 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSS-DepthNet: Depth Prediction with Multi-Step Spiking Neural Network
Nov 22, 2022



Event cameras are considered to have great potential for computer vision and robotics applications because of their high temporal resolution and low power consumption characteristics. However, the event stream output from event cameras has asynchronous, sparse characteristics that existing computer vision algorithms cannot handle. Spiking neural network is a novel event-based computational paradigm that is considered to be well suited for processing event camera tasks. However, direct training of deep SNNs suffers from degradation problems. This work addresses these problems by proposing a spiking neural network architecture with a novel residual block designed and multi-dimension attention modules combined, focusing on the problem of depth prediction. In addition, a novel event stream representation method is explicitly proposed for SNNs. This model outperforms previous ANN networks of the same size on the MVSEC dataset and shows great computational efficiency.
HARDVS: Revisiting Human Activity Recognition with Dynamic Vision Sensors
Nov 17, 2022



The main streams of human activity recognition (HAR) algorithms are developed based on RGB cameras which are suffered from illumination, fast motion, privacy-preserving, and large energy consumption. Meanwhile, the biologically inspired event cameras attracted great interest due to their unique features, such as high dynamic range, dense temporal but sparse spatial resolution, low latency, low power, etc. As it is a newly arising sensor, even there is no realistic large-scale dataset for HAR. Considering its great practical value, in this paper, we propose a large-scale benchmark dataset to bridge this gap, termed HARDVS, which contains 300 categories and more than 100K event sequences. We evaluate and report the performance of multiple popular HAR algorithms, which provide extensive baselines for future works to compare. More importantly, we propose a novel spatial-temporal feature learning and fusion framework, termed ESTF, for event stream based human activity recognition. It first projects the event streams into spatial and temporal embeddings using StemNet, then, encodes and fuses the dual-view representations using Transformer networks. Finally, the dual features are concatenated and fed into a classification head for activity prediction. Extensive experiments on multiple datasets fully validated the effectiveness of our model. Both the dataset and source code will be released on \url{https://github.com/Event-AHU/HARDVS}.
Attention Spiking Neural Networks
Sep 28, 2022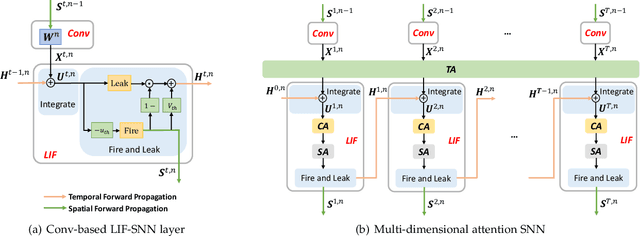
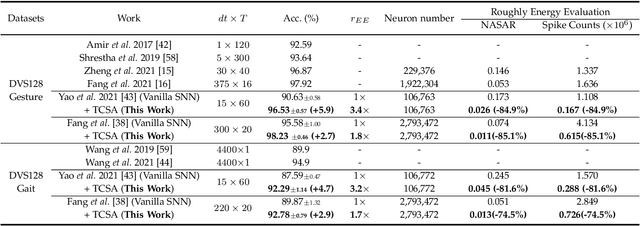
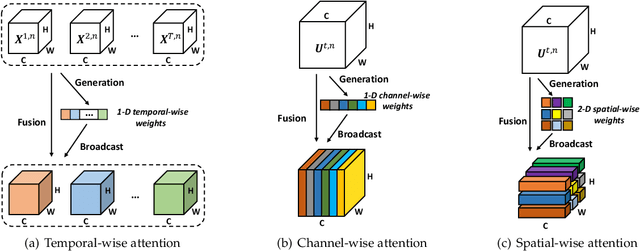
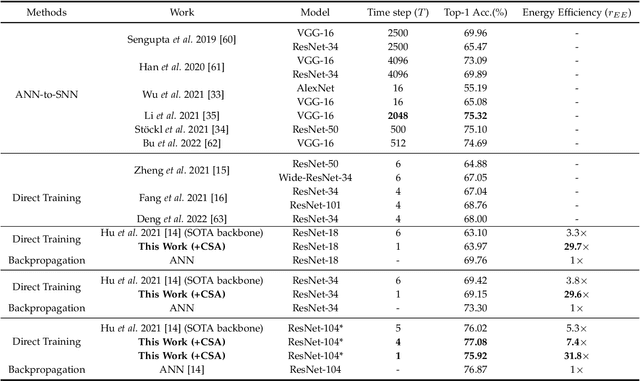
Benefiting from the event-driven and sparse spiking characteristics of the brain, spiking neural networks (SNNs) are becoming an energy-efficient alternative to artificial neural networks (ANNs). However, the performance gap between SNNs and ANNs has been a great hindrance to deploying SNNs ubiquitously for a long time. To leverage the full potential of SNNs, we study the effect of attention mechanisms in SNNs. We first present our idea of attention with a plug-and-play kit, termed the Multi-dimensional Attention (MA). Then, a new attention SNN architecture with end-to-end training called "MA-SNN" is proposed, which infers attention weights along the temporal, channel, as well as spatial dimensions separately or simultaneously. Based on the existing neuroscience theories, we exploit the attention weights to optimize membrane potentials, which in turn regulate the spiking response in a data-dependent way. At the cost of negligible additional parameters, MA facilitates vanilla SNNs to achieve sparser spiking activity, better performance, and energy efficiency concurrently. Experiments are conducted in event-based DVS128 Gesture/Gait action recognition and ImageNet-1k image classification. On Gesture/Gait, the spike counts are reduced by 84.9%/81.6%, and the task accuracy and energy efficiency are improved by 5.9%/4.7% and 3.4$\times$/3.2$\times$. On ImageNet-1K, we achieve top-1 accuracy of 75.92% and 77.08% on single/4-step Res-SNN-104, which are state-of-the-art results in SNNs. To our best knowledge, this is for the first time, that the SNN community achieves comparable or even better performance compared with its ANN counterpart in the large-scale dataset. Our work lights up SNN's potential as a general backbone to support various applications for SNNs, with a great balance between effectiveness and efficiency.
Boosting Zero-shot Learning via Contrastive Optimization of Attribute Representations
Jul 11, 2022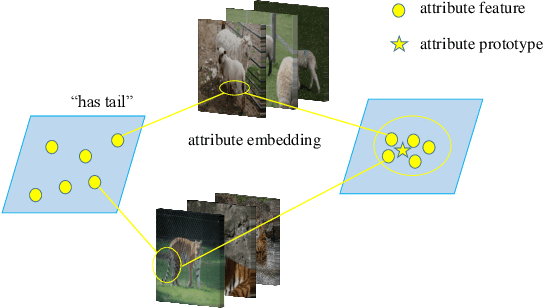
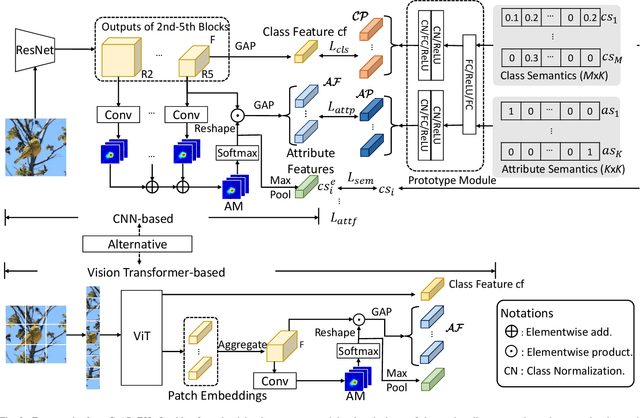
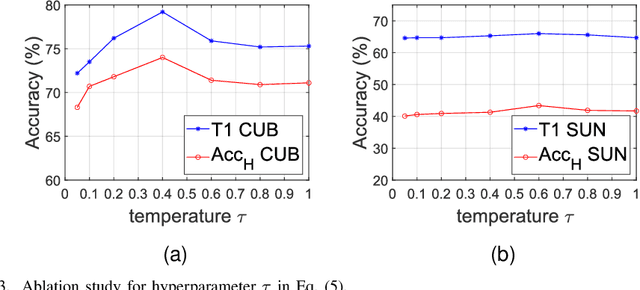
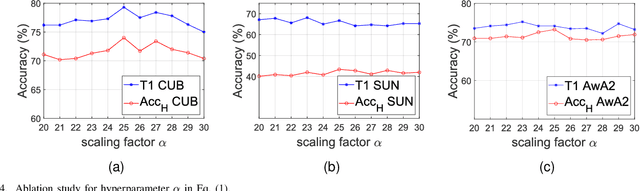
Zero-shot learning (ZSL) aims to recognize classes that do not have samples in the training set. One representative solution is to directly learn an embedding function associating visual features with corresponding class semantics for recognizing new classes. Many methods extend upon this solution, and recent ones are especially keen on extracting rich features from images, e.g. attribute features. These attribute features are normally extracted within each individual image; however, the common traits for features across images yet belonging to the same attribute are not emphasized. In this paper, we propose a new framework to boost ZSL by explicitly learning attribute prototypes beyond images and contrastively optimizing them with attribute-level features within images. Besides the novel architecture, two elements are highlighted for attribute representations: a new prototype generation module is designed to generate attribute prototypes from attribute semantics; a hard example-based contrastive optimization scheme is introduced to reinforce attribute-level features in the embedding space. We explore two alternative backbones, CNN-based and transformer-based, to build our framework and conduct experiments on three standard benchmarks, CUB, SUN, AwA2. Results on these benchmarks demonstrate that our method improves the state of the art by a considerable margin. Our codes will be available at https://github.com/dyabel/CoAR-ZSL.git
Learning to Prompt for Open-Vocabulary Object Detection with Vision-Language Model
Mar 28, 2022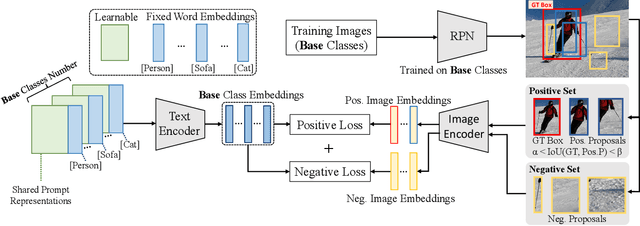
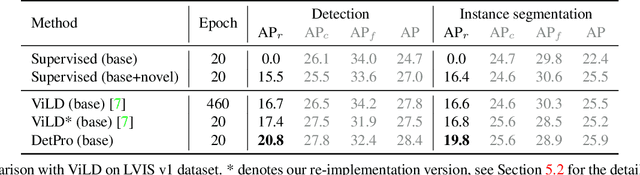
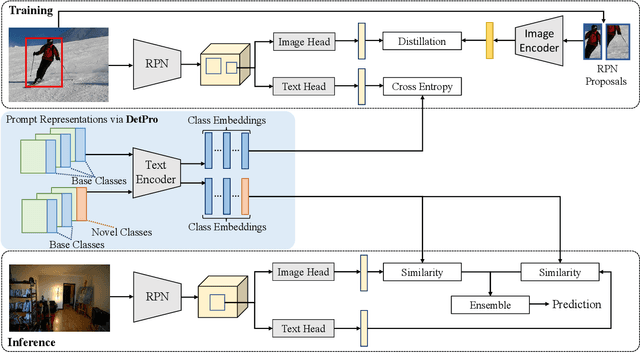

Recently, vision-language pre-training shows great potential in open-vocabulary object detection, where detectors trained on base classes are devised for detecting new classes. The class text embedding is firstly generated by feeding prompts to the text encoder of a pre-trained vision-language model. It is then used as the region classifier to supervise the training of a detector. The key element that leads to the success of this model is the proper prompt, which requires careful words tuning and ingenious design. To avoid laborious prompt engineering, there are some prompt representation learning methods being proposed for the image classification task, which however can only be sub-optimal solutions when applied to the detection task. In this paper, we introduce a novel method, detection prompt (DetPro), to learn continuous prompt representations for open-vocabulary object detection based on the pre-trained vision-language model. Different from the previous classification-oriented methods, DetPro has two highlights: 1) a background interpretation scheme to include the proposals in image background into the prompt training; 2) a context grading scheme to separate proposals in image foreground for tailored prompt training. We assemble DetPro with ViLD, a recent state-of-the-art open-world object detector, and conduct experiments on the LVIS as well as transfer learning on the Pascal VOC, COCO, Objects365 datasets. Experimental results show that our DetPro outperforms the baseline ViLD in all settings, e.g., +3.4 APbox and +3.0 APmask improvements on the novel classes of LVIS. Code and models are available at https://github.com/dyabel/detpro.
Rethinking Pretraining as a Bridge from ANNs to SNNs
Mar 04, 2022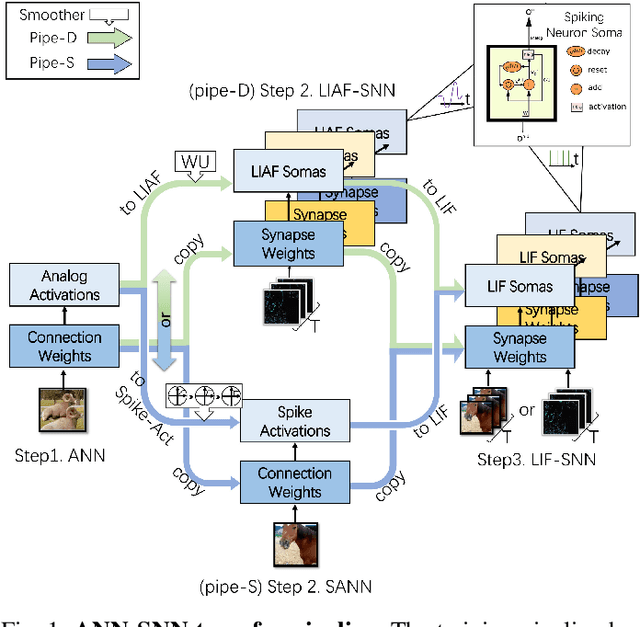
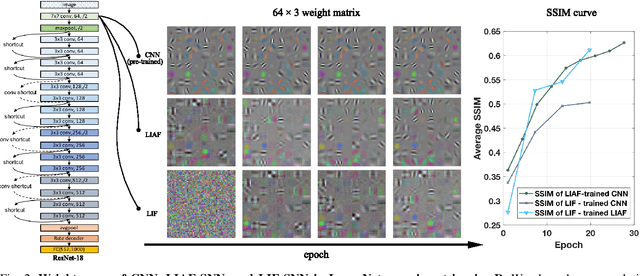
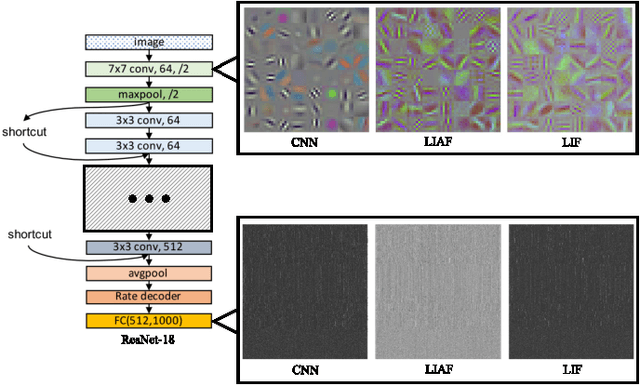
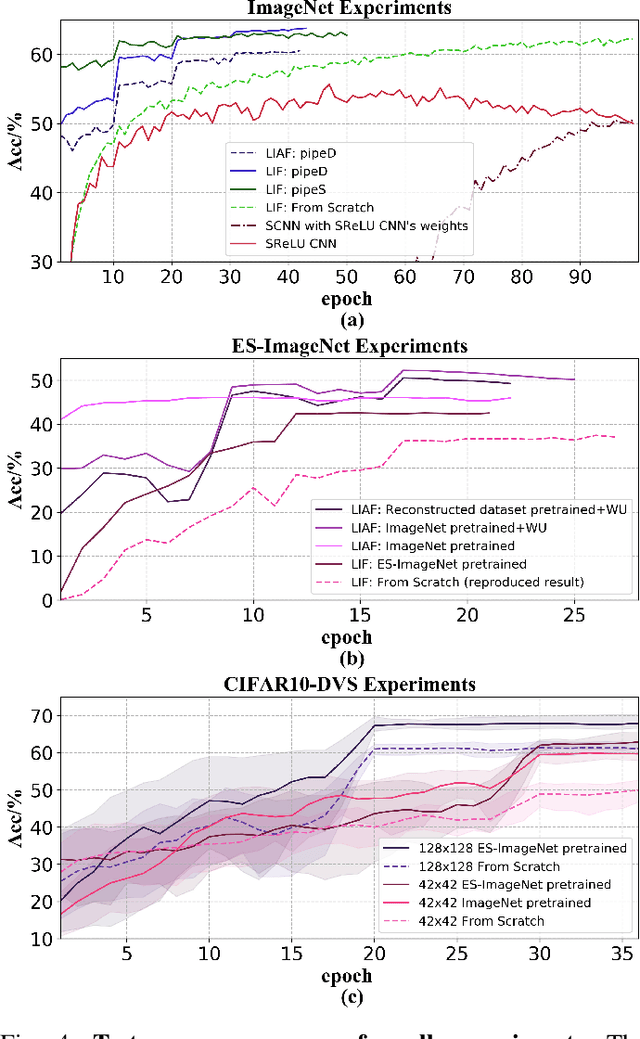
Spiking neural networks (SNNs) are known as a typical kind of brain-inspired models with their unique features of rich neuronal dynamics, diverse coding schemes and low power consumption properties. How to obtain a high-accuracy model has always been the main challenge in the field of SNN. Currently, there are two mainstream methods, i.e., obtaining a converted SNN through converting a well-trained Artificial Neural Network (ANN) to its SNN counterpart or training an SNN directly. However, the inference time of a converted SNN is too long, while SNN training is generally very costly and inefficient. In this work, a new SNN training paradigm is proposed by combining the concepts of the two different training methods with the help of the pretrain technique and BP-based deep SNN training mechanism. We believe that the proposed paradigm is a more efficient pipeline for training SNNs. The pipeline includes pipeS for static data transfer tasks and pipeD for dynamic data transfer tasks. SOTA results are obtained in a large-scale event-driven dataset ES-ImageNet. For training acceleration, we achieve the same (or higher) best accuracy as similar LIF-SNNs using 1/10 training time on ImageNet-1K and 2/5 training time on ES-ImageNet and also provide a time-accuracy benchmark for a new dataset ES-UCF101. These experimental results reveal the similarity of the functions of parameters between ANNs and SNNs and also demonstrate the various potential applications of this SNN training pipeline.
Survey on Graph Neural Network Acceleration: An Algorithmic Perspective
Feb 10, 2022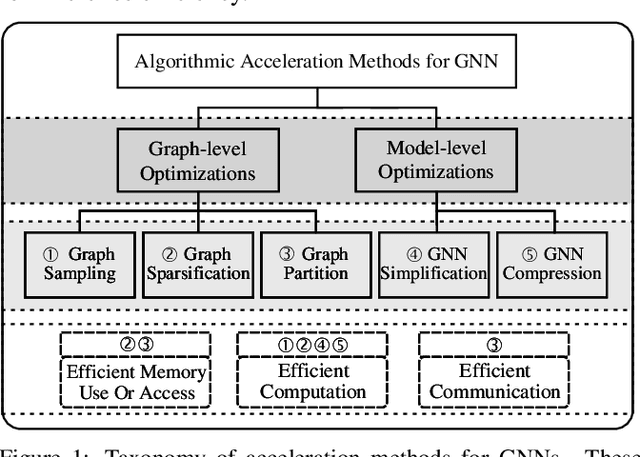
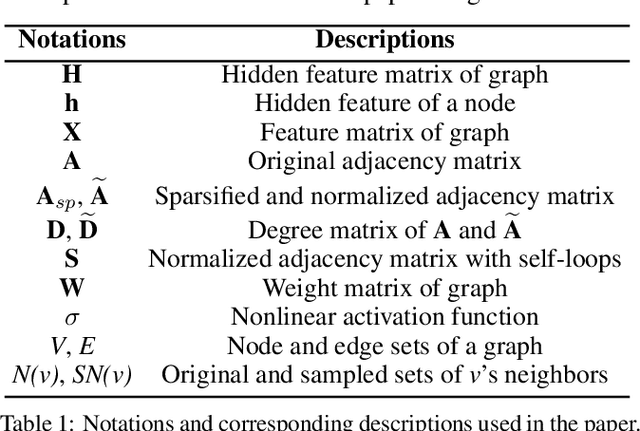
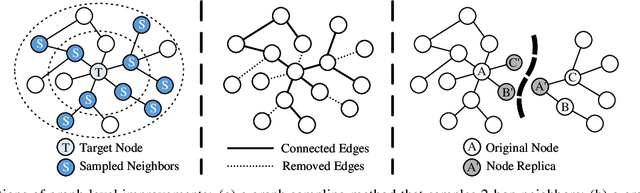

Graph neural networks (GNNs) have been a hot spot of recent research and are widely utilized in diverse applications. However, with the use of huger data and deeper models, an urgent demand is unsurprisingly made to accelerate GNNs for more efficient execution. In this paper, we provide a comprehensive survey on acceleration methods for GNNs from an algorithmic perspective. We first present a new taxonomy to classify existing acceleration methods into five categories. Based on the classification, we systematically discuss these methods and highlight their correlations. Next, we provide comparisons from aspects of the efficiency and characteristics of these methods. Finally, we suggest some promising prospects for future research.
Advancing Residual Learning towards Powerful Deep Spiking Neural Networks
Dec 23, 2021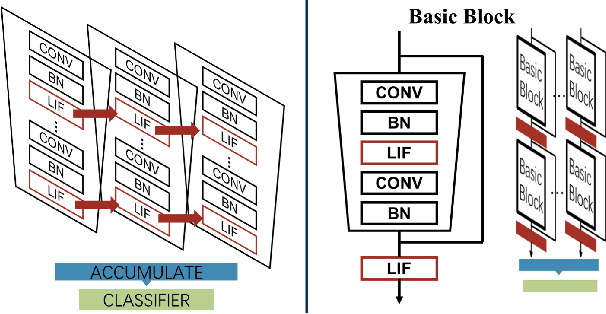

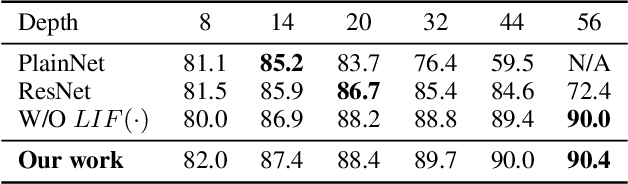
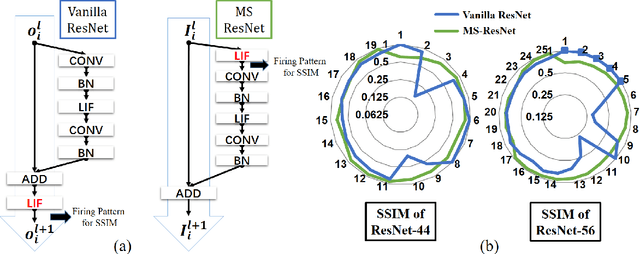
Despite the rapid progress of neuromorphic computing, inadequate capacity and insufficient representation power of spiking neural networks (SNNs) severely restrict their application scope in practice. Residual learning and shortcuts have been evidenced as an important approach for training deep neural networks, but rarely did previous work assess their applicability to the characteristics of spike-based communication and spatiotemporal dynamics. In this paper, we first identify that this negligence leads to impeded information flow and accompanying degradation problem in previous residual SNNs. Then we propose a novel SNN-oriented residual block, MS-ResNet, which is able to significantly extend the depth of directly trained SNNs, e.g. up to 482 layers on CIFAR-10 and 104 layers on ImageNet, without observing any slight degradation problem. We validate the effectiveness of MS-ResNet on both frame-based and neuromorphic datasets, and MS-ResNet104 achieves a superior result of 76.02% accuracy on ImageNet, the first time in the domain of directly trained SNNs. Great energy efficiency is also observed that on average only one spike per neuron is needed to classify an input sample. We believe our powerful and scalable models will provide a strong support for further exploration of SNNs.
ES-ImageNet: A Million Event-Stream Classification Dataset for Spiking Neural Networks
Oct 23, 2021
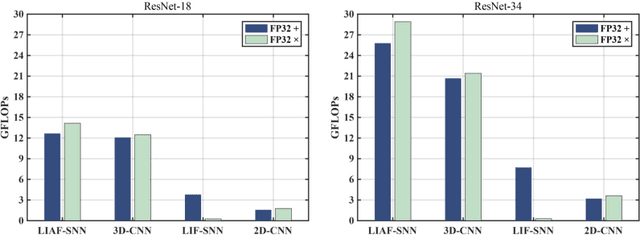
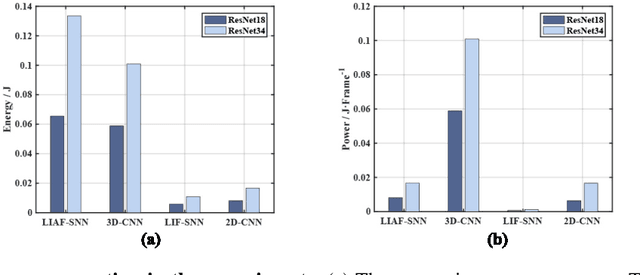
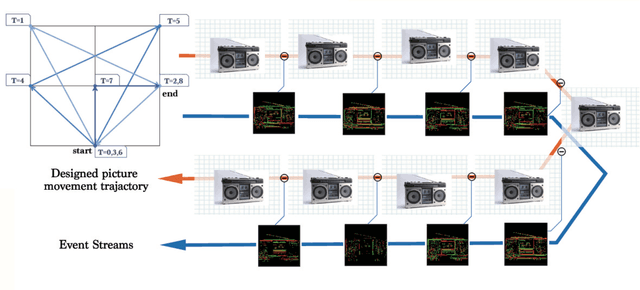
With event-driven algorithms, especially the spiking neural networks (SNNs), achieving continuous improvement in neuromorphic vision processing, a more challenging event-stream-dataset is urgently needed. However, it is well known that creating an ES-dataset is a time-consuming and costly task with neuromorphic cameras like dynamic vision sensors (DVS). In this work, we propose a fast and effective algorithm termed Omnidirectional Discrete Gradient (ODG) to convert the popular computer vision dataset ILSVRC2012 into its event-stream (ES) version, generating about 1,300,000 frame-based images into ES-samples in 1000 categories. In this way, we propose an ES-dataset called ES-ImageNet, which is dozens of times larger than other neuromorphic classification datasets at present and completely generated by the software. The ODG algorithm implements an image motion to generate local value changes with discrete gradient information in different directions, providing a low-cost and high-speed way for converting frame-based images into event streams, along with Edge-Integral to reconstruct the high-quality images from event streams. Furthermore, we analyze the statistics of the ES-ImageNet in multiple ways, and a performance benchmark of the dataset is also provided using both famous deep neural network algorithms and spiking neural network algorithms. We believe that this work shall provide a new large-scale benchmark dataset for SNNs and neuromorphic vision.
Efficient Visual Recognition with Deep Neural Networks: A Survey on Recent Advances and New Directions
Sep 09, 2021
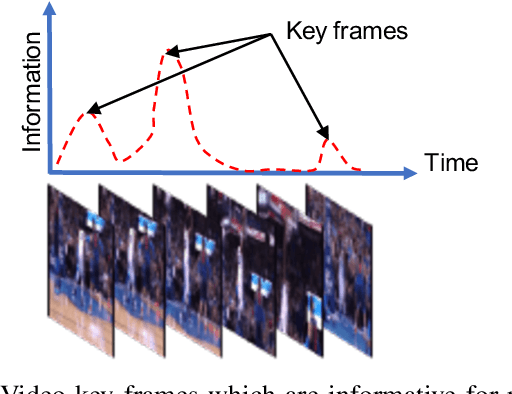
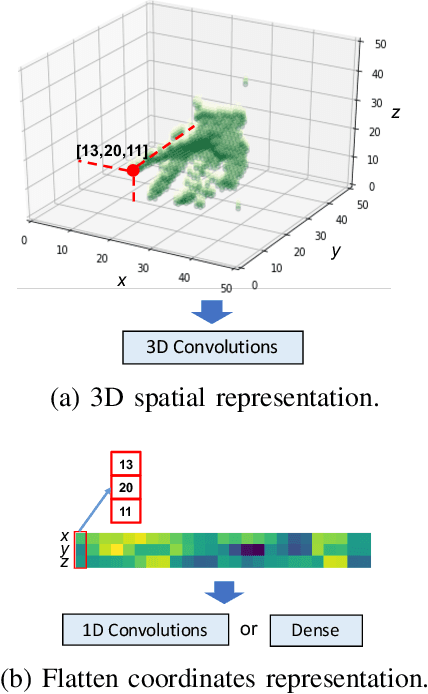
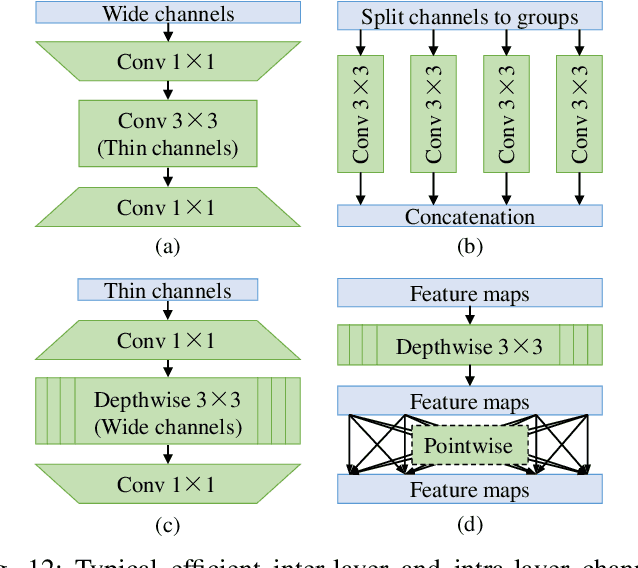
Visual recognition is currently one of the most important and active research areas in computer vision, pattern recognition, and even the general field of artificial intelligence. It has great fundamental importance and strong industrial needs. Deep neural networks (DNNs) have largely boosted their performances on many concrete tasks, with the help of large amounts of training data and new powerful computation resources. Though recognition accuracy is usually the first concern for new progresses, efficiency is actually rather important and sometimes critical for both academic research and industrial applications. Moreover, insightful views on the opportunities and challenges of efficiency are also highly required for the entire community. While general surveys on the efficiency issue of DNNs have been done from various perspectives, as far as we are aware, scarcely any of them focused on visual recognition systematically, and thus it is unclear which progresses are applicable to it and what else should be concerned. In this paper, we present the review of the recent advances with our suggestions on the new possible directions towards improving the efficiency of DNN-related visual recognition approaches. We investigate not only from the model but also the data point of view (which is not the case in existing surveys), and focus on three most studied data types (images, videos and points). This paper attempts to provide a systematic summary via a comprehensive survey which can serve as a valuable reference and inspire both researchers and practitioners who work on visual recognition problems.