 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSync4D: Video Guided Controllable Dynamics for Physics-Based 4D Generation
May 27, 2024



In this work, we introduce a novel approach for creating controllable dynamics in 3D-generated Gaussians using casually captured reference videos. Our method transfers the motion of objects from reference videos to a variety of generated 3D Gaussians across different categories, ensuring precise and customizable motion transfer. We achieve this by employing blend skinning-based non-parametric shape reconstruction to extract the shape and motion of reference objects. This process involves segmenting the reference objects into motion-related parts based on skinning weights and establishing shape correspondences with generated target shapes. To address shape and temporal inconsistencies prevalent in existing methods, we integrate physical simulation, driving the target shapes with matched motion. This integration is optimized through a displacement loss to ensure reliable and genuine dynamics. Our approach supports diverse reference inputs, including humans, quadrupeds, and articulated objects, and can generate dynamics of arbitrary length, providing enhanced fidelity and applicability. Unlike methods heavily reliant on diffusion video generation models, our technique offers specific and high-quality motion transfer, maintaining both shape integrity and temporal consistency.
PS-CAD: Local Geometry Guidance via Prompting and Selection for CAD Reconstruction
May 24, 2024Reverse engineering CAD models from raw geometry is a classic but challenging research problem. In particular, reconstructing the CAD modeling sequence from point clouds provides great interpretability and convenience for editing. To improve upon this problem, we introduce geometric guidance into the reconstruction network. Our proposed model, PS-CAD, reconstructs the CAD modeling sequence one step at a time. At each step, we provide two forms of geometric guidance. First, we provide the geometry of surfaces where the current reconstruction differs from the complete model as a point cloud. This helps the framework to focus on regions that still need work. Second, we use geometric analysis to extract a set of planar prompts, that correspond to candidate surfaces where a CAD extrusion step could be started. Our framework has three major components. Geometric guidance computation extracts the two types of geometric guidance. Single-step reconstruction computes a single candidate CAD modeling step for each provided prompt. Single-step selection selects among the candidate CAD modeling steps. The process continues until the reconstruction is completed. Our quantitative results show a significant improvement across all metrics. For example, on the dataset DeepCAD, PS-CAD improves upon the best published SOTA method by reducing the geometry errors (CD and HD) by 10%, and the structural error (ECD metric) by about 15%.
REACTO: Reconstructing Articulated Objects from a Single Video
Apr 17, 2024



In this paper, we address the challenge of reconstructing general articulated 3D objects from a single video. Existing works employing dynamic neural radiance fields have advanced the modeling of articulated objects like humans and animals from videos, but face challenges with piece-wise rigid general articulated objects due to limitations in their deformation models. To tackle this, we propose Quasi-Rigid Blend Skinning, a novel deformation model that enhances the rigidity of each part while maintaining flexible deformation of the joints. Our primary insight combines three distinct approaches: 1) an enhanced bone rigging system for improved component modeling, 2) the use of quasi-sparse skinning weights to boost part rigidity and reconstruction fidelity, and 3) the application of geodesic point assignment for precise motion and seamless deformation. Our method outperforms previous works in producing higher-fidelity 3D reconstructions of general articulated objects, as demonstrated on both real and synthetic datasets. Project page: https://chaoyuesong.github.io/REACTO.
Magic-Boost: Boost 3D Generation with Mutli-View Conditioned Diffusion
Apr 09, 2024Benefiting from the rapid development of 2D diffusion models, 3D content creation has made significant progress recently. One promising solution involves the fine-tuning of pre-trained 2D diffusion models to harness their capacity for producing multi-view images, which are then lifted into accurate 3D models via methods like fast-NeRFs or large reconstruction models. However, as inconsistency still exists and limited generated resolution, the generation results of such methods still lack intricate textures and complex geometries. To solve this problem, we propose Magic-Boost, a multi-view conditioned diffusion model that significantly refines coarse generative results through a brief period of SDS optimization ($\sim15$min). Compared to the previous text or single image based diffusion models, Magic-Boost exhibits a robust capability to generate images with high consistency from pseudo synthesized multi-view images. It provides precise SDS guidance that well aligns with the identity of the input images, enriching the local detail in both geometry and texture of the initial generative results. Extensive experiments show Magic-Boost greatly enhances the coarse inputs and generates high-quality 3D assets with rich geometric and textural details. (Project Page: https://magic-research.github.io/magic-boost/)
Self-Supervised Class-Agnostic Motion Prediction with Spatial and Temporal Consistency Regularizations
Mar 21, 2024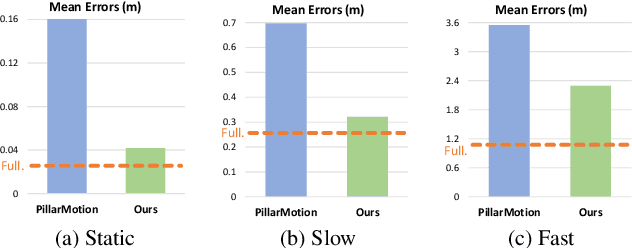
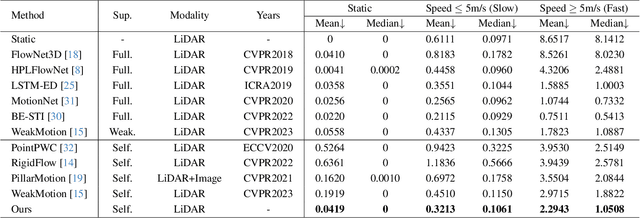
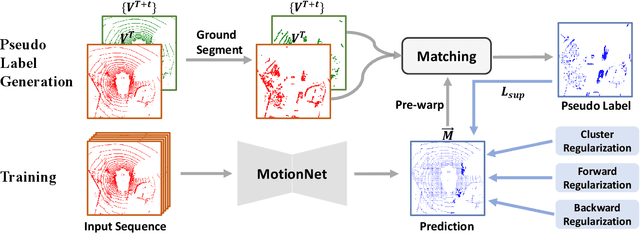
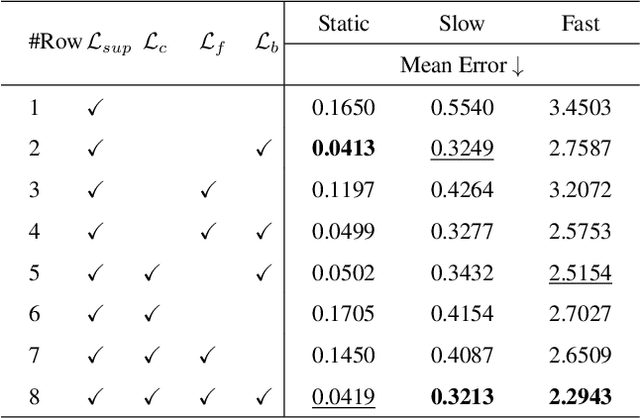
The perception of motion behavior in a dynamic environment holds significant importance for autonomous driving systems, wherein class-agnostic motion prediction methods directly predict the motion of the entire point cloud. While most existing methods rely on fully-supervised learning, the manual labeling of point cloud data is laborious and time-consuming. Therefore, several annotation-efficient methods have been proposed to address this challenge. Although effective, these methods rely on weak annotations or additional multi-modal data like images, and the potential benefits inherent in the point cloud sequence are still underexplored. To this end, we explore the feasibility of self-supervised motion prediction with only unlabeled LiDAR point clouds. Initially, we employ an optimal transport solver to establish coarse correspondences between current and future point clouds as the coarse pseudo motion labels. Training models directly using such coarse labels leads to noticeable spatial and temporal prediction inconsistencies. To mitigate these issues, we introduce three simple spatial and temporal regularization losses, which facilitate the self-supervised training process effectively. Experimental results demonstrate the significant superiority of our approach over the state-of-the-art self-supervised methods.
Sculpt3D: Multi-View Consistent Text-to-3D Generation with Sparse 3D Prior
Mar 14, 2024



Recent works on text-to-3d generation show that using only 2D diffusion supervision for 3D generation tends to produce results with inconsistent appearances (e.g., faces on the back view) and inaccurate shapes (e.g., animals with extra legs). Existing methods mainly address this issue by retraining diffusion models with images rendered from 3D data to ensure multi-view consistency while struggling to balance 2D generation quality with 3D consistency. In this paper, we present a new framework Sculpt3D that equips the current pipeline with explicit injection of 3D priors from retrieved reference objects without re-training the 2D diffusion model. Specifically, we demonstrate that high-quality and diverse 3D geometry can be guaranteed by keypoints supervision through a sparse ray sampling approach. Moreover, to ensure accurate appearances of different views, we further modulate the output of the 2D diffusion model to the correct patterns of the template views without altering the generated object's style. These two decoupled designs effectively harness 3D information from reference objects to generate 3D objects while preserving the generation quality of the 2D diffusion model. Extensive experiments show our method can largely improve the multi-view consistency while retaining fidelity and diversity. Our project page is available at: https://stellarcheng.github.io/Sculpt3D/.
S-DyRF: Reference-Based Stylized Radiance Fields for Dynamic Scenes
Mar 13, 2024



Current 3D stylization methods often assume static scenes, which violates the dynamic nature of our real world. To address this limitation, we present S-DyRF, a reference-based spatio-temporal stylization method for dynamic neural radiance fields. However, stylizing dynamic 3D scenes is inherently challenging due to the limited availability of stylized reference images along the temporal axis. Our key insight lies in introducing additional temporal cues besides the provided reference. To this end, we generate temporal pseudo-references from the given stylized reference. These pseudo-references facilitate the propagation of style information from the reference to the entire dynamic 3D scene. For coarse style transfer, we enforce novel views and times to mimic the style details present in pseudo-references at the feature level. To preserve high-frequency details, we create a collection of stylized temporal pseudo-rays from temporal pseudo-references. These pseudo-rays serve as detailed and explicit stylization guidance for achieving fine style transfer. Experiments on both synthetic and real-world datasets demonstrate that our method yields plausible stylized results of space-time view synthesis on dynamic 3D scenes.
Fine Structure-Aware Sampling: A New Sampling Training Scheme for Pixel-Aligned Implicit Models in Single-View Human Reconstruction
Feb 29, 2024



Pixel-aligned implicit models, such as PIFu, PIFuHD, and ICON, are used for single-view clothed human reconstruction. These models need to be trained using a sampling training scheme. Existing sampling training schemes either fail to capture thin surfaces (e.g. ears, fingers) or cause noisy artefacts in reconstructed meshes. To address these problems, we introduce Fine Structured-Aware Sampling (FSS), a new sampling training scheme to train pixel-aligned implicit models for single-view human reconstruction. FSS resolves the aforementioned problems by proactively adapting to the thickness and complexity of surfaces. In addition, unlike existing sampling training schemes, FSS shows how normals of sample points can be capitalized in the training process to improve results. Lastly, to further improve the training process, FSS proposes a mesh thickness loss signal for pixel-aligned implicit models. It becomes computationally feasible to introduce this loss once a slight reworking of the pixel-aligned implicit function framework is carried out. Our results show that our methods significantly outperform SOTA methods qualitatively and quantitatively. Our code is publicly available at https://github.com/kcyt/FSS.
Style-Consistent 3D Indoor Scene Synthesis with Decoupled Objects
Jan 24, 2024Controllable 3D indoor scene synthesis stands at the forefront of technological progress, offering various applications like gaming, film, and augmented/virtual reality. The capability to stylize and de-couple objects within these scenarios is a crucial factor, providing an advanced level of control throughout the editing process. This control extends not just to manipulating geometric attributes like translation and scaling but also includes managing appearances, such as stylization. Current methods for scene stylization are limited to applying styles to the entire scene, without the ability to separate and customize individual objects. Addressing the intricacies of this challenge, we introduce a unique pipeline designed for synthesis 3D indoor scenes. Our approach involves strategically placing objects within the scene, utilizing information from professionally designed bounding boxes. Significantly, our pipeline prioritizes maintaining style consistency across multiple objects within the scene, ensuring a cohesive and visually appealing result aligned with the desired aesthetic. The core strength of our pipeline lies in its ability to generate 3D scenes that are not only visually impressive but also exhibit features like photorealism, multi-view consistency, and diversity. These scenes are crafted in response to various natural language prompts, demonstrating the versatility and adaptability of our model.
Semi-Supervised Class-Agnostic Motion Prediction with Pseudo Label Regeneration and BEVMix
Dec 14, 2023



Class-agnostic motion prediction methods aim to comprehend motion within open-world scenarios, holding significance for autonomous driving systems. However, training a high-performance model in a fully-supervised manner always requires substantial amounts of manually annotated data, which can be both expensive and time-consuming to obtain. To address this challenge, our study explores the potential of semi-supervised learning (SSL) for class-agnostic motion prediction. Our SSL framework adopts a consistency-based self-training paradigm, enabling the model to learn from unlabeled data by generating pseudo labels through test-time inference. To improve the quality of pseudo labels, we propose a novel motion selection and re-generation module. This module effectively selects reliable pseudo labels and re-generates unreliable ones. Furthermore, we propose two data augmentation strategies: temporal sampling and BEVMix. These strategies facilitate consistency regularization in SSL. Experiments conducted on nuScenes demonstrate that our SSL method can surpass the self-supervised approach by a large margin by utilizing only a tiny fraction of labeled data. Furthermore, our method exhibits comparable performance to weakly and some fully supervised methods. These results highlight the ability of our method to strike a favorable balance between annotation costs and performance. Code will be available at https://github.com/kwwcv/SSMP.