 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior Knowledge Guided Unsupervised Domain Adaptation
Jul 18, 2022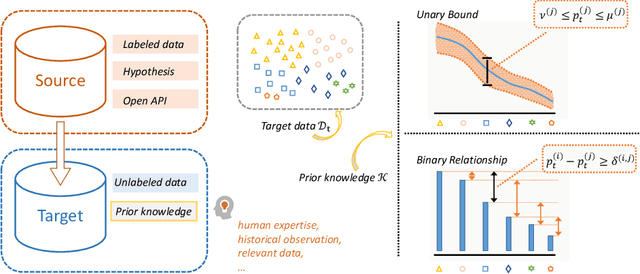

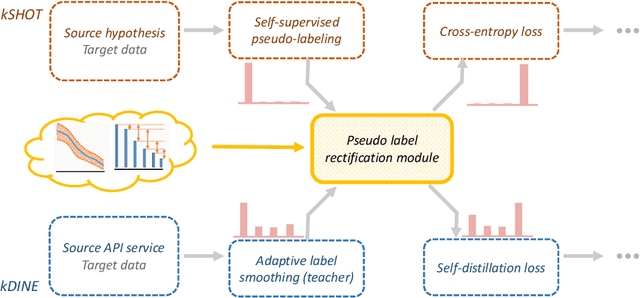
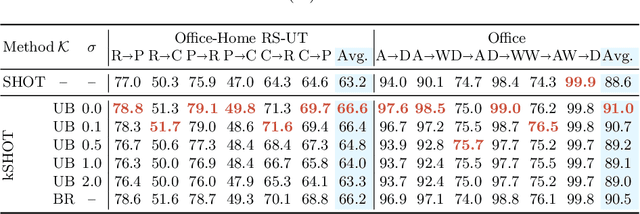
The waive of labels in the target domain makes Unsupervised Domain Adaptation (UDA) an attractive technique in many real-world applications, though it also brings great challenges as model adaptation becomes harder without labeled target data. In this paper, we address this issue by seeking compensation from target domain prior knowledge, which is often (partially) available in practice, e.g., from human expertise. This leads to a novel yet practical setting where in addition to the training data, some prior knowledge about the target class distribution are available. We term the setting as Knowledge-guided Unsupervised Domain Adaptation (KUDA). In particular, we consider two specific types of prior knowledge about the class distribution in the target domain: Unary Bound that describes the lower and upper bounds of individual class probabilities, and Binary Relationship that describes the relations between two class probabilities. We propose a general rectification module that uses such prior knowledge to refine model generated pseudo labels. The module is formulated as a Zero-One Programming problem derived from the prior knowledge and a smooth regularizer. It can be easily plugged into self-training based UDA methods, and we combine it with two state-of-the-art methods, SHOT and DINE. Empirical results on four benchmarks confirm that the rectification module clearly improves the quality of pseudo labels, which in turn benefits the self-training stage. With the guidance from prior knowledge, the performances of both methods are substantially boosted. We expect our work to inspire further investigations in integrating prior knowledge in UDA. Code is available at https://github.com/tsun/KUDA.
Surgical Phase Recognition in Laparoscopic Cholecystectomy
Jun 14, 2022
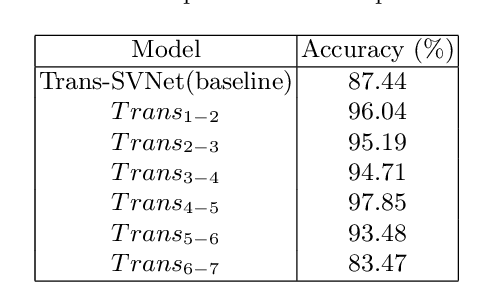
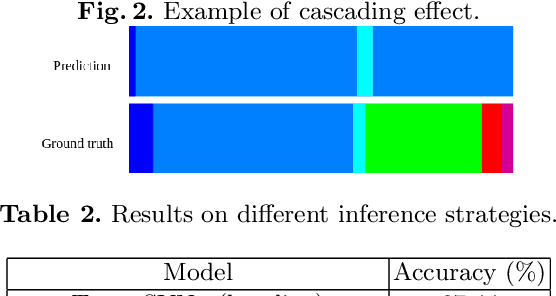

Automatic recognition of surgical phases in surgical videos is a fundamental task in surgical workflow analysis. In this report, we propose a Transformer-based method that utilizes calibrated confidence scores for a 2-stage inference pipeline, which dynamically switches between a baseline model and a separately trained transition model depending on the calibrated confidence level. Our method outperforms the baseline model on the Cholec80 dataset, and can be applied to a variety of action segmentation methods.
Safe Self-Refinement for Transformer-based Domain Adaptation
Apr 16, 2022

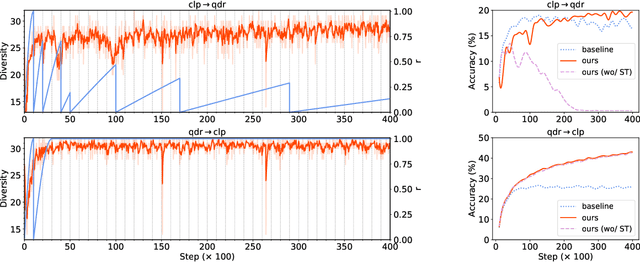
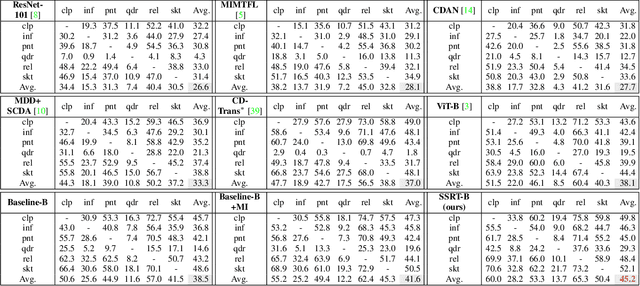
Unsupervised Domain Adaptation (UDA) aims to leverage a label-rich source domain to solve tasks on a related unlabeled target domain. It is a challenging problem especially when a large domain gap lies between the source and target domains. In this paper we propose a novel solution named SSRT (Safe Self-Refinement for Transformer-based domain adaptation), which brings improvement from two aspects. First, encouraged by the success of vision transformers in various vision tasks, we arm SSRT with a transformer backbone. We find that the combination of vision transformer with simple adversarial adaptation surpasses best reported Convolutional Neural Network (CNN)-based results on the challenging DomainNet benchmark, showing its strong transferable feature representation. Second, to reduce the risk of model collapse and improve the effectiveness of knowledge transfer between domains with large gaps, we propose a Safe Self-Refinement strategy. Specifically, SSRT utilizes predictions of perturbed target domain data to refine the model. Since the model capacity of vision transformer is large and predictions in such challenging tasks can be noisy, a safe training mechanism is designed to adaptively adjust learning configuration. Extensive evaluations are conducted on several widely tested UDA benchmarks and SSRT achieves consistently the best performances, including 85.43% on Office-Home, 88.76% on VisDA-2017 and 45.2% on DomainNet.
Unsupervised Deep Learning Meets Chan-Vese Model
Apr 14, 2022

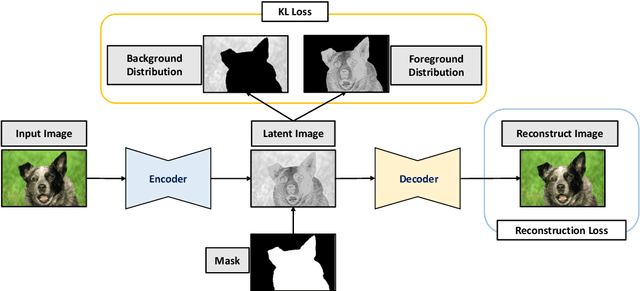
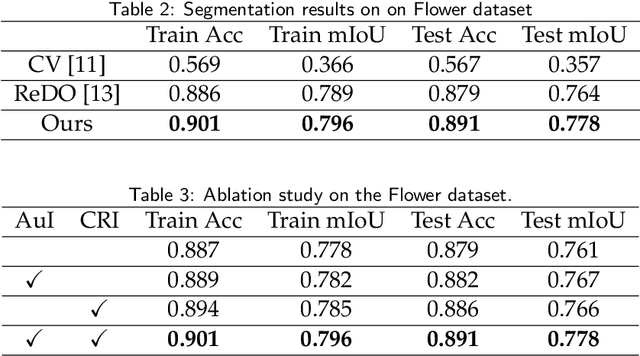
The Chan-Vese (CV) model is a classic region-based method in image segmentation. However, its piecewise constant assumption does not always hold for practical applications. Many improvements have been proposed but the issue is still far from well solved. In this work, we propose an unsupervised image segmentation approach that integrates the CV model with deep neural networks, which significantly improves the original CV model's segmentation accuracy. Our basic idea is to apply a deep neural network that maps the image into a latent space to alleviate the violation of the piecewise constant assumption in image space. We formulate this idea under the classic Bayesian framework by approximating the likelihood with an evidence lower bound (ELBO) term while keeping the prior term in the CV model. Thus, our model only needs the input image itself and does not require pre-training from external datasets. Moreover, we extend the idea to multi-phase case and dataset based unsupervised image segmentation. Extensive experiments validate the effectiveness of our model and show that the proposed method is noticeably better than other unsupervised segmentation approaches.
Self-Supervised Bulk Motion Artifact Removal in Optical Coherence Tomography Angiography
Mar 27, 2022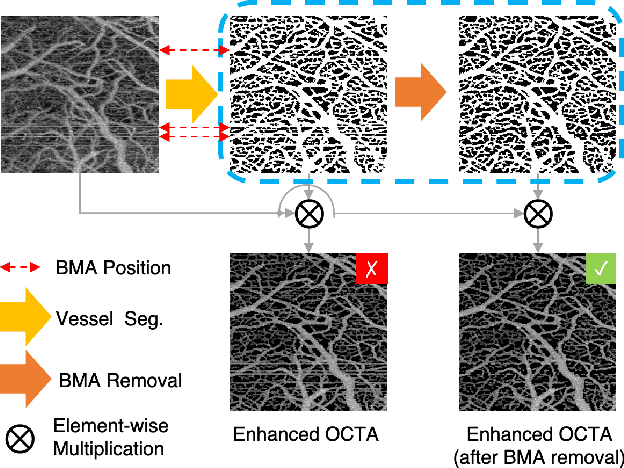
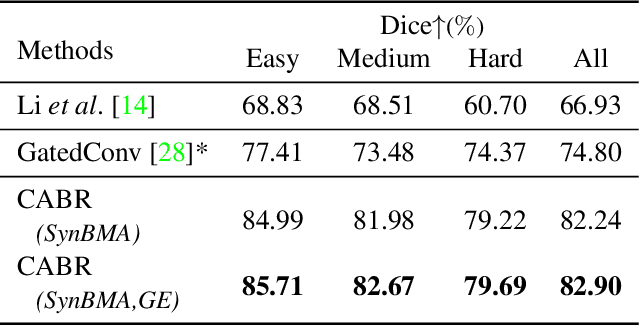
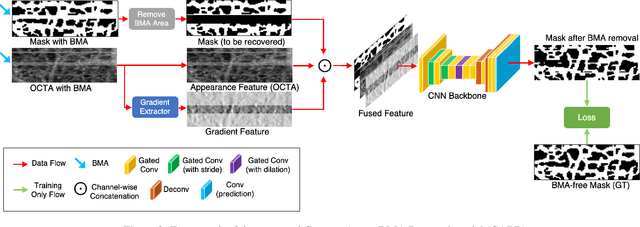
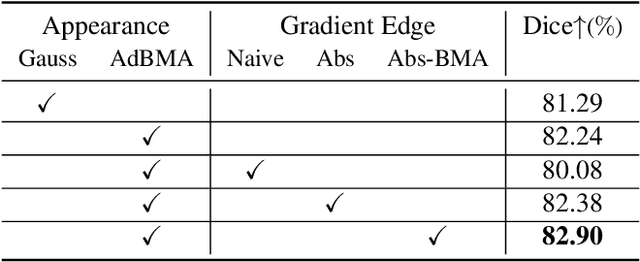
Optical coherence tomography angiography (OCTA) is an important imaging modality in many bioengineering tasks. The image quality of OCTA, however, is often degraded by Bulk Motion Artifacts (BMA), which are due to micromotion of subjects and typically appear as bright stripes surrounded by blurred areas. State-of-the-art methods usually treat BMA removal as a learning-based image inpainting problem, but require numerous training samples with nontrivial annotation. In addition, these methods discard the rich structural and appearance information carried in the BMA stripe region. To address these issues, in this paper we propose a self-supervised content-aware BMA removal model. First, the gradient-based structural information and appearance feature are extracted from the BMA area and injected into the model to capture more connectivity. Second, with easily collected defective masks, the model is trained in a self-supervised manner, in which only the clear areas are used for training while the BMA areas for inference. With the structural information and appearance feature from noisy image as references, our model can remove larger BMA and produce better visualizing result. In addition, only 2D images with defective masks are involved, hence improving the efficiency of our method. Experiments on OCTA of mouse cortex demonstrate that our model can remove most BMA with extremely large sizes and inconsistent intensities while previous methods fail.
Adjacent Context Coordination Network for Salient Object Detection in Optical Remote Sensing Images
Mar 25, 2022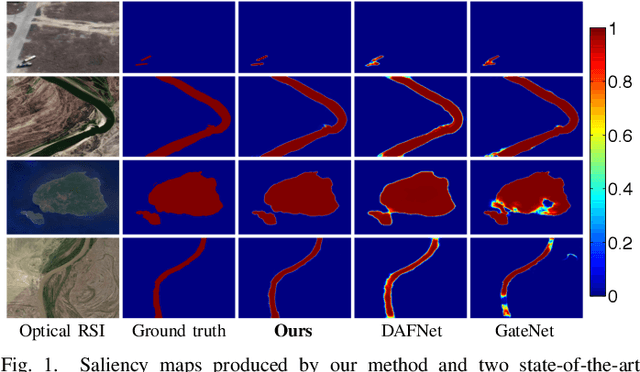
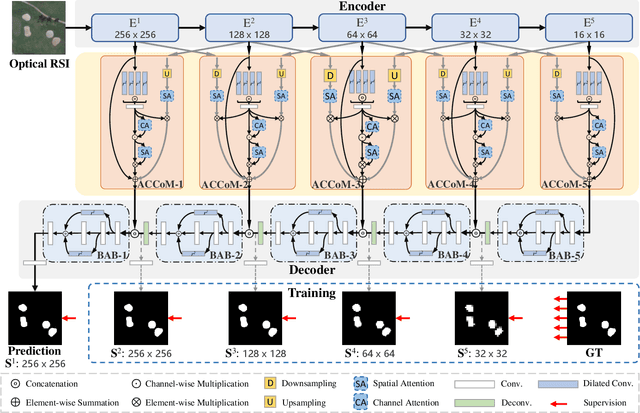

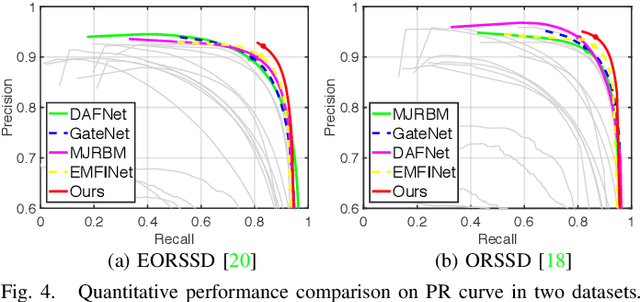
Salient object detection (SOD) in optical remote sensing images (RSIs), or RSI-SOD, is an emerging topic in understanding optical RSIs. However, due to the difference between optical RSIs and natural scene images (NSIs), directly applying NSI-SOD methods to optical RSIs fails to achieve satisfactory results. In this paper, we propose a novel Adjacent Context Coordination Network (ACCoNet) to explore the coordination of adjacent features in an encoder-decoder architecture for RSI-SOD. Specifically, ACCoNet consists of three parts: an encoder, Adjacent Context Coordination Modules (ACCoMs), and a decoder. As the key component of ACCoNet, ACCoM activates the salient regions of output features of the encoder and transmits them to the decoder. ACCoM contains a local branch and two adjacent branches to coordinate the multi-level features simultaneously. The local branch highlights the salient regions in an adaptive way, while the adjacent branches introduce global information of adjacent levels to enhance salient regions. Additionally, to extend the capabilities of the classic decoder block (i.e., several cascaded convolutional layers), we extend it with two bifurcations and propose a Bifurcation-Aggregation Block to capture the contextual information in the decoder. Extensive experiments on two benchmark datasets demonstrate that the proposed ACCoNet outperforms 22 state-of-the-art methods under nine evaluation metrics, and runs up to 81 fps on a single NVIDIA Titan X GPU. The code and results of our method are available at https://github.com/MathLee/ACCoNet.
EDTER: Edge Detection with Transformer
Mar 16, 2022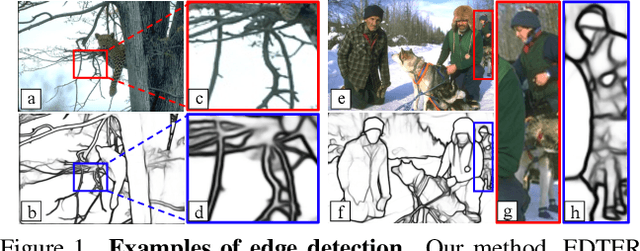

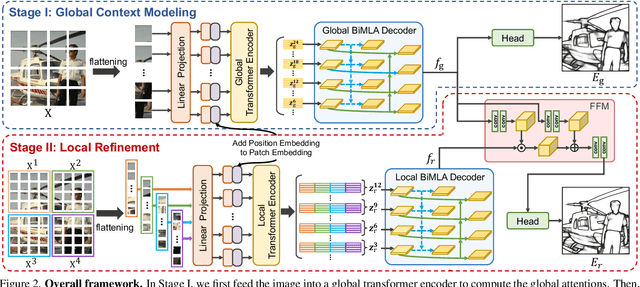
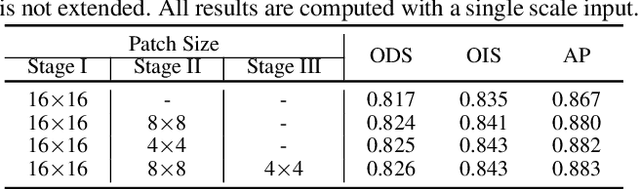
Convolutional neural networks have made significant progresses in edge detection by progressively exploring the context and semantic features. However, local details are gradually suppressed with the enlarging of receptive fields. Recently, vision transformer has shown excellent capability in capturing long-range dependencies. Inspired by this, we propose a novel transformer-based edge detector, \emph{Edge Detection TransformER (EDTER)}, to extract clear and crisp object boundaries and meaningful edges by exploiting the full image context information and detailed local cues simultaneously. EDTER works in two stages. In Stage I, a global transformer encoder is used to capture long-range global context on coarse-grained image patches. Then in Stage II, a local transformer encoder works on fine-grained patches to excavate the short-range local cues. Each transformer encoder is followed by an elaborately designed Bi-directional Multi-Level Aggregation decoder to achieve high-resolution features. Finally, the global context and local cues are combined by a Feature Fusion Module and fed into a decision head for edge prediction. Extensive experiments on BSDS500, NYUDv2, and Multicue demonstrate the superiority of EDTER in comparison with state-of-the-arts.
Consistency and Diversity induced Human Motion Segmentation
Feb 10, 2022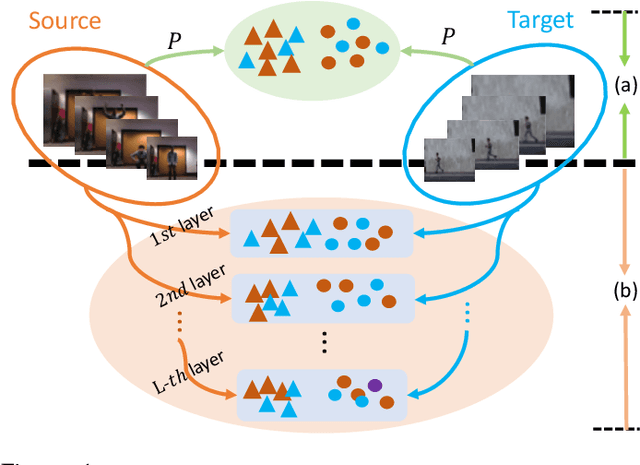

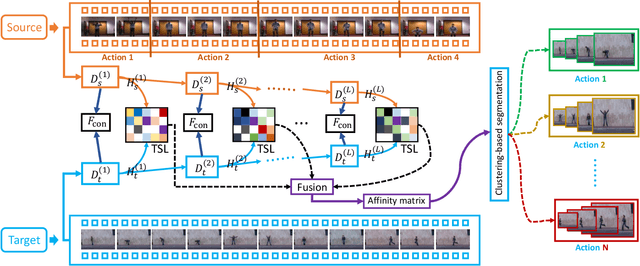
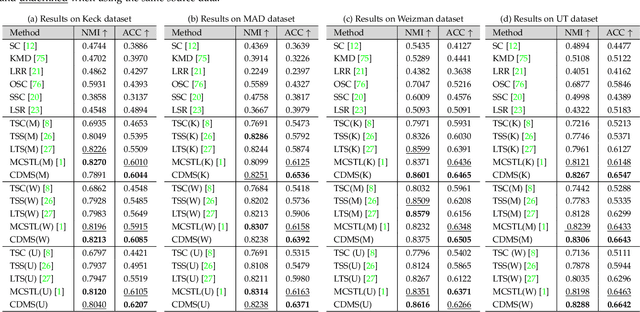
Subspace clustering is a classical technique that has been widely used for human motion segmentation and other related tasks. However, existing segmentation methods often cluster data without guidance from prior knowledge, resulting in unsatisfactory segmentation results. To this end, we propose a novel Consistency and Diversity induced human Motion Segmentation (CDMS) algorithm. Specifically, our model factorizes the source and target data into distinct multi-layer feature spaces, in which transfer subspace learning is conducted on different layers to capture multi-level information. A multi-mutual consistency learning strategy is carried out to reduce the domain gap between the source and target data. In this way, the domain-specific knowledge and domain-invariant properties can be explored simultaneously. Besides, a novel constraint based on the Hilbert Schmidt Independence Criterion (HSIC) is introduced to ensure the diversity of multi-level subspace representations, which enables the complementarity of multi-level representations to be explored to boost the transfer learning performance. Moreover, to preserve the temporal correlations, an enhanced graph regularizer is imposed on the learned representation coefficients and the multi-level representations of the source data. The proposed model can be efficiently solved using the Alternating Direction Method of Multipliers (ADMM) algorithm. Extensive experimental results on public human motion datasets demonstrate the effectiveness of our method against several state-of-the-art approaches.
Deep Probabilistic Graph Matching
Jan 05, 2022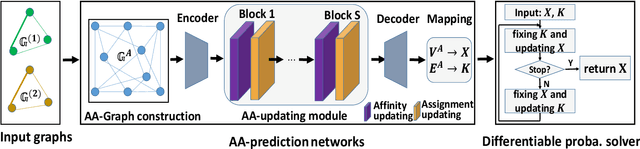
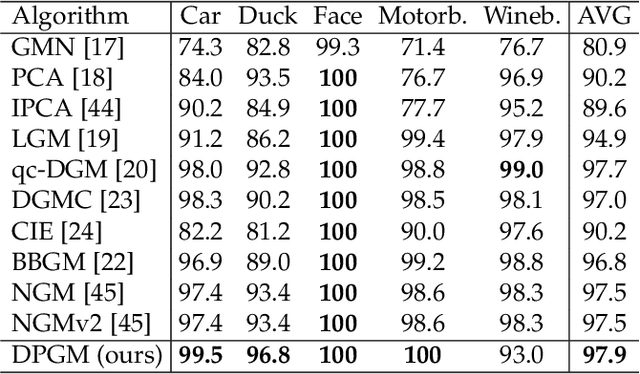
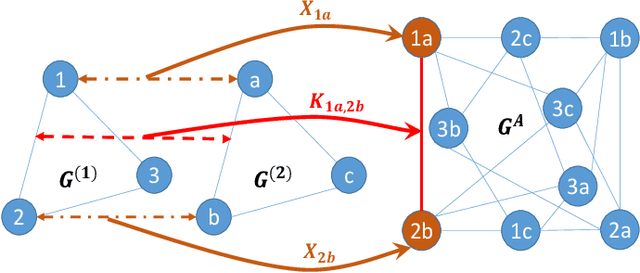
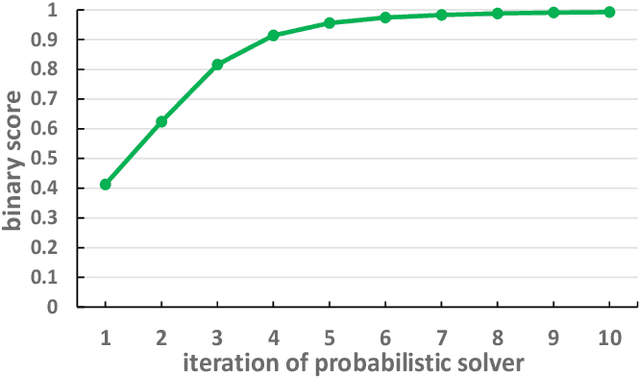
Most previous learning-based graph matching algorithms solve the \textit{quadratic assignment problem} (QAP) by dropping one or more of the matching constraints and adopting a relaxed assignment solver to obtain sub-optimal correspondences. Such relaxation may actually weaken the original graph matching problem, and in turn hurt the matching performance. In this paper we propose a deep learning-based graph matching framework that works for the original QAP without compromising on the matching constraints. In particular, we design an affinity-assignment prediction network to jointly learn the pairwise affinity and estimate the node assignments, and we then develop a differentiable solver inspired by the probabilistic perspective of the pairwise affinities. Aiming to obtain better matching results, the probabilistic solver refines the estimated assignments in an iterative manner to impose both discrete and one-to-one matching constraints. The proposed method is evaluated on three popularly tested benchmarks (Pascal VOC, Willow Object and SPair-71k), and it outperforms all previous state-of-the-arts on all benchmarks.
SwinTrack: A Simple and Strong Baseline for Transformer Tracking
Dec 08, 2021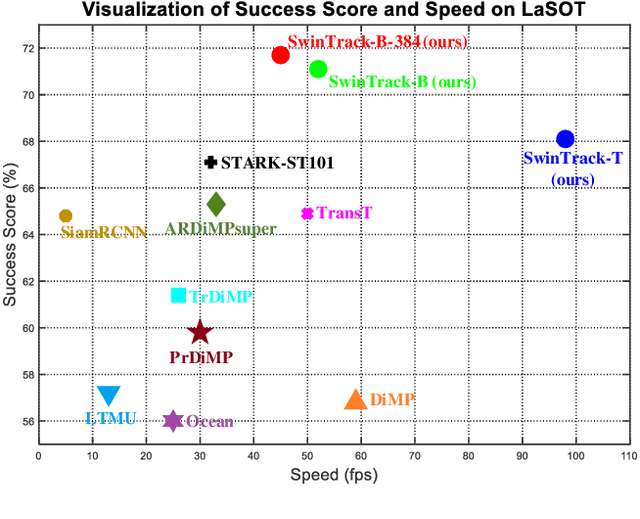
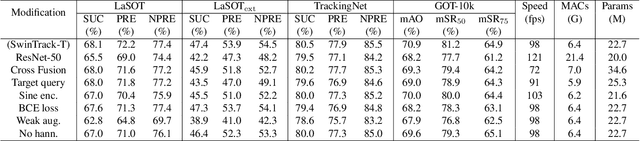
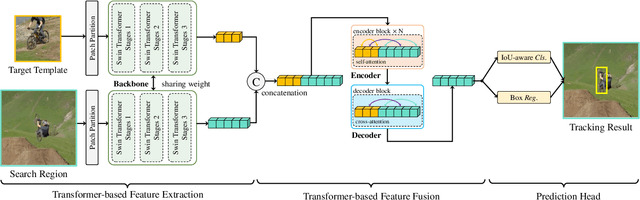
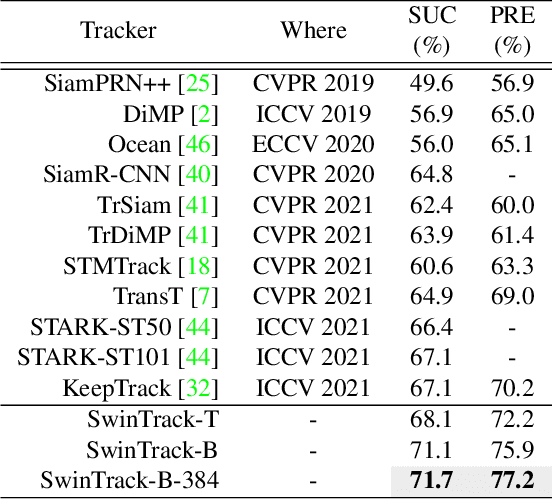
Transformer has recently demonstrated clear potential in improving visual tracking algorithms. Nevertheless, existing transformer-based trackers mostly use Transformer to fuse and enhance the features generated by convolutional neural networks (CNNs). By contrast, in this paper, we propose a fully attentional-based Transformer tracking algorithm, Swin-Transformer Tracker (SwinTrack). SwinTrack uses Transformer for both feature extraction and feature fusion, allowing full interactions between the target object and the search region for tracking. To further improve performance, we investigate comprehensively different strategies for feature fusion, position encoding, and training loss. All these efforts make SwinTrack a simple yet solid baseline. In our thorough experiments, SwinTrack sets a new record with 0.702 SUC on LaSOT, surpassing STARK by 3.1% while still running at 45 FPS. Besides, it achieves state-of-the-art performances with 0.476 SUC, 0.840 SUC and 0.694 AO on other challenging LaSOT$_{ext}$, TrackingNet, and GOT-10k datasets. Our implementation and trained models are available at https://github.com/LitingLin/SwinTrack.