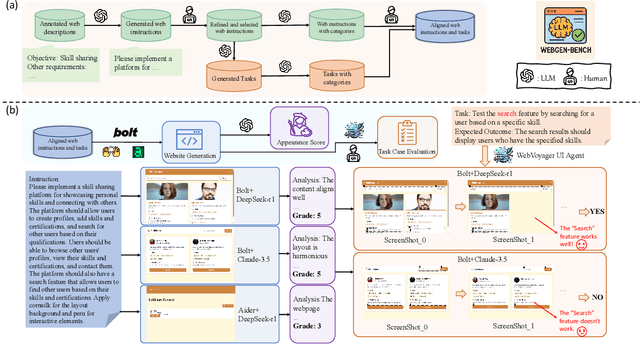
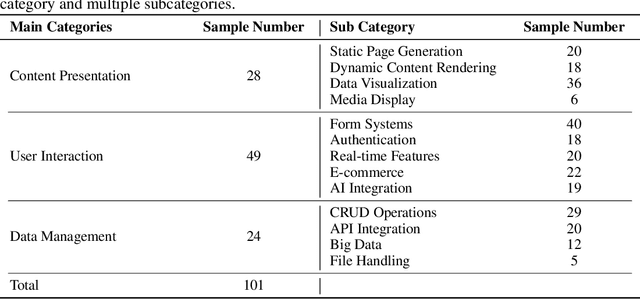
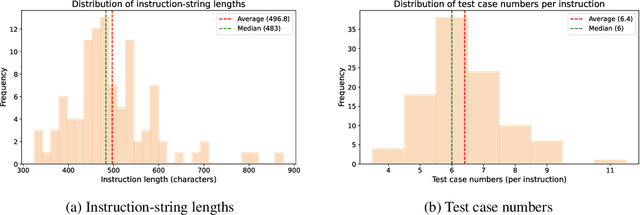
LLM-based agents have demonstrated great potential in generating and managing code within complex codebases. In this paper, we introduce WebGen-Bench, a novel benchmark designed to measure an LLM-based agent's ability to create multi-file website codebases from scratch. It contains diverse instructions for website generation, created through the combined efforts of human annotators and GPT-4o. These instructions span three major categories and thirteen minor categories, encompassing nearly all important types of web applications. To assess the quality of the generated websites, we use GPT-4o to generate test cases targeting each functionality described in the instructions, and then manually filter, adjust, and organize them to ensure accuracy, resulting in 647 test cases. Each test case specifies an operation to be performed on the website and the expected result after the operation. To automate testing and improve reproducibility, we employ a powerful web-navigation agent to execute tests on the generated websites and determine whether the observed responses align with the expected results. We evaluate three high-performance code-agent frameworks, Bolt.diy, OpenHands, and Aider, using multiple proprietary and open-source LLMs as engines. The best-performing combination, Bolt.diy powered by DeepSeek-R1, achieves only 27.8\% accuracy on the test cases, highlighting the challenging nature of our benchmark. Additionally, we construct WebGen-Instruct, a training set consisting of 6,667 website-generation instructions. Training Qwen2.5-Coder-32B-Instruct on Bolt.diy trajectories generated from a subset of this training set achieves an accuracy of 38.2\%, surpassing the performance of the best proprietary model.
Robust Full-Space Physical Layer Security for STAR-RIS-Aided Wireless Networks: Eavesdropper with Uncertain Location and Channel
Mar 15, 2025A robust full-space physical layer security (PLS) transmission scheme is proposed in this paper considering the full-space wiretapping challenge of wireless networks supported by simultaneous transmitting and reflecting reconfigurable intelligent surface (STAR-RIS). Different from the existing schemes, the proposed PLS scheme takes account of the uncertainty on the eavesdropper's position within the 360$^\circ$ service area offered by the STAR-RIS. Specifically, the large system analytical method is utilized to derive the asymptotic expression of the average security rate achieved by the security user, considering that the base station (BS) only has the statistical information of the eavesdropper's channel state information (CSI) and the uncertainty of its location. To evaluate the effectiveness of the proposed PLS scheme, we first formulate an optimization problem aimed at maximizing the weighted sum rate of the security user and the public user. This optimization is conducted under the power allocation constraint, and some practical limitations for STAR-RIS implementation, through jointly designing the active and passive beamforming variables. A novel iterative algorithm based on the minimum mean-square error (MMSE) and cross-entropy optimization (CEO) methods is proposed to effectively address the established non-convex optimization problem with discrete variables. Simulation results indicate that the proposed robust PLS scheme can effectively mitigate the information leakage across the entire coverage area of the STAR-RIS-assisted system, leading to superior performance gain when compared to benchmark schemes encompassing traditional RIS-aided scheme.
Fluid Antenna System Empowering 5G NR
Mar 07, 2025Fluid antenna system (FAS) is an emerging technology that uses the new form of shape- and position-reconfigurable antennas to empower the physical layer for wireless communications. Prior studies on FAS were however limited to narrowband channels. Motivated by this, this paper addresses the integration of FAS in the fifth generation (5G) orthogonal frequency division multiplexing (OFDM) framework to address the challenges posed by wideband communications. We propose the framework of the wideband FAS OFDM system that includes a novel port selection matrix. Then we derive the achievable rate expression and design the adaptive modulation and coding (AMC) scheme based on the rate. Extensive link-level simulation results demonstrate striking improvements of FAS in the wideband channels, underscoring the potential of FAS in future wireless communications.
ReaderLM-v2: Small Language Model for HTML to Markdown and JSON
Mar 03, 2025



We present ReaderLM-v2, a compact 1.5 billion parameter language model designed for efficient web content extraction. Our model processes documents up to 512K tokens, transforming messy HTML into clean Markdown or JSON formats with high accuracy -- making it an ideal tool for grounding large language models. The model's effectiveness results from two key innovations: (1) a three-stage data synthesis pipeline that generates high quality, diverse training data by iteratively drafting, refining, and critiquing web content extraction; and (2) a unified training framework combining continuous pre-training with multi-objective optimization. Intensive evaluation demonstrates that ReaderLM-v2 outperforms GPT-4o-2024-08-06 and other larger models by 15-20\% on carefully curated benchmarks, particularly excelling at documents exceeding 100K tokens, while maintaining significantly lower computational requirements.
AIR-Bench: Automated Heterogeneous Information Retrieval Benchmark
Dec 17, 2024



Evaluation plays a crucial role in the advancement of information retrieval (IR) models. However, current benchmarks, which are based on predefined domains and human-labeled data, face limitations in addressing evaluation needs for emerging domains both cost-effectively and efficiently. To address this challenge, we propose the Automated Heterogeneous Information Retrieval Benchmark (AIR-Bench). AIR-Bench is distinguished by three key features: 1) Automated. The testing data in AIR-Bench is automatically generated by large language models (LLMs) without human intervention. 2) Heterogeneous. The testing data in AIR-Bench is generated with respect to diverse tasks, domains and languages. 3) Dynamic. The domains and languages covered by AIR-Bench are constantly augmented to provide an increasingly comprehensive evaluation benchmark for community developers. We develop a reliable and robust data generation pipeline to automatically create diverse and high-quality evaluation datasets based on real-world corpora. Our findings demonstrate that the generated testing data in AIR-Bench aligns well with human-labeled testing data, making AIR-Bench a dependable benchmark for evaluating IR models. The resources in AIR-Bench are publicly available at https://github.com/AIR-Bench/AIR-Bench.
jina-clip-v2: Multilingual Multimodal Embeddings for Text and Images
Dec 11, 2024



Contrastive Language-Image Pretraining (CLIP) is a highly effective method for aligning images and texts in a shared embedding space. These models are widely used for tasks such as cross-modal information retrieval and multi-modal understanding. However, CLIP models often struggle with text-only tasks, underperforming compared to specialized text models. This performance disparity forces retrieval systems to rely on separate models for text-only and multi-modal tasks. In this work, we build upon our previous model, jina-clip-v1, by introducing a refined framework that utilizes multi-task, multi-stage contrastive learning across multiple languages, coupled with an improved training recipe to enhance text-only retrieval. The resulting model, jina-clip-v2, outperforms its predecessor on text-only and multimodal tasks, while adding multilingual support, better understanding of complex visual documents and efficiency gains thanks to Matryoshka Representation Learning and vector truncation. The model performs comparably to the state-of-the-art in both multilingual-multimodal and multilingual text retrieval benchmarks, addressing the challenge of unifying text-only and multi-modal retrieval systems.
MPBD-LSTM: A Predictive Model for Colorectal Liver Metastases Using Time Series Multi-phase Contrast-Enhanced CT Scans
Dec 02, 2024Colorectal cancer is a prevalent form of cancer, and many patients develop colorectal cancer liver metastasis (CRLM) as a result. Early detection of CRLM is critical for improving survival rates. Radiologists usually rely on a series of multi-phase contrast-enhanced computed tomography (CECT) scans done during follow-up visits to perform early detection of the potential CRLM. These scans form unique five-dimensional data (time, phase, and axial, sagittal, and coronal planes in 3D CT). Most of the existing deep learning models can readily handle four-dimensional data (e.g., time-series 3D CT images) and it is not clear how well they can be extended to handle the additional dimension of phase. In this paper, we build a dataset of time-series CECT scans to aid in the early diagnosis of CRLM, and build upon state-of-the-art deep learning techniques to evaluate how to best predict CRLM. Our experimental results show that a multi-plane architecture based on 3D bi-directional LSTM, which we call MPBD-LSTM, works best, achieving an area under curve (AUC) of 0.79. On the other hand, analysis of the results shows that there is still great room for further improvement.
BlueLM-V-3B: Algorithm and System Co-Design for Multimodal Large Language Models on Mobile Devices
Nov 16, 2024



The emergence and growing popularity of multimodal large language models (MLLMs) have significant potential to enhance various aspects of daily life, from improving communication to facilitating learning and problem-solving. Mobile phones, as essential daily companions, represent the most effective and accessible deployment platform for MLLMs, enabling seamless integration into everyday tasks. However, deploying MLLMs on mobile phones presents challenges due to limitations in memory size and computational capability, making it difficult to achieve smooth and real-time processing without extensive optimization. In this paper, we present BlueLM-V-3B, an algorithm and system co-design approach specifically tailored for the efficient deployment of MLLMs on mobile platforms. To be specific, we redesign the dynamic resolution scheme adopted by mainstream MLLMs and implement system optimization for hardware-aware deployment to optimize model inference on mobile phones. BlueLM-V-3B boasts the following key highlights: (1) Small Size: BlueLM-V-3B features a language model with 2.7B parameters and a vision encoder with 400M parameters. (2) Fast Speed: BlueLM-V-3B achieves a generation speed of 24.4 token/s on the MediaTek Dimensity 9300 processor with 4-bit LLM weight quantization. (3) Strong Performance: BlueLM-V-3B has attained the highest average score of 66.1 on the OpenCompass benchmark among models with $\leq$ 4B parameters and surpassed a series of models with much larger parameter sizes (e.g., MiniCPM-V-2.6, InternVL2-8B).