 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint sparse coding and temporal dynamics support context reconfiguration
May 11, 2026Adaptive behavior requires the brain to transition between distinct contexts while maintaining representations of prior experience. The ability to reconfigure neural representations without erasing previously acquired knowledge is central to learning in dynamic environments, yet the neural mechanisms that support this balance remain unclear. Understanding these mechanisms is also critical for addressing catastrophic forgetting in artificial systems designed for lifelong learning. Here, we identify joint sparse coding and temporal dynamics in both the mouse medial prefrontal cortex (mPFC) and computational networks as mechanisms that help preserve prior representations during context transitions. Specifically, sparsity in context-dependent representations reduces cross-context interference, whereas temporal dynamics within the network activity further enhance context separability across time. Strikingly, networks endowed with both properties, such as spiking neural networks, exhibit improved retention during lifelong learning without auxiliary heuristics. These findings establish joint sparse coding and temporal dynamics as a core mechanism supporting flexible context reconfiguration in lifelong learning and, through their activity constraining nature, as an energy-efficient architectural principle for stable adaptation. Together, they provide a mechanistic framework for understanding how the brain preserves prior knowledge while flexibly adapting to new contexts.
Unveiling the Potential of Spiking Dynamics in Graph Representation Learning through Spatial-Temporal Normalization and Coding Strategies
Jul 30, 2024



In recent years, spiking neural networks (SNNs) have attracted substantial interest due to their potential to replicate the energy-efficient and event-driven processing of biological neurons. Despite this, the application of SNNs in graph representation learning, particularly for non-Euclidean data, remains underexplored, and the influence of spiking dynamics on graph learning is not yet fully understood. This work seeks to address these gaps by examining the unique properties and benefits of spiking dynamics in enhancing graph representation learning. We propose a spike-based graph neural network model that incorporates spiking dynamics, enhanced by a novel spatial-temporal feature normalization (STFN) technique, to improve training efficiency and model stability. Our detailed analysis explores the impact of rate coding and temporal coding on SNN performance, offering new insights into their advantages for deep graph networks and addressing challenges such as the oversmoothing problem. Experimental results demonstrate that our SNN models can achieve competitive performance with state-of-the-art graph neural networks (GNNs) while considerably reducing computational costs, highlighting the potential of SNNs for efficient neuromorphic computing applications in complex graph-based scenarios.
Exploiting Spiking Dynamics with Spatial-temporal Feature Normalization in Graph Learning
Jun 30, 2021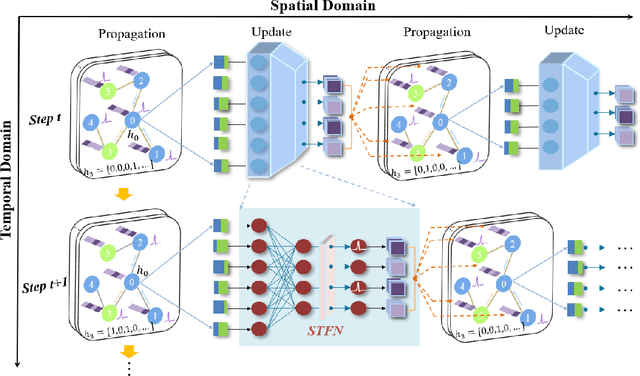
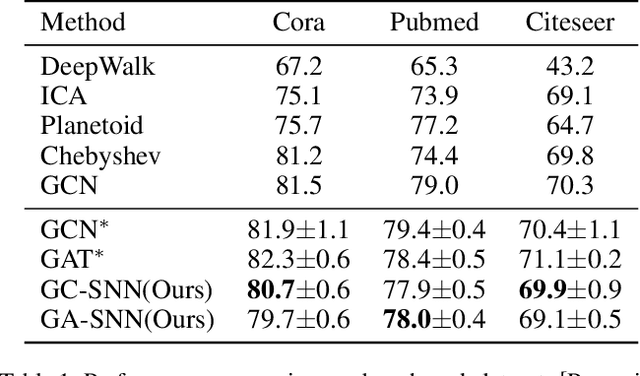
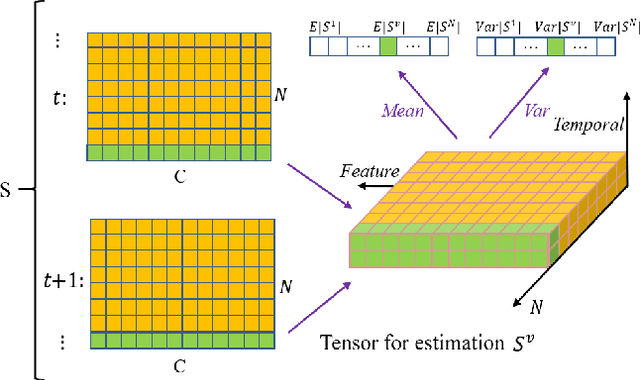
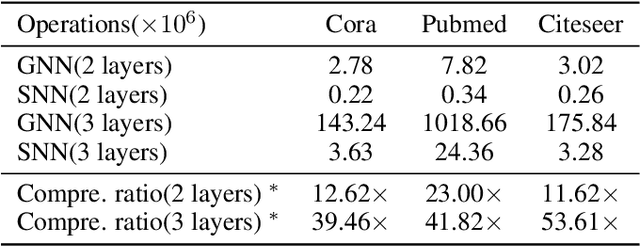
Biological spiking neurons with intrinsic dynamics underlie the powerful representation and learning capabilities of the brain for processing multimodal information in complex environments. Despite recent tremendous progress in spiking neural networks (SNNs) for handling Euclidean-space tasks, it still remains challenging to exploit SNNs in processing non-Euclidean-space data represented by graph data, mainly due to the lack of effective modeling framework and useful training techniques. Here we present a general spike-based modeling framework that enables the direct training of SNNs for graph learning. Through spatial-temporal unfolding for spiking data flows of node features, we incorporate graph convolution filters into spiking dynamics and formalize a synergistic learning paradigm. Considering the unique features of spike representation and spiking dynamics, we propose a spatial-temporal feature normalization (STFN) technique suitable for SNN to accelerate convergence. We instantiate our methods into two spiking graph models, including graph convolution SNNs and graph attention SNNs, and validate their performance on three node-classification benchmarks, including Cora, Citeseer, and Pubmed. Our model can achieve comparable performance with the state-of-the-art graph neural network (GNN) models with much lower computation costs, demonstrating great benefits for the execution on neuromorphic hardware and prompting neuromorphic applications in graphical scenarios.
Adversarial Feature Stacking for Accurate and Robust Predictions
Mar 24, 2021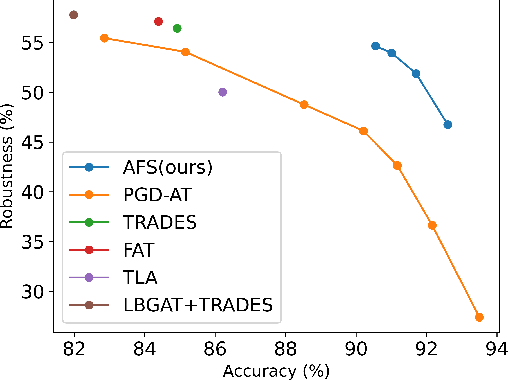
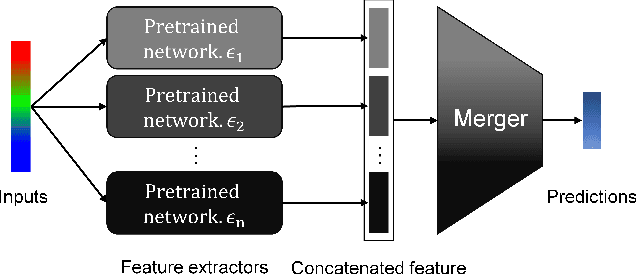
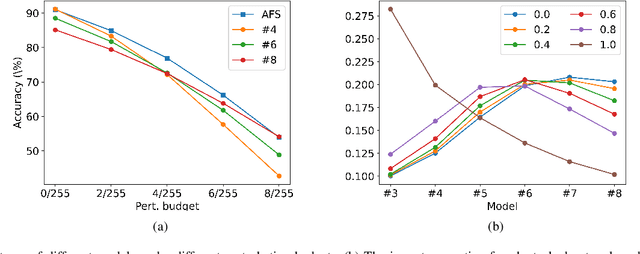
Deep Neural Networks (DNNs) have achieved remarkable performance on a variety of applications but are extremely vulnerable to adversarial perturbation. To address this issue, various defense methods have been proposed to enhance model robustness. Unfortunately, the most representative and promising methods, such as adversarial training and its variants, usually degrade model accuracy on benign samples, limiting practical utility. This indicates that it is difficult to extract both robust and accurate features using a single network under certain conditions, such as limited training data, resulting in a trade-off between accuracy and robustness. To tackle this problem, we propose an Adversarial Feature Stacking (AFS) model that can jointly take advantage of features with varied levels of robustness and accuracy, thus significantly alleviating the aforementioned trade-off. Specifically, we adopt multiple networks adversarially trained with different perturbation budgets to extract either more robust features or more accurate features. These features are then fused by a learnable merger to give final predictions. We evaluate the AFS model on CIFAR-10 and CIFAR-100 datasets with strong adaptive attack methods, which significantly advances the state-of-the-art in terms of the trade-off. Without extra training data, the AFS model achieves a benign accuracy improvement of 6% on CIFAR-10 and 9% on CIFAR-100 with comparable or even stronger robustness than the state-of-the-art adversarial training methods. This work demonstrates the feasibility to obtain both accurate and robust models under the circumstances of limited training data.
Adversarial symmetric GANs: bridging adversarial samples and adversarial networks
Jan 01, 2020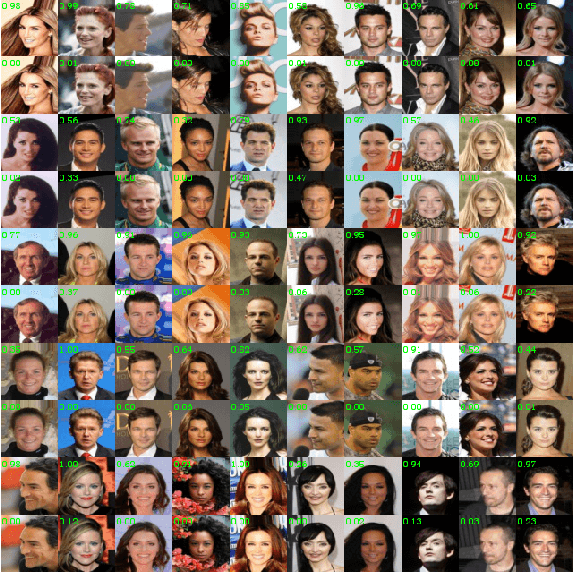
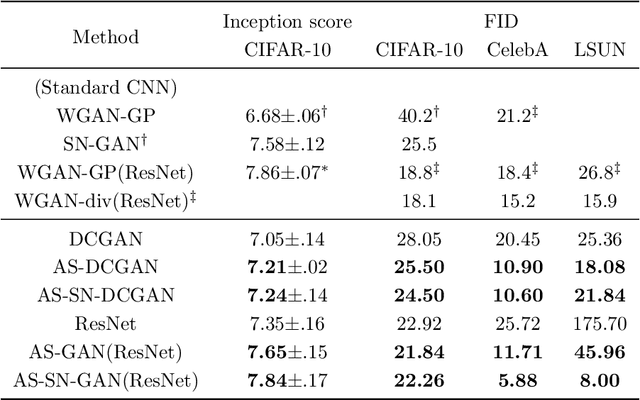


Generative adversarial networks have achieved remarkable performance on various tasks but suffer from training instability. Despite many training strategies proposed to improve training stability, this issue remains as a challenge. In this paper, we investigate the training instability from the perspective of adversarial samples and reveal that adversarial training on fake samples is implemented in vanilla GANs, but adversarial training on real samples has long been overlooked. Consequently, the discriminator is extremely vulnerable to adversarial perturbation and the gradient given by the discriminator contains non-informative adversarial noises, which hinders the generator from catching the pattern of real samples. Here, we develop adversarial symmetric GANs (AS-GANs) that incorporate adversarial training of the discriminator on real samples into vanilla GANs, making adversarial training symmetrical. The discriminator is therefore more robust and provides more informative gradient with less adversarial noise, thereby stabilizing training and accelerating convergence. The effectiveness of the AS-GANs is verified on image generation on CIFAR-10 , CelebA, and LSUN with varied network architectures. Not only the training is more stabilized, but the FID scores of generated samples are consistently improved by a large margin compared to the baseline. The bridging of adversarial samples and adversarial networks provides a new approach to further develop adversarial networks.