 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEventDiff: A Unified and Efficient Diffusion Model Framework for Event-based Video Frame Interpolation
May 13, 2025



Video Frame Interpolation (VFI) is a fundamental yet challenging task in computer vision, particularly under conditions involving large motion, occlusion, and lighting variation. Recent advancements in event cameras have opened up new opportunities for addressing these challenges. While existing event-based VFI methods have succeeded in recovering large and complex motions by leveraging handcrafted intermediate representations such as optical flow, these designs often compromise high-fidelity image reconstruction under subtle motion scenarios due to their reliance on explicit motion modeling. Meanwhile, diffusion models provide a promising alternative for VFI by reconstructing frames through a denoising process, eliminating the need for explicit motion estimation or warping operations. In this work, we propose EventDiff, a unified and efficient event-based diffusion model framework for VFI. EventDiff features a novel Event-Frame Hybrid AutoEncoder (HAE) equipped with a lightweight Spatial-Temporal Cross Attention (STCA) module that effectively fuses dynamic event streams with static frames. Unlike previous event-based VFI methods, EventDiff performs interpolation directly in the latent space via a denoising diffusion process, making it more robust across diverse and challenging VFI scenarios. Through a two-stage training strategy that first pretrains the HAE and then jointly optimizes it with the diffusion model, our method achieves state-of-the-art performance across multiple synthetic and real-world event VFI datasets. The proposed method outperforms existing state-of-the-art event-based VFI methods by up to 1.98dB in PSNR on Vimeo90K-Triplet and shows superior performance in SNU-FILM tasks with multiple difficulty levels. Compared to the emerging diffusion-based VFI approach, our method achieves up to 5.72dB PSNR gain on Vimeo90K-Triplet and 4.24X faster inference.
Understanding the Functional Roles of Modelling Components in Spiking Neural Networks
Mar 25, 2024Spiking neural networks (SNNs), inspired by the neural circuits of the brain, are promising in achieving high computational efficiency with biological fidelity. Nevertheless, it is quite difficult to optimize SNNs because the functional roles of their modelling components remain unclear. By designing and evaluating several variants of the classic model, we systematically investigate the functional roles of key modelling components, leakage, reset, and recurrence, in leaky integrate-and-fire (LIF) based SNNs. Through extensive experiments, we demonstrate how these components influence the accuracy, generalization, and robustness of SNNs. Specifically, we find that the leakage plays a crucial role in balancing memory retention and robustness, the reset mechanism is essential for uninterrupted temporal processing and computational efficiency, and the recurrence enriches the capability to model complex dynamics at a cost of robustness degradation. With these interesting observations, we provide optimization suggestions for enhancing the performance of SNNs in different scenarios. This work deepens the understanding of how SNNs work, which offers valuable guidance for the development of more effective and robust neuromorphic models.
Going Deeper With Directly-Trained Larger Spiking Neural Networks
Oct 29, 2020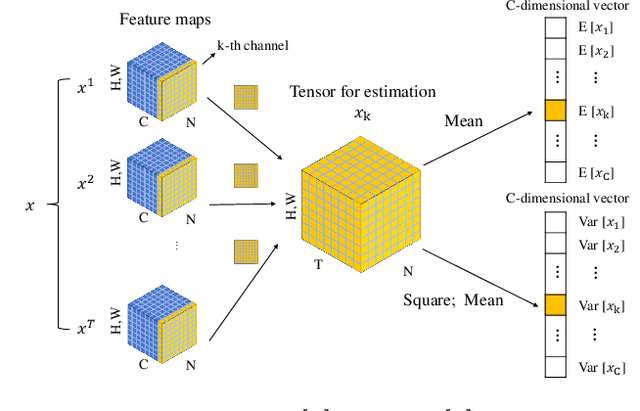
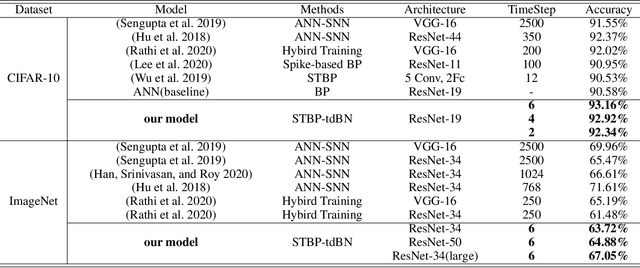
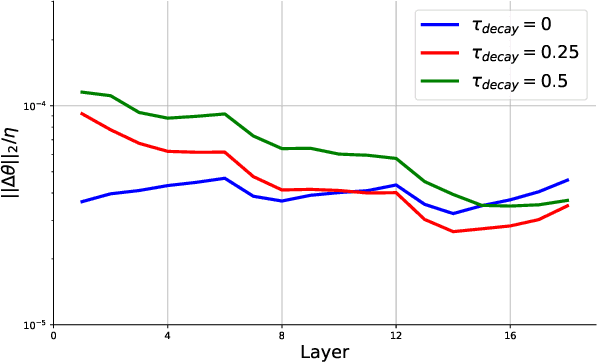
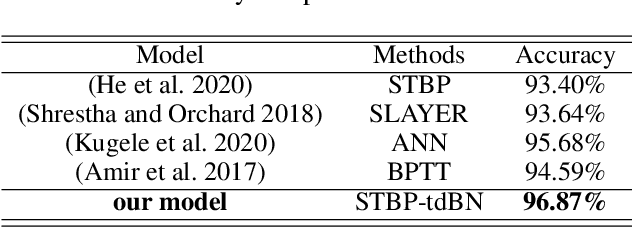
Spiking neural networks (SNNs) are promising in a bio-plausible coding for spatio-temporal information and event-driven signal processing, which is very suited for energy-efficient implementation in neuromorphic hardware. However, the unique working mode of SNNs makes them more difficult to train than traditional networks. Currently, there are two main routes to explore the training of deep SNNs with high performance. The first is to convert a pre-trained ANN model to its SNN version, which usually requires a long coding window for convergence and cannot exploit the spatio-temporal features during training for solving temporal tasks. The other is to directly train SNNs in the spatio-temporal domain. But due to the binary spike activity of the firing function and the problem of gradient vanishing or explosion, current methods are restricted to shallow architectures and thereby difficult in harnessing large-scale datasets (e.g. ImageNet). To this end, we propose a threshold-dependent batch normalization (tdBN) method based on the emerging spatio-temporal backpropagation, termed "STBP-tdBN", enabling direct training of a very deep SNN and the efficient implementation of its inference on neuromorphic hardware. With the proposed method and elaborated shortcut connection, we significantly extend directly-trained SNNs from a shallow structure ( < 10 layer) to a very deep structure (50 layers). Furthermore, we theoretically analyze the effectiveness of our method based on "Block Dynamical Isometry" theory. Finally, we report superior accuracy results including 93.15 % on CIFAR-10, 67.8 % on DVS-CIFAR10, and 67.05% on ImageNet with very few timesteps. To our best knowledge, it's the first time to explore the directly-trained deep SNNs with high performance on ImageNet.