 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSINA: Improving Subgraph Extraction for Graph Invariant Learning via Graph Sinkhorn Attention
Feb 11, 2024Graph invariant learning (GIL) has been an effective approach to discovering the invariant relationships between graph data and its labels for different graph learning tasks under various distribution shifts. Many recent endeavors of GIL focus on extracting the invariant subgraph from the input graph for prediction as a regularization strategy to improve the generalization performance of graph learning. Despite their success, such methods also have various limitations in obtaining their invariant subgraphs. In this paper, we provide in-depth analyses of the drawbacks of existing works and propose corresponding principles of our invariant subgraph extraction: 1) the sparsity, to filter out the variant features, 2) the softness, for a broader solution space, and 3) the differentiability, for a soundly end-to-end optimization. To meet these principles in one shot, we leverage the Optimal Transport (OT) theory and propose a novel graph attention mechanism called Graph Sinkhorn Attention (GSINA). This novel approach serves as a powerful regularization method for GIL tasks. By GSINA, we are able to obtain meaningful, differentiable invariant subgraphs with controllable sparsity and softness. Moreover, GSINA is a general graph learning framework that could handle GIL tasks of multiple data grain levels. Extensive experiments on both synthetic and real-world datasets validate the superiority of our GSINA, which outperforms the state-of-the-art GIL methods by large margins on both graph-level tasks and node-level tasks. Our code is publicly available at \url{https://github.com/dingfangyu/GSINA}.
PRED: Pre-training via Semantic Rendering on LiDAR Point Clouds
Nov 08, 2023Pre-training is crucial in 3D-related fields such as autonomous driving where point cloud annotation is costly and challenging. Many recent studies on point cloud pre-training, however, have overlooked the issue of incompleteness, where only a fraction of the points are captured by LiDAR, leading to ambiguity during the training phase. On the other hand, images offer more comprehensive information and richer semantics that can bolster point cloud encoders in addressing the incompleteness issue inherent in point clouds. Yet, incorporating images into point cloud pre-training presents its own challenges due to occlusions, potentially causing misalignments between points and pixels. In this work, we propose PRED, a novel image-assisted pre-training framework for outdoor point clouds in an occlusion-aware manner. The main ingredient of our framework is a Birds-Eye-View (BEV) feature map conditioned semantic rendering, leveraging the semantics of images for supervision through neural rendering. We further enhance our model's performance by incorporating point-wise masking with a high mask ratio (95%). Extensive experiments demonstrate PRED's superiority over prior point cloud pre-training methods, providing significant improvements on various large-scale datasets for 3D perception tasks. Codes will be available at https://github.com/PRED4pc/PRED.
UniTR: A Unified and Efficient Multi-Modal Transformer for Bird's-Eye-View Representation
Aug 15, 2023Jointly processing information from multiple sensors is crucial to achieving accurate and robust perception for reliable autonomous driving systems. However, current 3D perception research follows a modality-specific paradigm, leading to additional computation overheads and inefficient collaboration between different sensor data. In this paper, we present an efficient multi-modal backbone for outdoor 3D perception named UniTR, which processes a variety of modalities with unified modeling and shared parameters. Unlike previous works, UniTR introduces a modality-agnostic transformer encoder to handle these view-discrepant sensor data for parallel modal-wise representation learning and automatic cross-modal interaction without additional fusion steps. More importantly, to make full use of these complementary sensor types, we present a novel multi-modal integration strategy by both considering semantic-abundant 2D perspective and geometry-aware 3D sparse neighborhood relations. UniTR is also a fundamentally task-agnostic backbone that naturally supports different 3D perception tasks. It sets a new state-of-the-art performance on the nuScenes benchmark, achieving +1.1 NDS higher for 3D object detection and +12.0 higher mIoU for BEV map segmentation with lower inference latency. Code will be available at https://github.com/Haiyang-W/UniTR .
DSVT: Dynamic Sparse Voxel Transformer with Rotated Sets
Jan 15, 2023Designing an efficient yet deployment-friendly 3D backbone to handle sparse point clouds is a fundamental problem in 3D object detection. Compared with the customized sparse convolution, the attention mechanism in Transformers is more appropriate for flexibly modeling long-range relationships and is easier to be deployed in real-world applications. However, due to the sparse characteristics of point clouds, it is non-trivial to apply a standard transformer on sparse points. In this paper, we present Dynamic Sparse Voxel Transformer (DSVT), a single-stride window-based voxel Transformer backbone for outdoor 3D object detection. In order to efficiently process sparse points in parallel, we propose Dynamic Sparse Window Attention, which partitions a series of local regions in each window according to its sparsity and then computes the features of all regions in a fully parallel manner. To allow the cross-set connection, we design a rotated set partitioning strategy that alternates between two partitioning configurations in consecutive self-attention layers. To support effective downsampling and better encode geometric information, we also propose an attention-style 3D pooling module on sparse points, which is powerful and deployment-friendly without utilizing any customized CUDA operations. Our model achieves state-of-the-art performance on large-scale Waymo Open Dataset with remarkable gains. More importantly, DSVT can be easily deployed by TensorRT with real-time inference speed (27Hz). Code will be available at \url{https://github.com/Haiyang-W/DSVT}.
CAGroup3D: Class-Aware Grouping for 3D Object Detection on Point Clouds
Oct 09, 2022
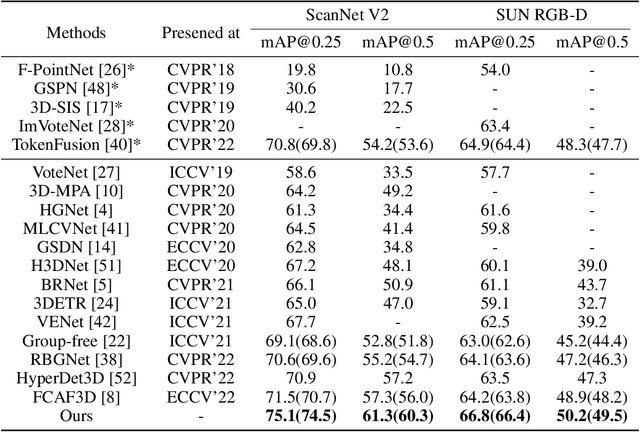
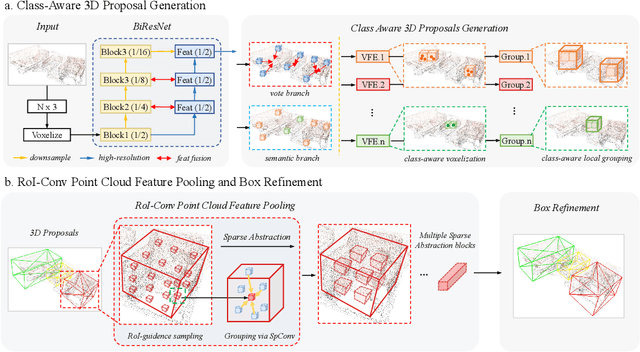

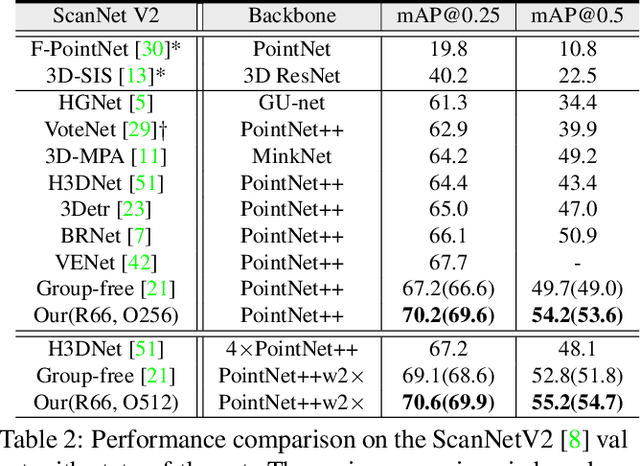
We present a novel two-stage fully sparse convolutional 3D object detection framework, named CAGroup3D. Our proposed method first generates some high-quality 3D proposals by leveraging the class-aware local group strategy on the object surface voxels with the same semantic predictions, which considers semantic consistency and diverse locality abandoned in previous bottom-up approaches. Then, to recover the features of missed voxels due to incorrect voxel-wise segmentation, we build a fully sparse convolutional RoI pooling module to directly aggregate fine-grained spatial information from backbone for further proposal refinement. It is memory-and-computation efficient and can better encode the geometry-specific features of each 3D proposal. Our model achieves state-of-the-art 3D detection performance with remarkable gains of +\textit{3.6\%} on ScanNet V2 and +\textit{2.6}\% on SUN RGB-D in term of mAP@0.25. Code will be available at https://github.com/Haiyang-W/CAGroup3D.
RBGNet: Ray-based Grouping for 3D Object Detection
Apr 05, 2022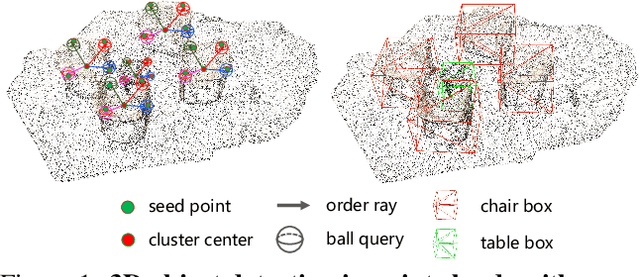

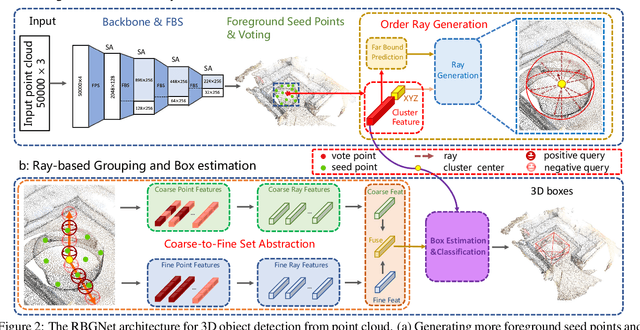
As a fundamental problem in computer vision, 3D object detection is experiencing rapid growth. To extract the point-wise features from the irregularly and sparsely distributed points, previous methods usually take a feature grouping module to aggregate the point features to an object candidate. However, these methods have not yet leveraged the surface geometry of foreground objects to enhance grouping and 3D box generation. In this paper, we propose the RBGNet framework, a voting-based 3D detector for accurate 3D object detection from point clouds. In order to learn better representations of object shape to enhance cluster features for predicting 3D boxes, we propose a ray-based feature grouping module, which aggregates the point-wise features on object surfaces using a group of determined rays uniformly emitted from cluster centers. Considering the fact that foreground points are more meaningful for box estimation, we design a novel foreground biased sampling strategy in downsample process to sample more points on object surfaces and further boost the detection performance. Our model achieves state-of-the-art 3D detection performance on ScanNet V2 and SUN RGB-D with remarkable performance gains. Code will be available at https://github.com/Haiyang-W/RBGNet.
Full-attention based Neural Architecture Search using Context Auto-regression
Nov 13, 2021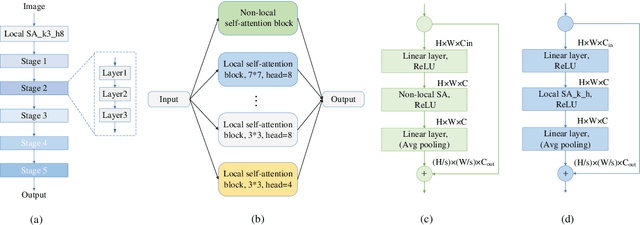
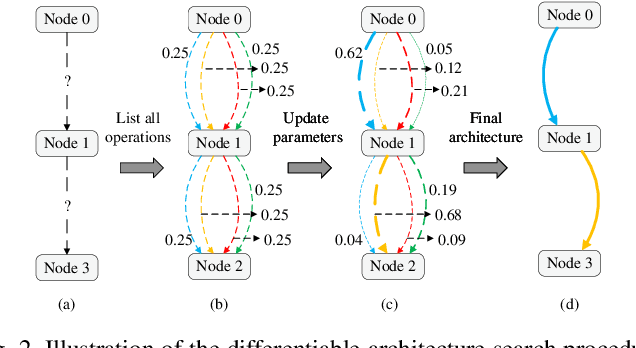
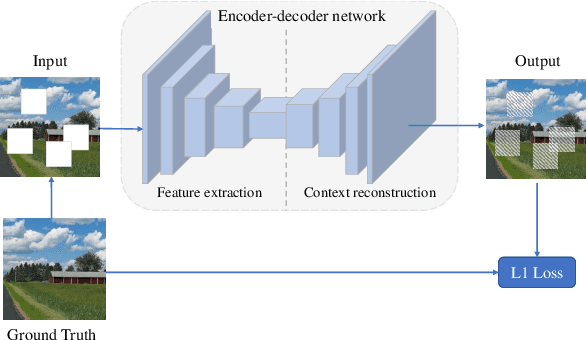
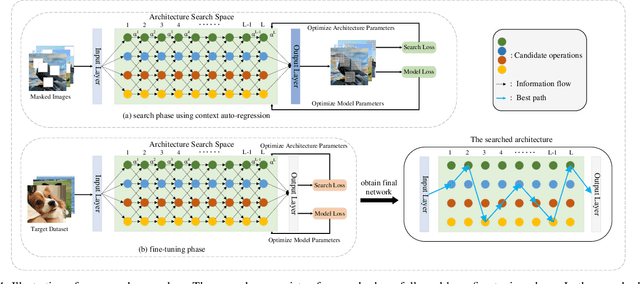
Self-attention architectures have emerged as a recent advancement for improving the performance of vision tasks. Manual determination of the architecture for self-attention networks relies on the experience of experts and cannot automatically adapt to various scenarios. Meanwhile, neural architecture search (NAS) has significantly advanced the automatic design of neural architectures. Thus, it is appropriate to consider using NAS methods to discover a better self-attention architecture automatically. However, it is challenging to directly use existing NAS methods to search attention networks because of the uniform cell-based search space and the lack of long-term content dependencies. To address this issue, we propose a full-attention based NAS method. More specifically, a stage-wise search space is constructed that allows various attention operations to be adopted for different layers of a network. To extract global features, a self-supervised search algorithm is proposed that uses context auto-regression to discover the full-attention architecture. To verify the efficacy of the proposed methods, we conducted extensive experiments on various learning tasks, including image classification, fine-grained image recognition, and zero-shot image retrieval. The empirical results show strong evidence that our method is capable of discovering high-performance, full-attention architectures while guaranteeing the required search efficiency.
Non-convex Distributionally Robust Optimization: Non-asymptotic Analysis
Oct 26, 2021
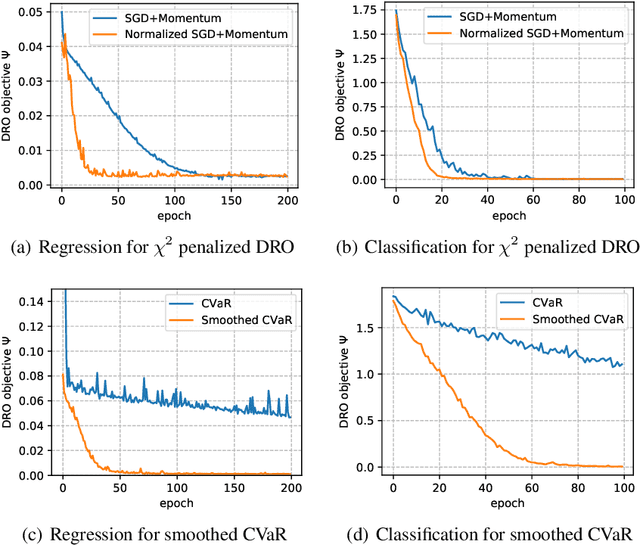


Distributionally robust optimization (DRO) is a widely-used approach to learn models that are robust against distribution shift. Compared with the standard optimization setting, the objective function in DRO is more difficult to optimize, and most of the existing theoretical results make strong assumptions on the loss function. In this work we bridge the gap by studying DRO algorithms for general smooth non-convex losses. By carefully exploiting the specific form of the DRO objective, we are able to provide non-asymptotic convergence guarantees even though the objective function is possibly non-convex, non-smooth and has unbounded gradient noise. In particular, we prove that a special algorithm called the mini-batch normalized gradient descent with momentum, can find an $\epsilon$ first-order stationary point within $O( \epsilon^{-4} )$ gradient complexity. We also discuss the conditional value-at-risk (CVaR) setting, where we propose a penalized DRO objective based on a smoothed version of the CVaR that allows us to obtain a similar convergence guarantee. We finally verify our theoretical results in a number of tasks and find that the proposed algorithm can consistently achieve prominent acceleration.
Collaborative Visual Navigation
Jul 20, 2021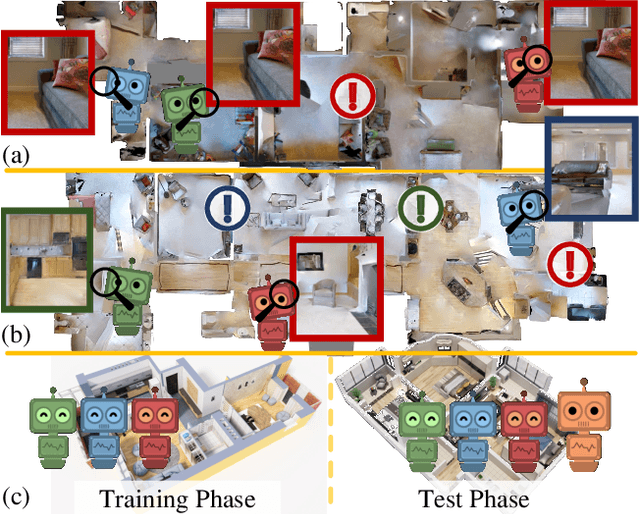
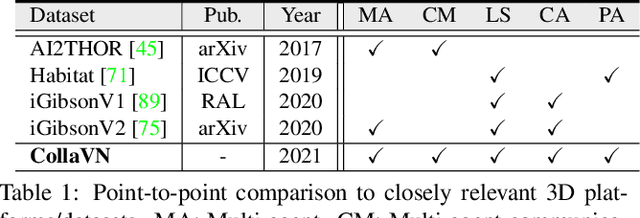
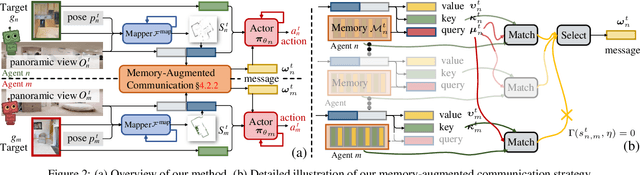
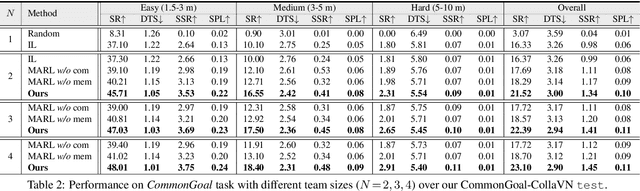
As a fundamental problem for Artificial Intelligence, multi-agent system (MAS) is making rapid progress, mainly driven by multi-agent reinforcement learning (MARL) techniques. However, previous MARL methods largely focused on grid-world like or game environments; MAS in visually rich environments has remained less explored. To narrow this gap and emphasize the crucial role of perception in MAS, we propose a large-scale 3D dataset, CollaVN, for multi-agent visual navigation (MAVN). In CollaVN, multiple agents are entailed to cooperatively navigate across photo-realistic environments to reach target locations. Diverse MAVN variants are explored to make our problem more general. Moreover, a memory-augmented communication framework is proposed. Each agent is equipped with a private, external memory to persistently store communication information. This allows agents to make better use of their past communication information, enabling more efficient collaboration and robust long-term planning. In our experiments, several baselines and evaluation metrics are designed. We also empirically verify the efficacy of our proposed MARL approach across different MAVN task settings.
Drug-Target Interaction Prediction with Graph Attention networks
Jul 10, 2021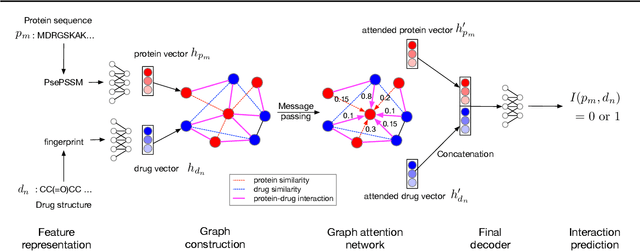
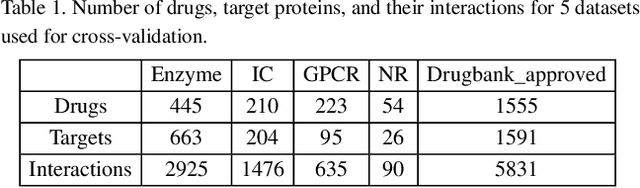
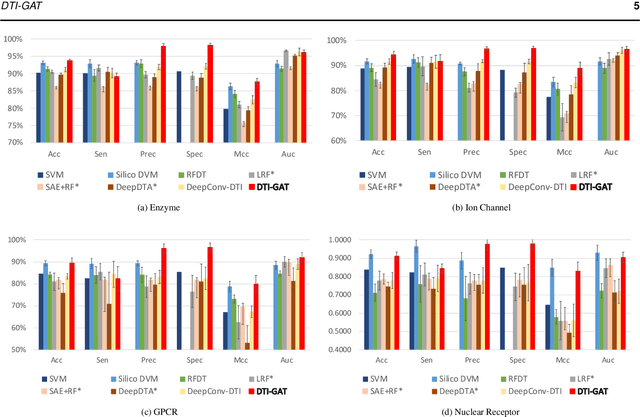
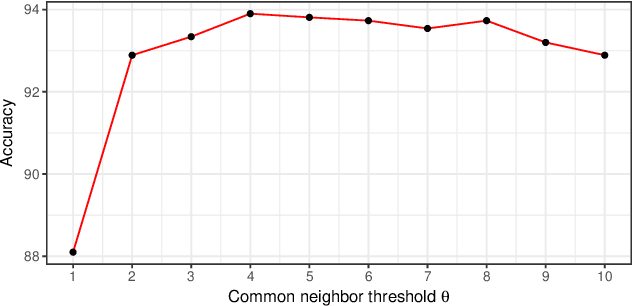
Motivation: Predicting Drug-Target Interaction (DTI) is a well-studied topic in bioinformatics due to its relevance in the fields of proteomics and pharmaceutical research. Although many machine learning methods have been successfully applied in this task, few of them aim at leveraging the inherent heterogeneous graph structure in the DTI network to address the challenge. For better learning and interpreting the DTI topological structure and the similarity, it is desirable to have methods specifically for predicting interactions from the graph structure. Results: We present an end-to-end framework, DTI-GAT (Drug-Target Interaction prediction with Graph Attention networks) for DTI predictions. DTI-GAT incorporates a deep neural network architecture that operates on graph-structured data with the attention mechanism, which leverages both the interaction patterns and the features of drug and protein sequences. DTI-GAT facilitates the interpretation of the DTI topological structure by assigning different attention weights to each node with the self-attention mechanism. Experimental evaluations show that DTI-GAT outperforms various state-of-the-art systems on the binary DTI prediction problem. Moreover, the independent study results further demonstrate that our model can be generalized better than other conventional methods. Availability: The source code and all datasets are available at https://github.com/Haiyang-W/DTI-GRAPH