 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrift-Resilient Temporal Priors for Visual Tracking
Apr 03, 2026Temporal information is crucial for visual tracking, but existing multi-frame trackers are vulnerable to model drift caused by naively aggregating noisy historical predictions. In this paper, we introduce DTPTrack, a lightweight and generalizable module designed to be seamlessly integrated into existing trackers to suppress drift. Our framework consists of two core components: (1) a Temporal Reliability Calibrator (TRC) mechanism that learns to assign a per-frame reliability score to historical states, filtering out noise while anchoring on the ground-truth template; and (2) a Temporal Guidance Synthesizer (TGS) module that synthesizes this calibrated history into a compact set of dynamic temporal priors to provide predictive guidance. To demonstrate its versatility, we integrate DTPTrack into three diverse tracking architectures--OSTrack, ODTrack, and LoRAT-and show consistent, significant performance gains across all baselines. Our best-performing model, built upon an extended LoRATv2 backbone, sets a new state-of-the-art on several benchmarks, achieving a 77.5% Success rate on LaSOT and an 80.3% AO on GOT-10k.
Retromorphic Testing with Hierarchical Verification for Hallucination Detection in RAG
Mar 29, 2026Large language models (LLMs) continue to hallucinate in retrieval-augmented generation (RAG), producing claims that are unsupported by or conflict with the retrieved context. Detecting such errors remains challenging when faithfulness is evaluated solely with respect to the retrieved context. Existing approaches either provide coarse-grained, answer-level scores or focus on open-domain factuality, often lacking fine-grained, evidence-grounded diagnostics. We present RT4CHART, a retromorphic testing framework for context-faithfulness assessment. RT4CHART decomposes model outputs into independently verifiable claims and performs hierarchical, local-to-global verification against the retrieved context. Each claim is assigned one of three labels: entailed, contradicted, or baseless. Furthermore, RT4CHART maps claim-level decisions back to specific answer spans and retrieves explicit supporting or refuting evidence from the context, enabling fine-grained and interpretable auditing. We evaluate RT4CHART on RAGTruth++ (408 samples) and RAGTruth-Enhance (2,675 samples), a newly re-annotated benchmark. RT4CHART achieves the best answer-level hallucination detection F1 among all baselines. On RAGTruth++, it reaches an F1 score of 0.776, outperforming the strongest baseline by 83%. On RAGTruth-Enhance, it achieves a span-level F1 of 47.5%. Ablation studies show that the hierarchical verification design is the primary driver of performance gains. Finally, our re-annotation reveals 1.68x more hallucination cases than the original labels, suggesting that existing benchmarks substantially underestimate the prevalence of hallucinations.
Tracking Meets LoRA: Faster Training, Larger Model, Stronger Performance
Mar 08, 2024



Motivated by the Parameter-Efficient Fine-Tuning (PEFT) in large language models, we propose LoRAT, a method that unveils the power of larger Vision Transformers (ViT) for tracking within laboratory-level resources. The essence of our work lies in adapting LoRA, a technique that fine-tunes a small subset of model parameters without adding inference latency, to the domain of visual tracking. However, unique challenges and potential domain gaps make this transfer not as easy as the first intuition. Firstly, a transformer-based tracker constructs unshared position embedding for template and search image. This poses a challenge for the transfer of LoRA, usually requiring consistency in the design when applied to the pre-trained backbone, to downstream tasks. Secondly, the inductive bias inherent in convolutional heads diminishes the effectiveness of parameter-efficient fine-tuning in tracking models. To overcome these limitations, we first decouple the position embeddings in transformer-based trackers into shared spatial ones and independent type ones. The shared embeddings, which describe the absolute coordinates of multi-resolution images (namely, the template and search images), are inherited from the pre-trained backbones. In contrast, the independent embeddings indicate the sources of each token and are learned from scratch. Furthermore, we design an anchor-free head solely based on a multilayer perceptron (MLP) to adapt PETR, enabling better performance with less computational overhead. With our design, 1) it becomes practical to train trackers with the ViT-g backbone on GPUs with only memory of 25.8GB (batch size of 16); 2) we reduce the training time of the L-224 variant from 35.0 to 10.8 GPU hours; 3) we improve the LaSOT SUC score from 0.703 to 0.743 with the L-224 variant; 4) we fast the inference speed of the L-224 variant from 52 to 119 FPS. Code and models will be released.
SwinTrack: A Simple and Strong Baseline for Transformer Tracking
Dec 08, 2021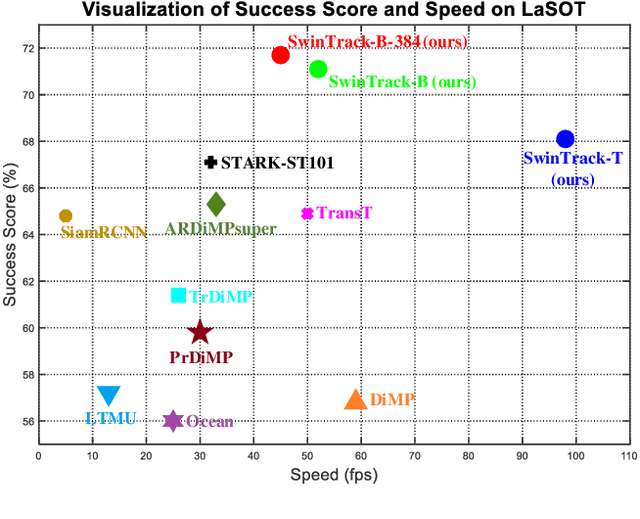
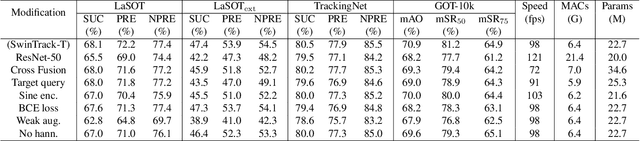
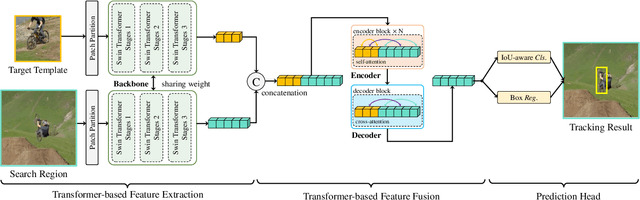
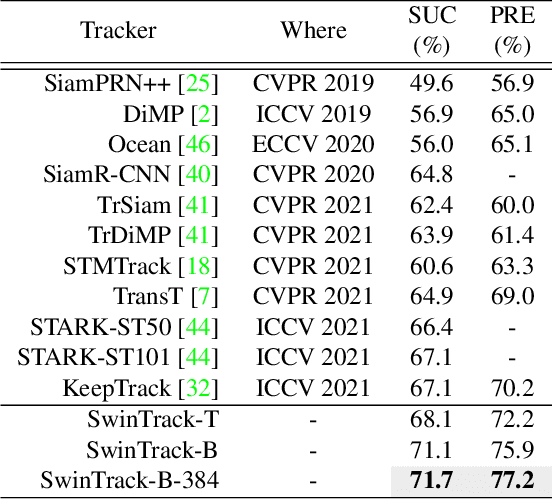
Transformer has recently demonstrated clear potential in improving visual tracking algorithms. Nevertheless, existing transformer-based trackers mostly use Transformer to fuse and enhance the features generated by convolutional neural networks (CNNs). By contrast, in this paper, we propose a fully attentional-based Transformer tracking algorithm, Swin-Transformer Tracker (SwinTrack). SwinTrack uses Transformer for both feature extraction and feature fusion, allowing full interactions between the target object and the search region for tracking. To further improve performance, we investigate comprehensively different strategies for feature fusion, position encoding, and training loss. All these efforts make SwinTrack a simple yet solid baseline. In our thorough experiments, SwinTrack sets a new record with 0.702 SUC on LaSOT, surpassing STARK by 3.1% while still running at 45 FPS. Besides, it achieves state-of-the-art performances with 0.476 SUC, 0.840 SUC and 0.694 AO on other challenging LaSOT$_{ext}$, TrackingNet, and GOT-10k datasets. Our implementation and trained models are available at https://github.com/LitingLin/SwinTrack.
LaSOT: A High-quality Large-scale Single Object Tracking Benchmark
Sep 12, 2020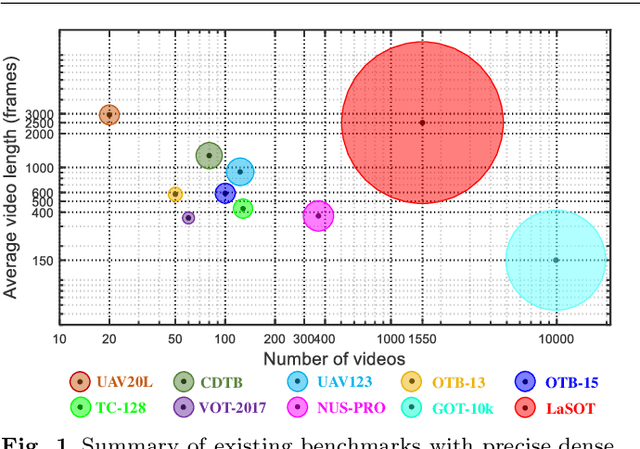
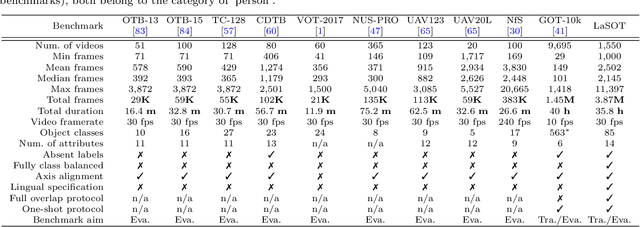
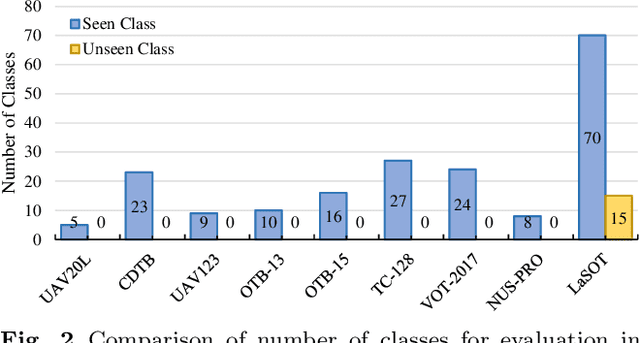

Despite great recent advances in visual tracking, its further development, including both algorithm design and evaluation, is limited due to lack of dedicated large-scale benchmarks. To address this problem, we present LaSOT, a high-quality Large-scale Single Object Tracking benchmark. LaSOT contains a diverse selection of 85 object classes, and offers 1,550 totaling more than 3.87 million frames. Each video frame is carefully and manually annotated with a bounding box. This makes LaSOT, to our knowledge, the largest densely annotated tracking benchmark. Our goal in releasing LaSOT is to provide a dedicated high quality platform for both training and evaluation of trackers. The average video length of LaSOT is around 2,500 frames, where each video contains various challenge factors that exist in real world video footage,such as the targets disappearing and re-appearing. These longer video lengths allow for the assessment of long-term trackers. To take advantage of the close connection between visual appearance and natural language, we provide language specification for each video in LaSOT. We believe such additions will allow for future research to use linguistic features to improve tracking. Two protocols, full-overlap and one-shot, are designated for flexible assessment of trackers. We extensively evaluate 48 baseline trackers on LaSOT with in-depth analysis, and results reveal that there still exists significant room for improvement. The complete benchmark, tracking results as well as analysis are available at http://vision.cs.stonybrook.edu/~lasot/.
LaSOT: A High-quality Benchmark for Large-scale Single Object Tracking
Sep 20, 2018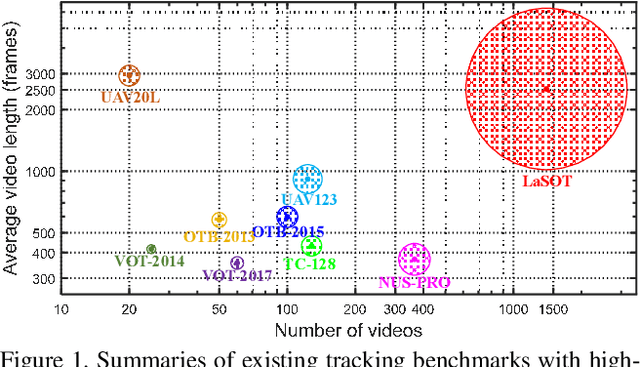
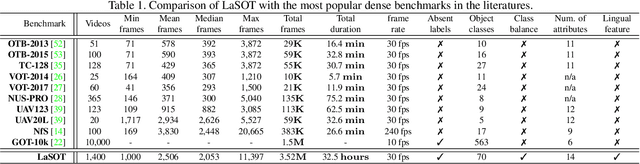


In this paper, we present LaSOT, a high-quality benchmark for Large-scale Single Object Tracking. LaSOT consists of 1,400 sequences with more than 3.5M frames in total. Each frame in these sequences is carefully and manually annotated with a bounding box, making LaSOT the largest, to the best of our knowledge, densely annotated tracking benchmark. The average sequence length of LaSOT is more than 2,500 frames, and each sequence comprises various challenges deriving from the wild where target objects may disappear and re-appear again in the view. By releasing LaSOT, we expect to provide the community a large-scale dedicated benchmark with high-quality for both the training of deep trackers and the veritable evaluation of tracking algorithms. Moreover, considering the close connections of visual appearance and natural language, we enrich LaSOT by providing additional language specification, aiming at encouraging the exploration of natural linguistic feature for tracking. A thorough experimental evaluation of 35 tracking algorithms on LaSOT is presented with detailed analysis, and the results demonstrate that there is still a big room to improvements. The benchmark and evaluation results are made publicly available at https://cis.temple.edu/lasot/.