 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMOT-40: A Benchmark for Generic Multiple Object Tracking
Dec 02, 2020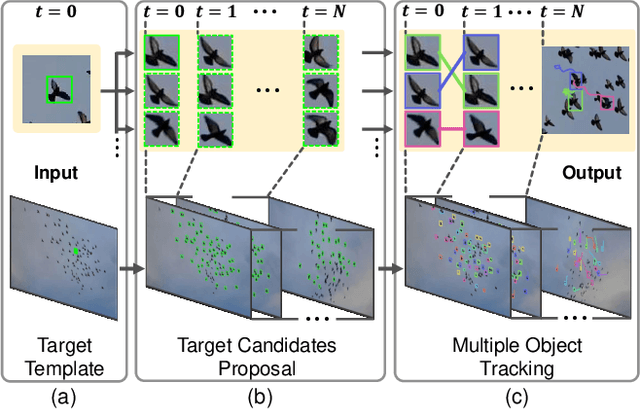
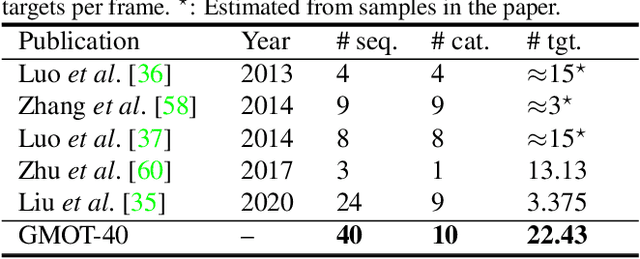
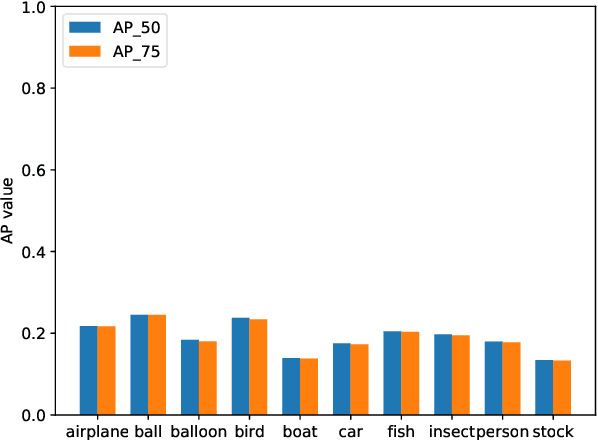

Multiple Object Tracking (MOT) has witnessed remarkable advances in recent years. However, existing studies dominantly request prior knowledge of the tracking target, and hence may not generalize well to unseen categories. In contrast, Generic Multiple Object Tracking (GMOT), which requires little prior information about the target, is largely under-explored. In this paper, we make contributions to boost the study of GMOT in three aspects. First, we construct the first public GMOT dataset, dubbed GMOT-40, which contains 40 carefully annotated sequences evenly distributed among 10 object categories. In addition, two tracking protocols are adopted to evaluate different characteristics of tracking algorithms. Second, by noting the lack of devoted tracking algorithms, we have designed a series of baseline GMOT algorithms. Third, we perform a thorough evaluation on GMOT-40, involving popular MOT algorithms (with necessary modifications) and the proposed baselines. We will release the GMOT-40 benchmark, the evaluation results, as well as the baseline algorithm to the public upon the publication of the paper.
CRACT: Cascaded Regression-Align-Classification for Robust Visual Tracking
Nov 25, 2020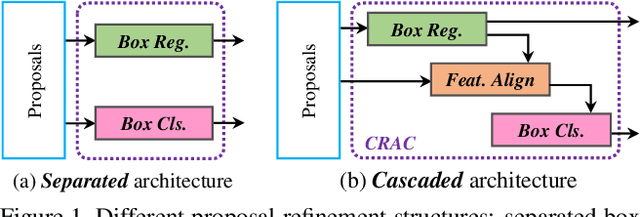
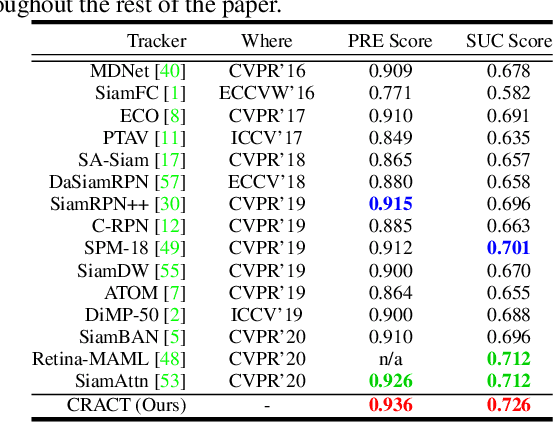
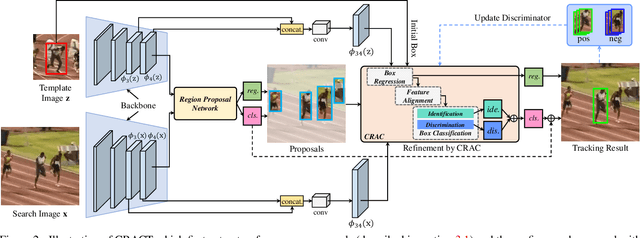
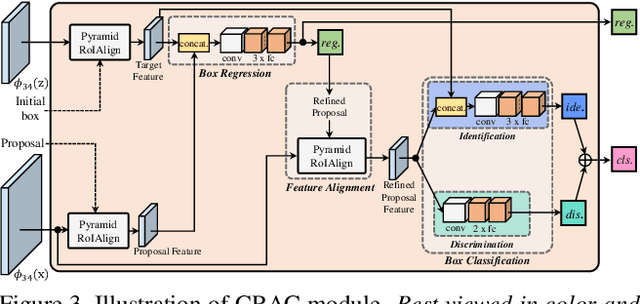
High quality object proposals are crucial in visual tracking algorithms that utilize region proposal network (RPN). Refinement of these proposals, typically by box regression and classification in parallel, has been popularly adopted to boost tracking performance. However, it still meets problems when dealing with complex and dynamic background. Thus motivated, in this paper we introduce an improved proposal refinement module, Cascaded Regression-Align-Classification (CRAC), which yields new state-of-the-art performances on many benchmarks. First, having observed that the offsets from box regression can serve as guidance for proposal feature refinement, we design CRAC as a cascade of box regression, feature alignment and box classification. The key is to bridge box regression and classification via an alignment step, which leads to more accurate features for proposal classification with improved robustness. To address the variation in object appearance, we introduce an identification-discrimination component for box classification, which leverages offline reliable fine-grained template and online rich background information to distinguish the target from background. Moreover, we present pyramid RoIAlign that benefits CRAC by exploiting both the local and global cues of proposals. During inference, tracking proceeds by ranking all refined proposals and selecting the best one. In experiments on seven benchmarks including OTB-2015, UAV123, NfS, VOT-2018, TrackingNet, GOT-10k and LaSOT, our CRACT exhibits very promising results in comparison with state-of-the-art competitors and runs in real-time.
Transparent Object Tracking Benchmark
Nov 21, 2020
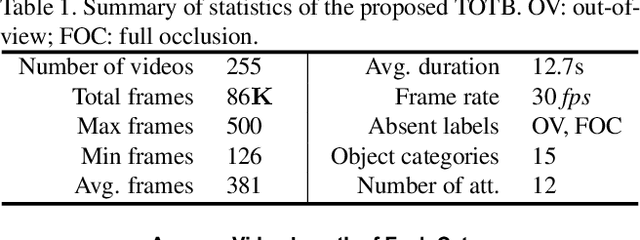
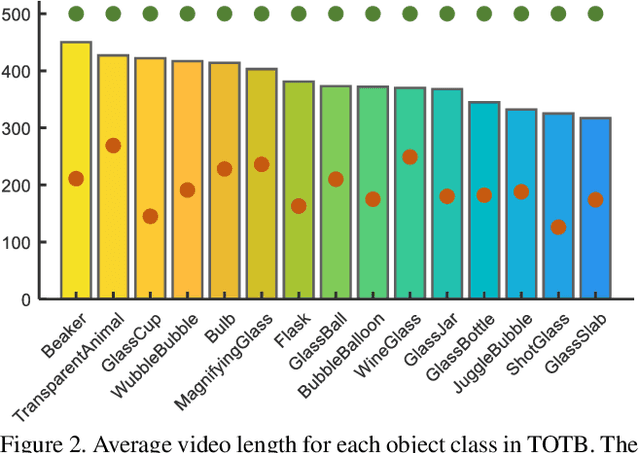
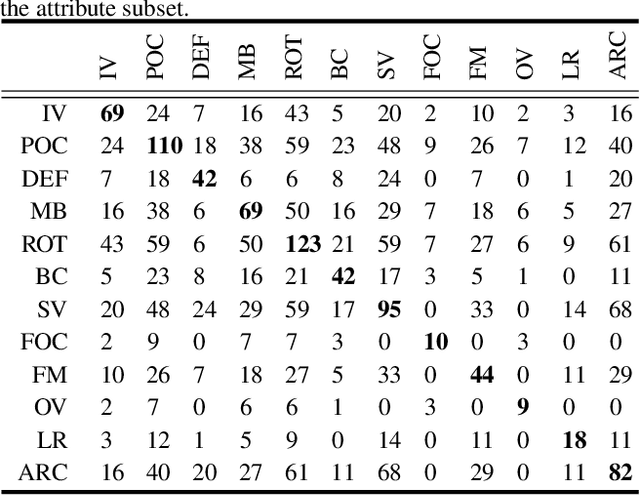
Visual tracking has achieved considerable progress in recent years. However, current research in the field mainly focuses on tracking of opaque objects, while little attention is paid to transparent object tracking. In this paper, we make the first attempt in exploring this problem by proposing a Transparent Object Tracking Benchmark (TOTB). Specifically, TOTB consists of 225 videos (86K frames) from 15 diverse transparent object categories. Each sequence is manually labeled with axis-aligned bounding boxes. To the best of our knowledge, TOTB is the first benchmark dedicated to transparent object tracking. In order to understand how existing trackers perform and to provide comparison for future research on TOTB, we extensively evaluate 25 state-of-the-art tracking algorithms. The evaluation results exhibit that more efforts are needed to improve transparent object tracking. Besides, we observe some nontrivial findings from the evaluation that are discrepant with some common beliefs in opaque object tracking. For example, we find that deep(er) features are not always good for improvements. Moreover, to encourage future research, we introduce a novel tracker, named TransATOM, which leverages transparency features for tracking and surpasses all 25 evaluated approaches by a large margin. By releasing TOTB, we expect to facilitate future research and application of transparent object tracking in both the academia and industry. The TOTB and evaluation results as well as TransATOM will be made available at https://hengfan2010.github.io/projects/TOTB.
Pushing the Envelope of Rotation Averaging for Visual SLAM
Nov 02, 2020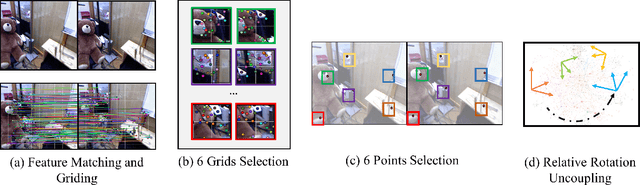
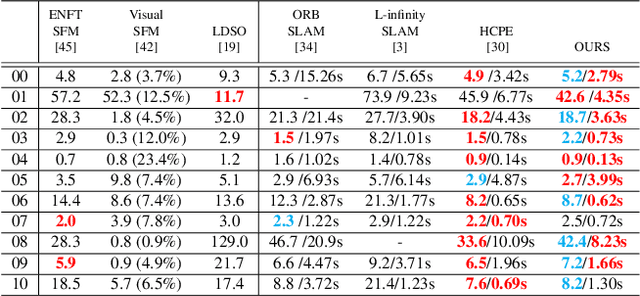

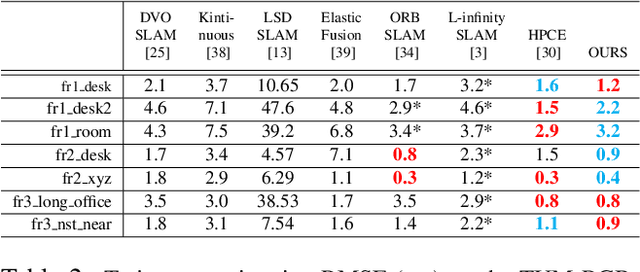
As an essential part of structure from motion (SfM) and Simultaneous Localization and Mapping (SLAM) systems, motion averaging has been extensively studied in the past years and continues to attract surging research attention. While canonical approaches such as bundle adjustment are predominantly inherited in most of state-of-the-art SLAM systems to estimate and update the trajectory in the robot navigation, the practical implementation of bundle adjustment in SLAM systems is intrinsically limited by the high computational complexity, unreliable convergence and strict requirements of ideal initializations. In this paper, we lift these limitations and propose a novel optimization backbone for visual SLAM systems, where we leverage rotation averaging to improve the accuracy, efficiency and robustness of conventional monocular SLAM pipelines. In our approach, we first decouple the rotational and translational parameters in the camera rigid body transformation and convert the high-dimensional non-convex nonlinear problem into tractable linear subproblems in lower dimensions, and show that the subproblems can be solved independently with proper constraints. We apply the scale parameter with $l_1$-norm in the pose-graph optimization to address the rotation averaging robustness against outliers. We further validate the global optimality of our proposed approach, revisit and address the initialization schemes, pure rotational scene handling and outlier treatments. We demonstrate that our approach can exhibit up to 10x faster speed with comparable accuracy against the state of the art on public benchmarks.
LaSOT: A High-quality Large-scale Single Object Tracking Benchmark
Sep 12, 2020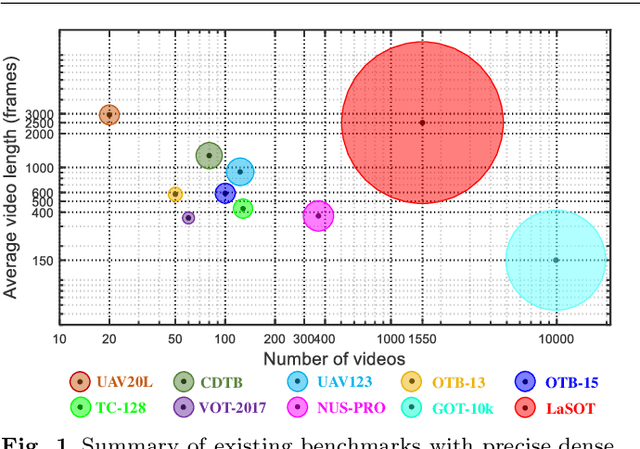
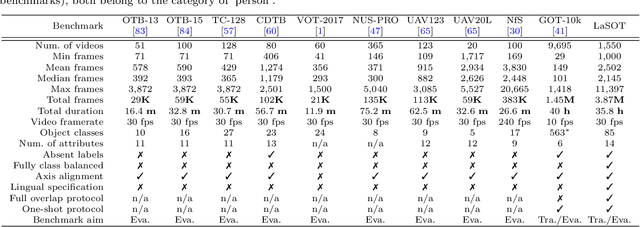
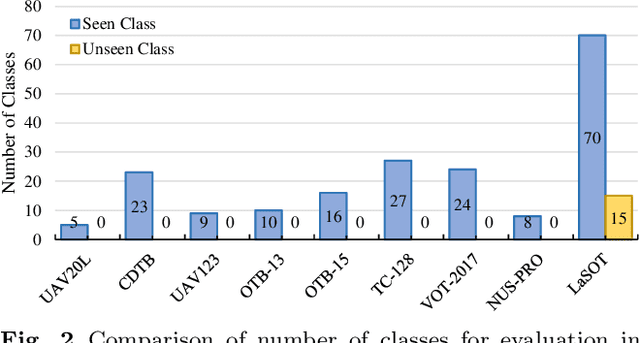

Despite great recent advances in visual tracking, its further development, including both algorithm design and evaluation, is limited due to lack of dedicated large-scale benchmarks. To address this problem, we present LaSOT, a high-quality Large-scale Single Object Tracking benchmark. LaSOT contains a diverse selection of 85 object classes, and offers 1,550 totaling more than 3.87 million frames. Each video frame is carefully and manually annotated with a bounding box. This makes LaSOT, to our knowledge, the largest densely annotated tracking benchmark. Our goal in releasing LaSOT is to provide a dedicated high quality platform for both training and evaluation of trackers. The average video length of LaSOT is around 2,500 frames, where each video contains various challenge factors that exist in real world video footage,such as the targets disappearing and re-appearing. These longer video lengths allow for the assessment of long-term trackers. To take advantage of the close connection between visual appearance and natural language, we provide language specification for each video in LaSOT. We believe such additions will allow for future research to use linguistic features to improve tracking. Two protocols, full-overlap and one-shot, are designated for flexible assessment of trackers. We extensively evaluate 48 baseline trackers on LaSOT with in-depth analysis, and results reveal that there still exists significant room for improvement. The complete benchmark, tracking results as well as analysis are available at http://vision.cs.stonybrook.edu/~lasot/.
Feature Space Augmentation for Long-Tailed Data
Aug 09, 2020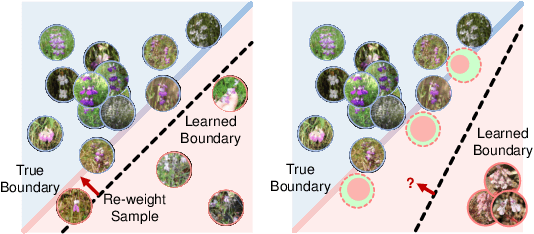
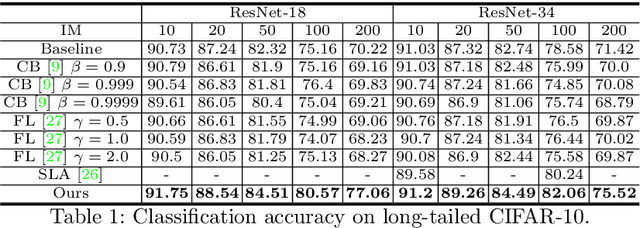
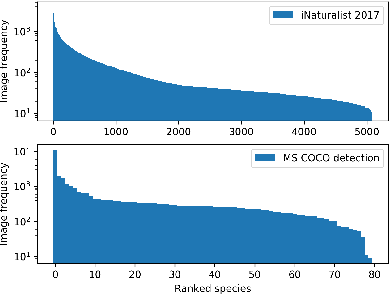
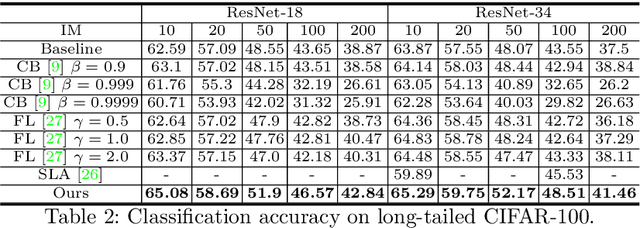
Real-world data often follow a long-tailed distribution as the frequency of each class is typically different. For example, a dataset can have a large number of under-represented classes and a few classes with more than sufficient data. However, a model to represent the dataset is usually expected to have reasonably homogeneous performances across classes. Introducing class-balanced loss and advanced methods on data re-sampling and augmentation are among the best practices to alleviate the data imbalance problem. However, the other part of the problem about the under-represented classes will have to rely on additional knowledge to recover the missing information. In this work, we present a novel approach to address the long-tailed problem by augmenting the under-represented classes in the feature space with the features learned from the classes with ample samples. In particular, we decompose the features of each class into a class-generic component and a class-specific component using class activation maps. Novel samples of under-represented classes are then generated on the fly during training stages by fusing the class-specific features from the under-represented classes with the class-generic features from confusing classes. Our results on different datasets such as iNaturalist, ImageNet-LT, Places-LT and a long-tailed version of CIFAR have shown the state of the art performances.
End-to-end Full Projector Compensation
Aug 04, 2020

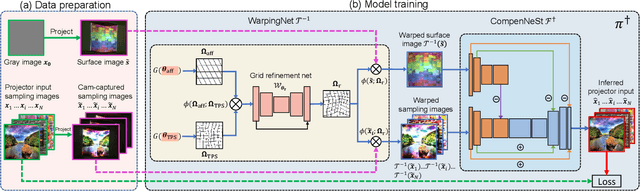

Full projector compensation aims to modify a projector input image to compensate for both geometric and photometric disturbance of the projection surface. Traditional methods usually solve the two parts separately and may suffer from suboptimal solutions. In this paper, we propose the first end-to-end differentiable solution, named CompenNeSt++, to solve the two problems jointly. First, we propose a novel geometric correction subnet, named WarpingNet, which is designed with a cascaded coarse-to-fine structure to learn the sampling grid directly from sampling images. Second, we propose a novel photometric compensation subnet, named CompenNeSt, which is designed with a siamese architecture to capture the photometric interactions between the projection surface and the projected images, and to use such information to compensate the geometrically corrected images. By concatenating WarpingNet with CompenNeSt, CompenNeSt++ accomplishes full projector compensation and is end-to-end trainable. Third, to improve practicability, we propose a novel synthetic data-based pre-training strategy to significantly reduce the number of training images and training time. Moreover, we construct the first setup-independent full compensation benchmark to facilitate future studies. In thorough experiments, our method shows clear advantages over prior art with promising compensation quality and meanwhile being practically convenient.
Recurrent Exposure Generation for Low-Light Face Detection
Jul 21, 2020
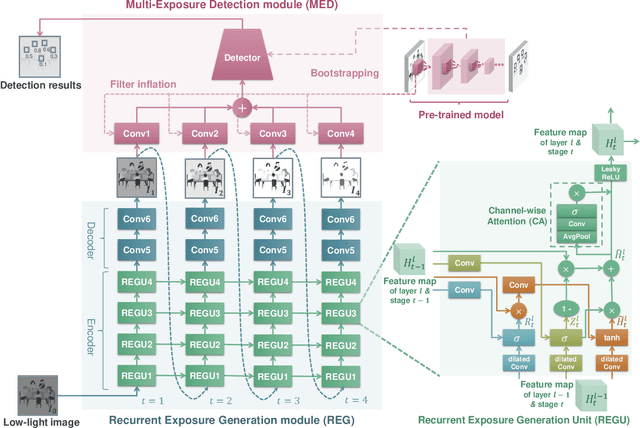
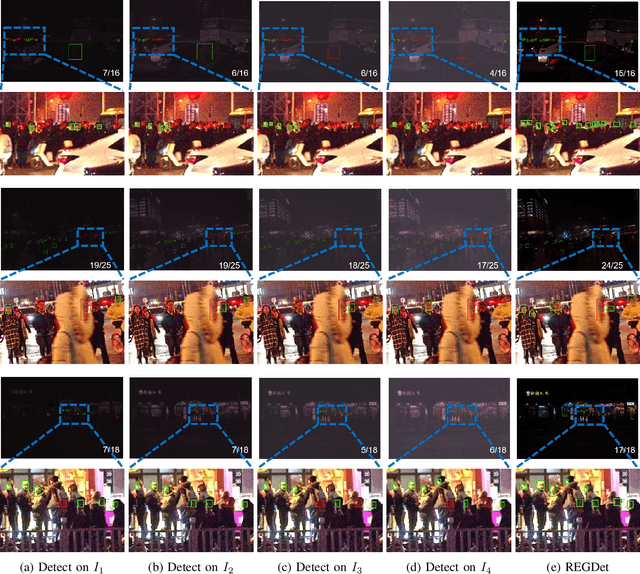
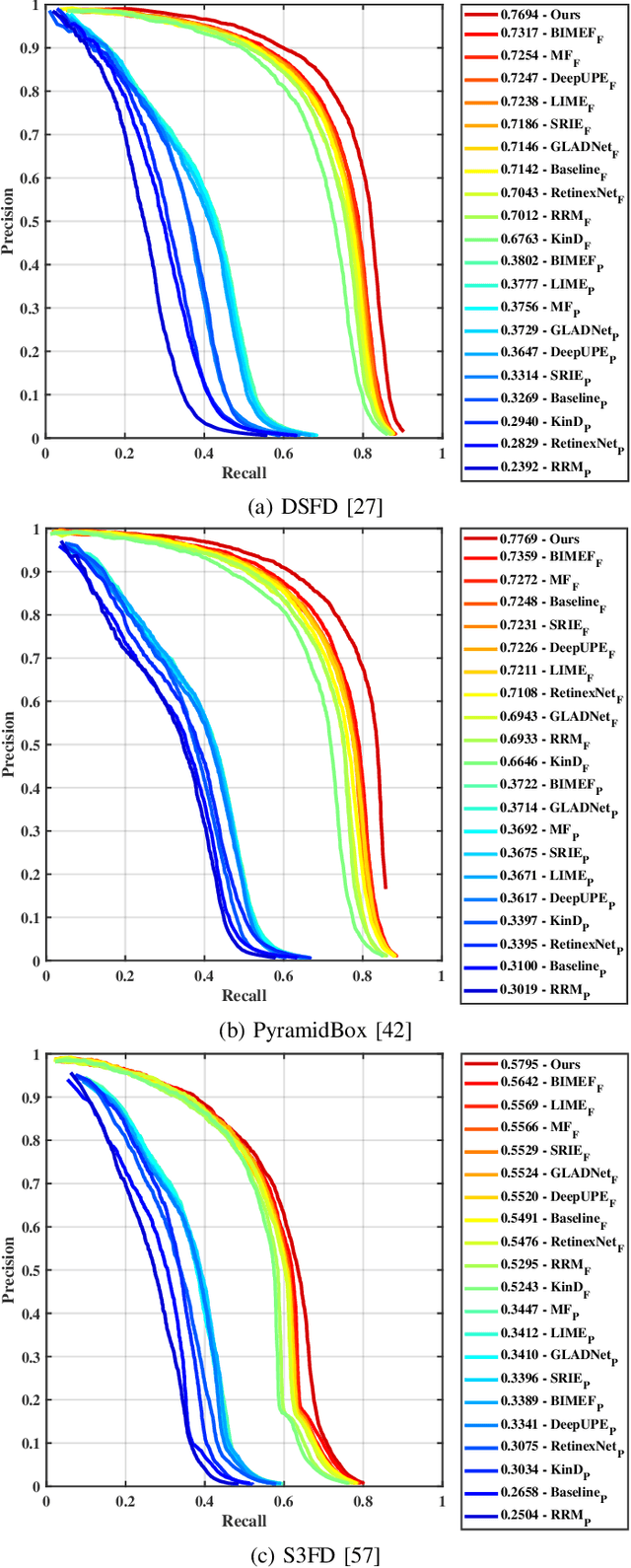
Face detection from low-light images is challenging due to limited photos and inevitable noise, which, to make the task even harder, are often spatially unevenly distributed. A natural solution is to borrow the idea from multi-exposure, which captures multiple shots to obtain well-exposed images under challenging conditions. High-quality implementation/approximation of multi-exposure from a single image is however nontrivial. Fortunately, as shown in this paper, neither is such high-quality necessary since our task is face detection rather than image enhancement. Specifically, we propose a novel Recurrent Exposure Generation (REG) module and couple it seamlessly with a Multi-Exposure Detection (MED) module, and thus significantly improve face detection performance by effectively inhibiting non-uniform illumination and noise issues. REG produces progressively and efficiently intermediate images corresponding to various exposure settings, and such pseudo-exposures are then fused by MED to detect faces across different lighting conditions. The proposed method, named REGDet, is the first `detection-with-enhancement' framework for low-light face detection. It not only encourages rich interaction and feature fusion across different illumination levels, but also enables effective end-to-end learning of the REG component to be better tailored for face detection. Moreover, as clearly shown in our experiments, REG can be flexibly coupled with different face detectors without extra low/normal-light image pairs for training. We tested REGDet on the DARK FACE low-light face benchmark with thorough ablation study, where REGDet outperforms previous state-of-the-arts by a significant margin, with only negligible extra parameters.
Cross-Modal Weighting Network for RGB-D Salient Object Detection
Jul 09, 2020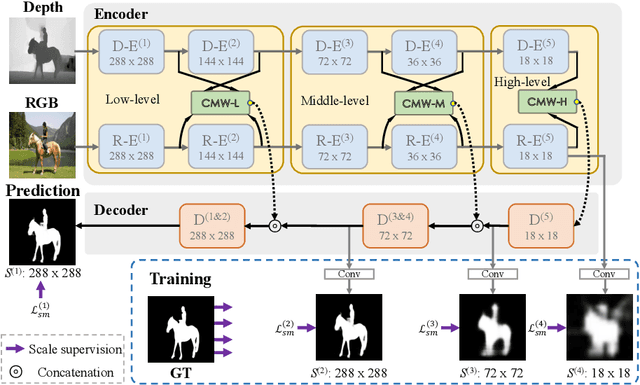
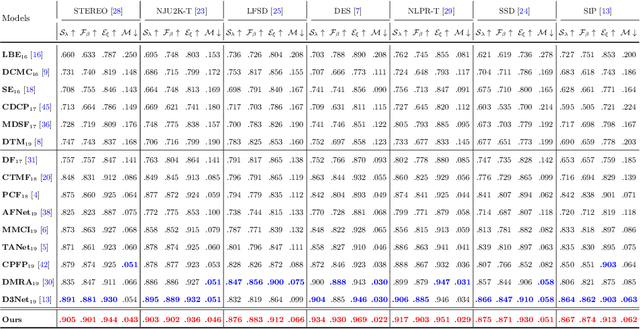
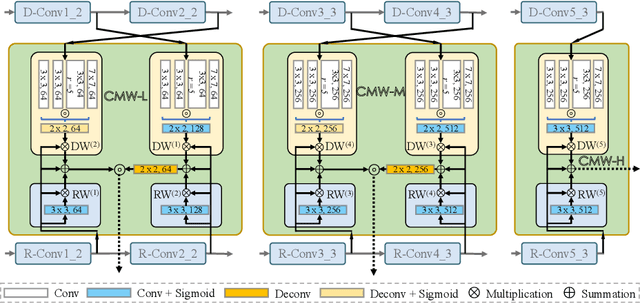
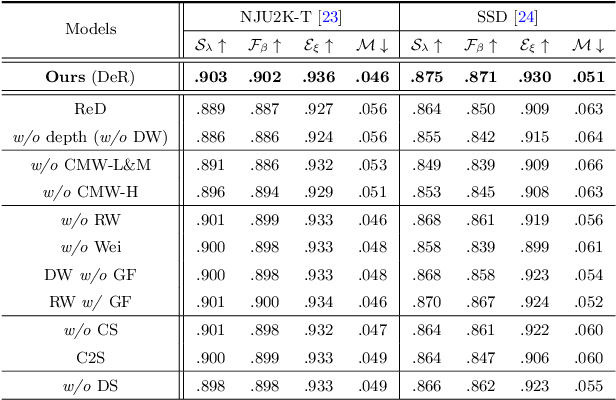
Depth maps contain geometric clues for assisting Salient Object Detection (SOD). In this paper, we propose a novel Cross-Modal Weighting (CMW) strategy to encourage comprehensive interactions between RGB and depth channels for RGB-D SOD. Specifically, three RGB-depth interaction modules, named CMW-L, CMW-M and CMW-H, are developed to deal with respectively low-, middle- and high-level cross-modal information fusion. These modules use Depth-to-RGB Weighing (DW) and RGB-to-RGB Weighting (RW) to allow rich cross-modal and cross-scale interactions among feature layers generated by different network blocks. To effectively train the proposed Cross-Modal Weighting Network (CMWNet), we design a composite loss function that summarizes the errors between intermediate predictions and ground truth over different scales. With all these novel components working together, CMWNet effectively fuses information from RGB and depth channels, and meanwhile explores object localization and details across scales. Thorough evaluations demonstrate CMWNet consistently outperforms 15 state-of-the-art RGB-D SOD methods on seven popular benchmarks.
Deep Bilateral Retinex for Low-Light Image Enhancement
Jul 04, 2020

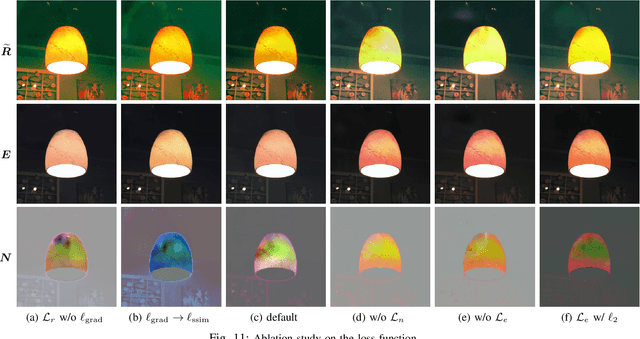
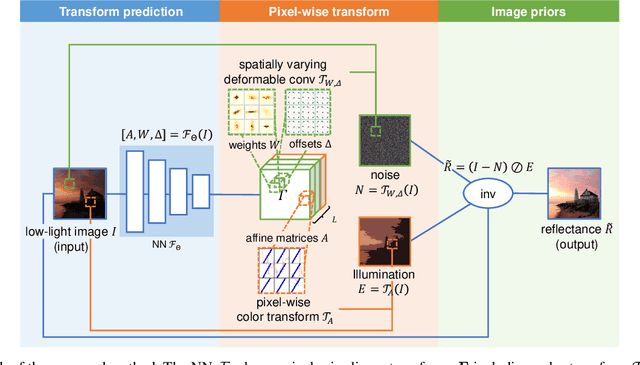
Low-light images, i.e. the images captured in low-light conditions, suffer from very poor visibility caused by low contrast, color distortion and significant measurement noise. Low-light image enhancement is about improving the visibility of low-light images. As the measurement noise in low-light images is usually significant yet complex with spatially-varying characteristic, how to handle the noise effectively is an important yet challenging problem in low-light image enhancement. Based on the Retinex decomposition of natural images, this paper proposes a deep learning method for low-light image enhancement with a particular focus on handling the measurement noise. The basic idea is to train a neural network to generate a set of pixel-wise operators for simultaneously predicting the noise and the illumination layer, where the operators are defined in the bilateral space. Such an integrated approach allows us to have an accurate prediction of the reflectance layer in the presence of significant spatially-varying measurement noise. Extensive experiments on several benchmark datasets have shown that the proposed method is very competitive to the state-of-the-art methods, and has significant advantage over others when processing images captured in extremely low lighting conditions.