 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreFA: Breaking the Static Wall of Generative Model Attribution
Apr 21, 2026As AI generative models evolve at unprecedented speed, image attribution has become a moving target. New diffusion, adversarial and autoregressive generators appear almost monthly, making existing watermark, classifier and inversion methods obsolete upon release. The core problem lies not in model recognition, but in the inability to adapt attribution itself. We introduce IncreFA, a framework that redefines attribution as a structured incremental learning problem, allowing the system to learn continuously as new generative models emerge. IncreFA departs from conventional incremental learning by exploiting the hierarchical relationships among generative architectures and coupling them with continual adaptation. It integrates two mutually reinforcing mechanisms: (1) Hierarchical Constraints, which encode architectural hierarchies through learnable orthogonal priors to disentangle family-level invariants from model-specific idiosyncrasies; and (2) a Latent Memory Bank, which replays compact latent exemplars and mixes them to generate pseudo-unseen samples, stabilising representation drift and enhancing open-set awareness. On the newly constructed Incremental Attribution Benchmark (IABench) covering 28 generative models released between 2022 and 2025, IncreFA achieves state-of-the-art attribution accuracy and 98.93% unseen detection under a temporally ordered open-set protocol. Code will be available at https://github.com/Ant0ny44/IncreFA.
Recolour What Matters: Region-Aware Colour Editing via Token-Level Diffusion
Mar 19, 2026Colour is one of the most perceptually salient yet least controllable attributes in image generation. Although recent diffusion models can modify object colours from user instructions, their results often deviate from the intended hue, especially for fine-grained and local edits. Early text-driven methods rely on discrete language descriptions that cannot accurately represent continuous chromatic variations. To overcome this limitation, we propose ColourCrafter, a unified diffusion framework that transforms colour editing from global tone transfer into a structured, region-aware generation process. Unlike traditional colour driven methods, ColourCrafter performs token-level fusion of RGB colour tokens and image tokens in latent space, selectively propagating colour information to semantically relevant regions while preserving structural fidelity. A perceptual Lab-space Loss further enhances pixel-level precision by decoupling luminance and chrominance and constraining edits within masked areas. Additionally, we build ColourfulSet, a largescale dataset of high-quality image pairs with continuous and diverse colour variations. Extensive experiments demonstrate that ColourCrafter achieves state-of-the-art colour accuracy, controllability and perceptual fidelity in fine-grained colour editing. Our project is available at https://yangyuqi317.github.io/ColourCrafter.github.io/.
Seeing as Experts Do: A Knowledge-Augmented Agent for Open-Set Fine-Grained Visual Understanding
Mar 04, 2026Fine-grained visual understanding is shifting from static classification to knowledge-augmented reasoning, where models must justify as well as recognise. Existing approaches remain limited by closed-set taxonomies and single-label prediction, leading to significant degradation under open-set or context-dependent conditions. We present the Knowledge-Augmented Fine-Grained Reasoning Agent (KFRA), a unified framework that transforms fine-grained perception into evidence-driven reasoning. KFRA operates through a three-stage closed reasoning loop that emulates expert analysis. It first performs open-vocabulary detection and web-scale retrieval to generate category hypotheses. It then conducts discriminative regions localisation by aligning textual knowledge with visual evidence through a global-to-local focusing mechanism. Finally, it integrates all multimodal evidence within a large multimodal model to perform interpretable reasoning. Unlike existing agents that treat retrieval and reasoning as independent processes, KFRA establishes a retrieval-grounding coupling that converts retrieved knowledge into spatially grounded evidence for verification. This design enables factual, interpretable, and task-agnostic reasoning across diverse fine-grained scenarios. To evaluate this capability, we construct FGExpertBench, a benchmark designed to assess reasoning depth and cross-task generalisation across six knowledge dimensions. Extensive experiments demonstrate that KFRA consistently surpasses both standalone large multimodal models and current agent frameworks, achieving up to 19 percent improvement in reasoning accuracy and delivering evidence-grounded interpretability in open-set fine-grained visual understanding.
Towards Privacy-Preserving Fine-Grained Visual Classification via Hierarchical Learning from Label Proportions
May 29, 2025



In recent years, Fine-Grained Visual Classification (FGVC) has achieved impressive recognition accuracy, despite minimal inter-class variations. However, existing methods heavily rely on instance-level labels, making them impractical in privacy-sensitive scenarios such as medical image analysis. This paper aims to enable accurate fine-grained recognition without direct access to instance labels. To achieve this, we leverage the Learning from Label Proportions (LLP) paradigm, which requires only bag-level labels for efficient training. Unlike existing LLP-based methods, our framework explicitly exploits the hierarchical nature of fine-grained datasets, enabling progressive feature granularity refinement and improving classification accuracy. We propose Learning from Hierarchical Fine-Grained Label Proportions (LHFGLP), a framework that incorporates Unrolled Hierarchical Fine-Grained Sparse Dictionary Learning, transforming handcrafted iterative approximation into learnable network optimization. Additionally, our proposed Hierarchical Proportion Loss provides hierarchical supervision, further enhancing classification performance. Experiments on three widely-used fine-grained datasets, structured in a bag-based manner, demonstrate that our framework consistently outperforms existing LLP-based methods. We will release our code and datasets to foster further research in privacy-preserving fine-grained classification.
Multimodal Conditional Information Bottleneck for Generalizable AI-Generated Image Detection
May 21, 2025Although existing CLIP-based methods for detecting AI-generated images have achieved promising results, they are still limited by severe feature redundancy, which hinders their generalization ability. To address this issue, incorporating an information bottleneck network into the task presents a straightforward solution. However, relying solely on image-corresponding prompts results in suboptimal performance due to the inherent diversity of prompts. In this paper, we propose a multimodal conditional bottleneck network to reduce feature redundancy while enhancing the discriminative power of features extracted by CLIP, thereby improving the model's generalization ability. We begin with a semantic analysis experiment, where we observe that arbitrary text features exhibit lower cosine similarity with real image features than with fake image features in the CLIP feature space, a phenomenon we refer to as "bias". Therefore, we introduce InfoFD, a text-guided AI-generated image detection framework. InfoFD consists of two key components: the Text-Guided Conditional Information Bottleneck (TGCIB) and Dynamic Text Orthogonalization (DTO). TGCIB improves the generalizability of learned representations by conditioning on both text and class modalities. DTO dynamically updates weighted text features, preserving semantic information while leveraging the global "bias". Our model achieves exceptional generalization performance on the GenImage dataset and latest generative models. Our code is available at https://github.com/Ant0ny44/InfoFD.
FakeReasoning: Towards Generalizable Forgery Detection and Reasoning
Mar 27, 2025Accurate and interpretable detection of AI-generated images is essential for mitigating risks associated with AI misuse. However, the substantial domain gap among generative models makes it challenging to develop a generalizable forgery detection model. Moreover, since every pixel in an AI-generated image is synthesized, traditional saliency-based forgery explanation methods are not well suited for this task. To address these challenges, we propose modeling AI-generated image detection and explanation as a Forgery Detection and Reasoning task (FDR-Task), leveraging vision-language models (VLMs) to provide accurate detection through structured and reliable reasoning over forgery attributes. To facilitate this task, we introduce the Multi-Modal Forgery Reasoning dataset (MMFR-Dataset), a large-scale dataset containing 100K images across 10 generative models, with 10 types of forgery reasoning annotations, enabling comprehensive evaluation of FDR-Task. Additionally, we propose FakeReasoning, a forgery detection and reasoning framework with two key components. First, Forgery-Aligned Contrastive Learning enhances VLMs' understanding of forgery-related semantics through both cross-modal and intra-modal contrastive learning between images and forgery attribute reasoning. Second, a Classification Probability Mapper bridges the optimization gap between forgery detection and language modeling by mapping the output logits of VLMs to calibrated binary classification probabilities. Experiments across multiple generative models demonstrate that FakeReasoning not only achieves robust generalization but also outperforms state-of-the-art methods on both detection and reasoning tasks.
M4Fog: A Global Multi-Regional, Multi-Modal, and Multi-Stage Dataset for Marine Fog Detection and Forecasting to Bridge Ocean and Atmosphere
Jun 19, 2024Marine fog poses a significant hazard to global shipping, necessitating effective detection and forecasting to reduce economic losses. In recent years, several machine learning (ML) methods have demonstrated superior detection accuracy compared to traditional meteorological methods. However, most of these works are developed on proprietary datasets, and the few publicly accessible datasets are often limited to simplistic toy scenarios for research purposes. To advance the field, we have collected nearly a decade's worth of multi-modal data related to continuous marine fog stages from four series of geostationary meteorological satellites, along with meteorological observations and numerical analysis, covering 15 marine regions globally where maritime fog frequently occurs. Through pixel-level manual annotation by meteorological experts, we present the most comprehensive marine fog detection and forecasting dataset to date, named M4Fog, to bridge ocean and atmosphere. The dataset comprises 68,000 "super data cubes" along four dimensions: elements, latitude, longitude and time, with a temporal resolution of half an hour and a spatial resolution of 1 kilometer. Considering practical applications, we have defined and explored three meaningful tracks with multi-metric evaluation systems: static or dynamic marine fog detection, and spatio-temporal forecasting for cloud images. Extensive benchmarking and experiments demonstrate the rationality and effectiveness of the construction concept for proposed M4Fog. The data and codes are available to whole researchers through cloud platforms to develop ML-driven marine fog solutions and mitigate adverse impacts on human activities.
DemoFusion: Democratising High-Resolution Image Generation With No $$$
Nov 24, 2023High-resolution image generation with Generative Artificial Intelligence (GenAI) has immense potential but, due to the enormous capital investment required for training, it is increasingly centralised to a few large corporations, and hidden behind paywalls. This paper aims to democratise high-resolution GenAI by advancing the frontier of high-resolution generation while remaining accessible to a broad audience. We demonstrate that existing Latent Diffusion Models (LDMs) possess untapped potential for higher-resolution image generation. Our novel DemoFusion framework seamlessly extends open-source GenAI models, employing Progressive Upscaling, Skip Residual, and Dilated Sampling mechanisms to achieve higher-resolution image generation. The progressive nature of DemoFusion requires more passes, but the intermediate results can serve as "previews", facilitating rapid prompt iteration.
Bi-directional Feature Reconstruction Network for Fine-Grained Few-Shot Image Classification
Nov 30, 2022



The main challenge for fine-grained few-shot image classification is to learn feature representations with higher inter-class and lower intra-class variations, with a mere few labelled samples. Conventional few-shot learning methods however cannot be naively adopted for this fine-grained setting -- a quick pilot study reveals that they in fact push for the opposite (i.e., lower inter-class variations and higher intra-class variations). To alleviate this problem, prior works predominately use a support set to reconstruct the query image and then utilize metric learning to determine its category. Upon careful inspection, we further reveal that such unidirectional reconstruction methods only help to increase inter-class variations and are not effective in tackling intra-class variations. In this paper, we for the first time introduce a bi-reconstruction mechanism that can simultaneously accommodate for inter-class and intra-class variations. In addition to using the support set to reconstruct the query set for increasing inter-class variations, we further use the query set to reconstruct the support set for reducing intra-class variations. This design effectively helps the model to explore more subtle and discriminative features which is key for the fine-grained problem in hand. Furthermore, we also construct a self-reconstruction module to work alongside the bi-directional module to make the features even more discriminative. Experimental results on three widely used fine-grained image classification datasets consistently show considerable improvements compared with other methods. Codes are available at: https://github.com/PRIS-CV/Bi-FRN.
Multi-View Active Fine-Grained Recognition
Jun 02, 2022
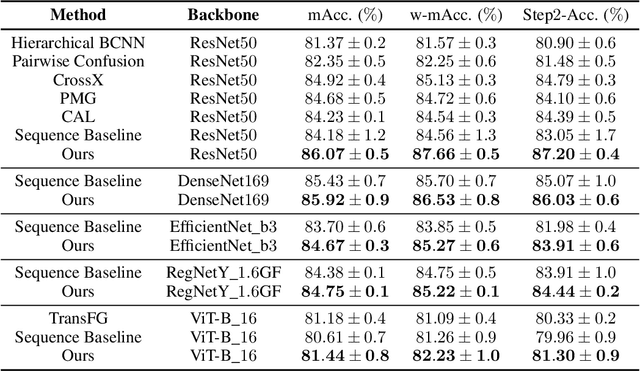
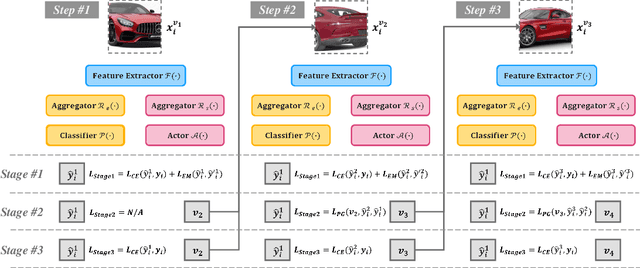
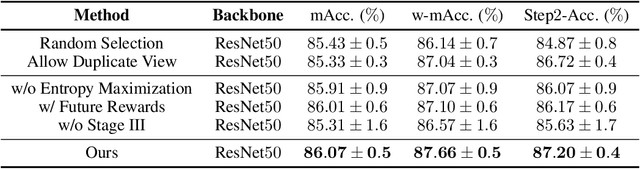
As fine-grained visual classification (FGVC) being developed for decades, great works related have exposed a key direction -- finding discriminative local regions and revealing subtle differences. However, unlike identifying visual contents within static images, for recognizing objects in the real physical world, discriminative information is not only present within seen local regions but also hides in other unseen perspectives. In other words, in addition to focusing on the distinguishable part from the whole, for efficient and accurate recognition, it is required to infer the key perspective with a few glances, e.g., people may recognize a "Benz AMG GT" with a glance of its front and then know that taking a look at its exhaust pipe can help to tell which year's model it is. In this paper, back to reality, we put forward the problem of active fine-grained recognition (AFGR) and complete this study in three steps: (i) a hierarchical, multi-view, fine-grained vehicle dataset is collected as the testbed, (ii) a simple experiment is designed to verify that different perspectives contribute differently for FGVC and different categories own different discriminative perspective, (iii) a policy-gradient-based framework is adopted to achieve efficient recognition with active view selection. Comprehensive experiments demonstrate that the proposed method delivers a better performance-efficient trade-off than previous FGVC methods and advanced neural networks.