 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Structured Knowledge in Text via Graph-Guided Representation Learning
Apr 29, 2020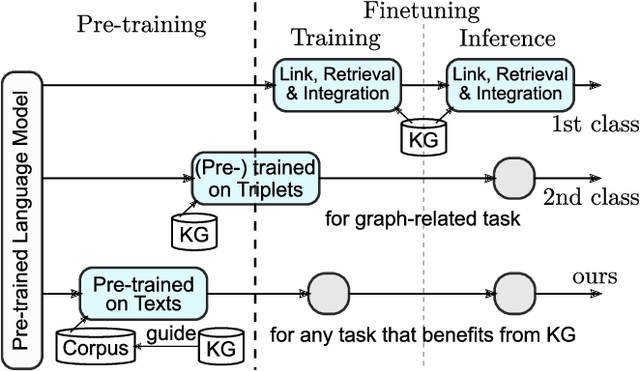
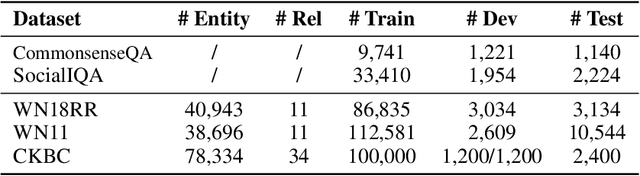
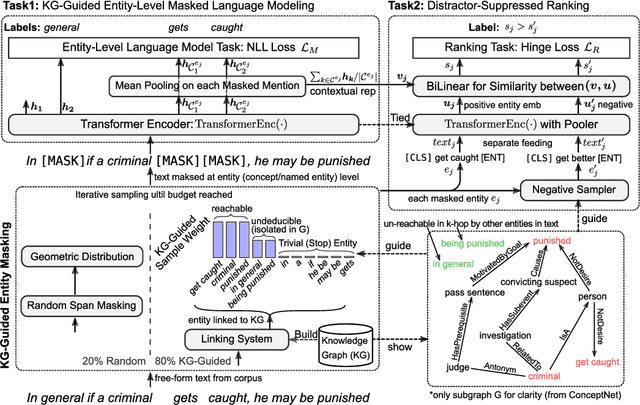
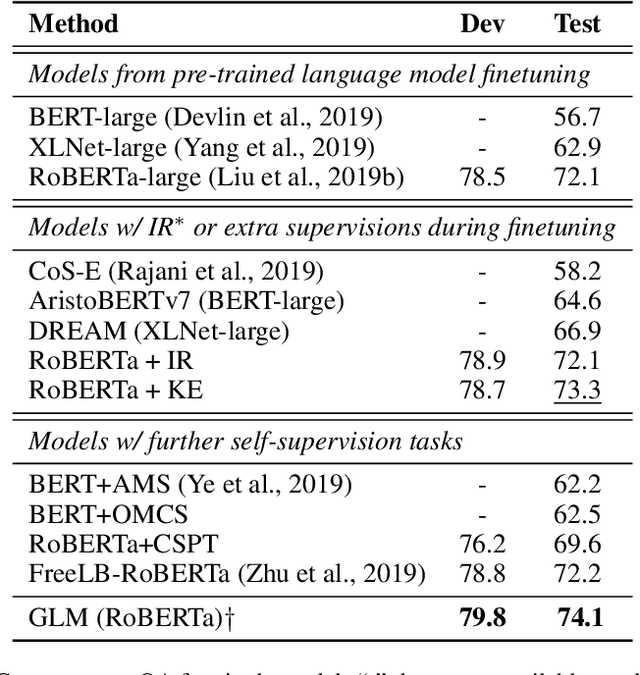
In this work, we aim at equipping pre-trained language models with structured knowledge. We present two self-supervised tasks learning over raw text with the guidance from knowledge graphs. Building upon entity-level masked language models, our first contribution is an entity masking scheme that exploits relational knowledge underlying the text. This is fulfilled by using a linked knowledge graph to select informative entities and then masking their mentions. In addition we use knowledge graphs to obtain distractors for the masked entities, and propose a novel distractor-suppressed ranking objective which is optimized jointly with masked language model. In contrast to existing paradigms, our approach uses knowledge graphs implicitly, only during pre-training, to inject language models with structured knowledge via learning from raw text. It is more efficient than retrieval-based methods that perform entity linking and integration during finetuning and inference, and generalizes more effectively than the methods that directly learn from concatenated graph triples. Experiments show that our proposed model achieves improved performance on five benchmark datasets, including question answering and knowledge base completion tasks.
Rethinking 1D-CNN for Time Series Classification: A Stronger Baseline
Feb 24, 2020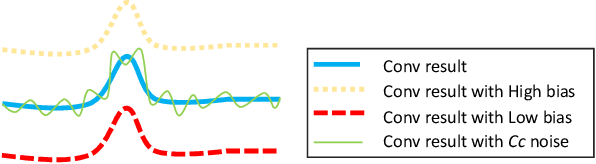
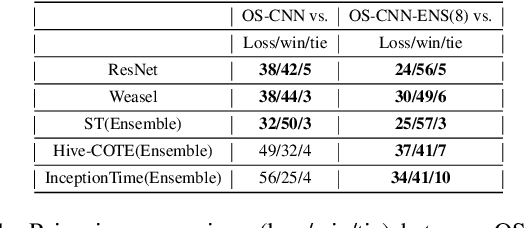
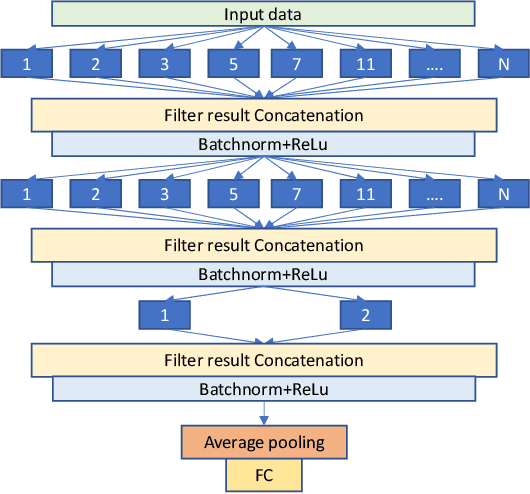
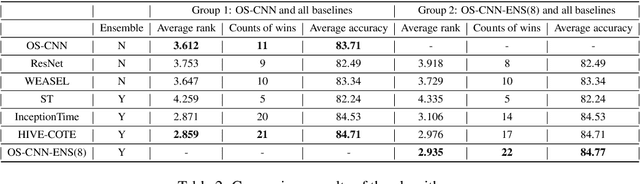
For time series classification task using 1D-CNN, the selection of kernel size is critically important to ensure the model can capture the right scale salient signal from a long time-series. Most of the existing work on 1D-CNN treats the kernel size as a hyper-parameter and tries to find the proper kernel size through a grid search which is time-consuming and is inefficient. This paper theoretically analyses how kernel size impacts the performance of 1D-CNN. Considering the importance of kernel size, we propose a novel Omni-Scale 1D-CNN (OS-CNN) architecture to capture the proper kernel size during the model learning period. A specific design for kernel size configuration is developed which enables us to assemble very few kernel-size options to represent more receptive fields. The proposed OS-CNN method is evaluated using the UCR archive with 85 datasets. The experiment results demonstrate that our method is a stronger baseline in multiple performance indicators, including the critical difference diagram, counts of wins, and average accuracy. We also published the experimental source codes at GitHub (https://github.com/Wensi-Tang/OS-CNN/).
Self-Attention Enhanced Selective Gate with Entity-Aware Embedding for Distantly Supervised Relation Extraction
Nov 27, 2019
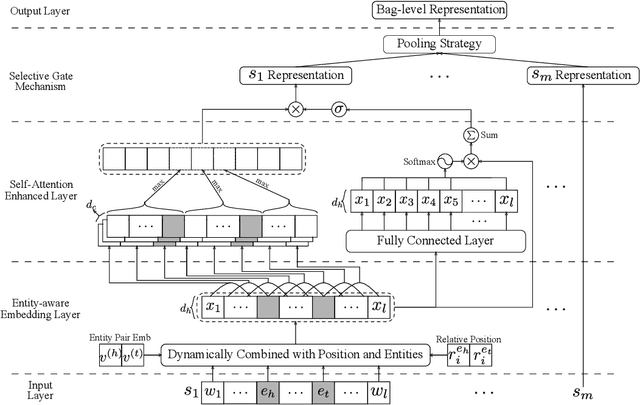
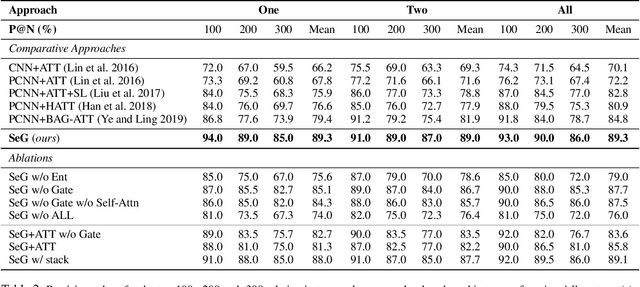
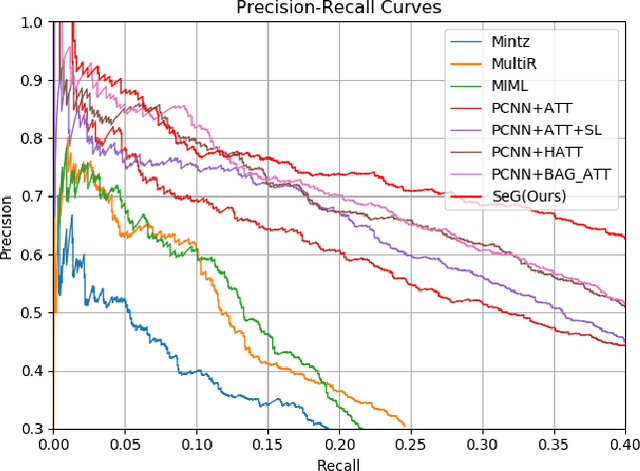
Distantly supervised relation extraction intrinsically suffers from noisy labels due to the strong assumption of distant supervision. Most prior works adopt a selective attention mechanism over sentences in a bag to denoise from wrongly labeled data, which however could be incompetent when there is only one sentence in a bag. In this paper, we propose a brand-new light-weight neural framework to address the distantly supervised relation extraction problem and alleviate the defects in previous selective attention framework. Specifically, in the proposed framework, 1) we use an entity-aware word embedding method to integrate both relative position information and head/tail entity embeddings, aiming to highlight the essence of entities for this task; 2) we develop a self-attention mechanism to capture the rich contextual dependencies as a complement for local dependencies captured by piecewise CNN; and 3) instead of using selective attention, we design a pooling-equipped gate, which is based on rich contextual representations, as an aggregator to generate bag-level representation for final relation classification. Compared to selective attention, one major advantage of the proposed gating mechanism is that, it performs stably and promisingly even if only one sentence appears in a bag and thus keeps the consistency across all training examples. The experiments on NYT dataset demonstrate that our approach achieves a new state-of-the-art performance in terms of both AUC and top-n precision metrics.
Suicidal Ideation Detection: A Review of Machine Learning Methods and Applications
Oct 23, 2019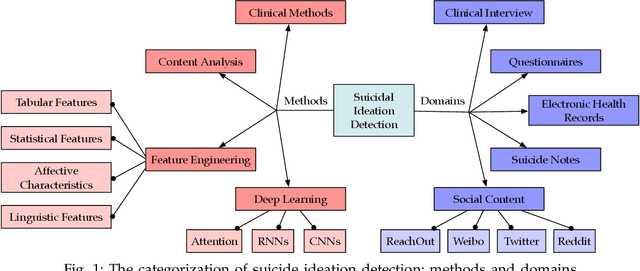
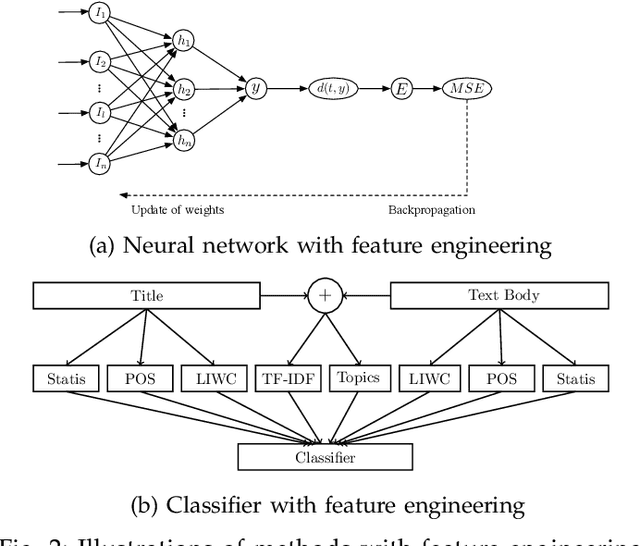
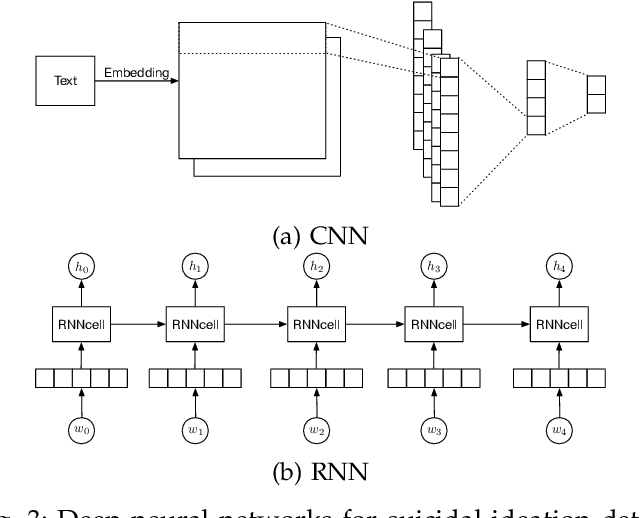

Suicide is a critical issue in the modern society. Early detection and prevention of suicide attempt should be addressed to save people's life. Current suicidal ideation detection methods include clinical methods based on the interaction between social workers or experts and the targeted individuals, and machine learning techniques with feature engineering or deep learning for automatic detection based on online social contents. This is the first survey that comprehensively introduces and discusses the methods from these categories. Domain-specific applications of suicidal ideation detection are also reviewed according to their data sources, i.e., questionnaires, electronic health records, suicide notes, and online user content. To facilitate further research, several specific tasks and datasets are introduced. Finally, we summarize the limitations of current work and provide an outlook of further research directions.
Multi-Task Learning for Conversational Question Answering over a Large-Scale Knowledge Base
Oct 11, 2019
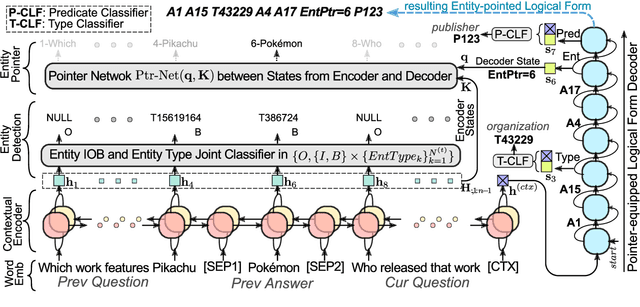
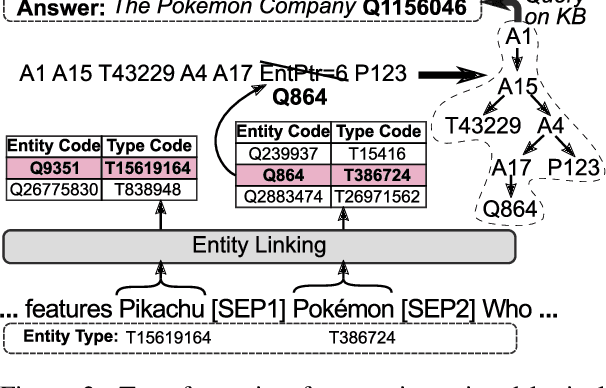
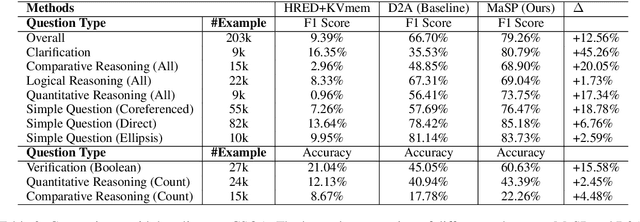
We consider the problem of conversational question answering over a large-scale knowledge base. To handle huge entity vocabulary of a large-scale knowledge base, recent neural semantic parsing based approaches usually decompose the task into several subtasks and then solve them sequentially, which leads to following issues: 1) errors in earlier subtasks will be propagated and negatively affect downstream ones; and 2) each subtask cannot naturally share supervision signals with others. To tackle these issues, we propose an innovative multi-task learning framework where a pointer-equipped semantic parsing model is designed to resolve coreference in conversations, and naturally empower joint learning with a novel type-aware entity detection model. The proposed framework thus enables shared supervisions and alleviates the effect of error propagation. Experiments on a large-scale conversational question answering dataset containing 1.6M question answering pairs over 12.8M entities show that the proposed framework improves overall F1 score from 67% to 79% compared with previous state-of-the-art work.
Temporal Self-Attention Network for Medical Concept Embedding
Sep 15, 2019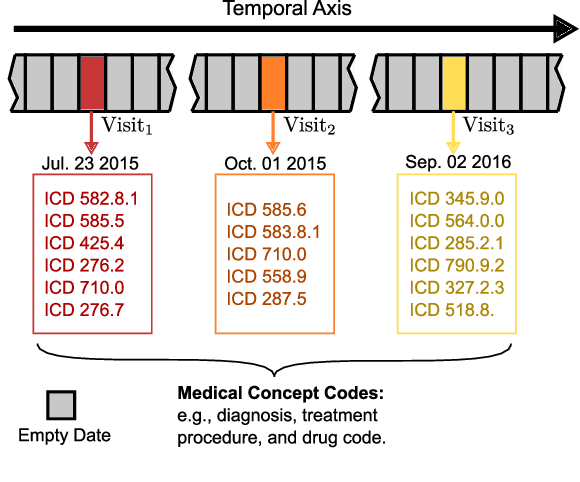
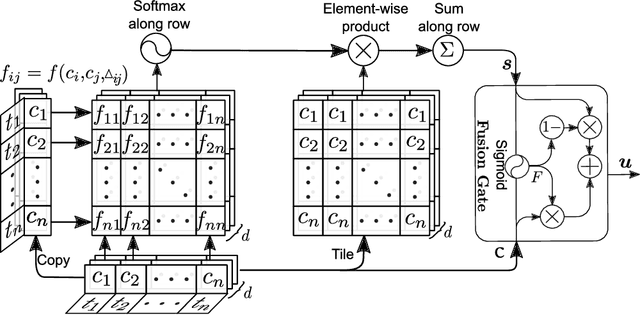
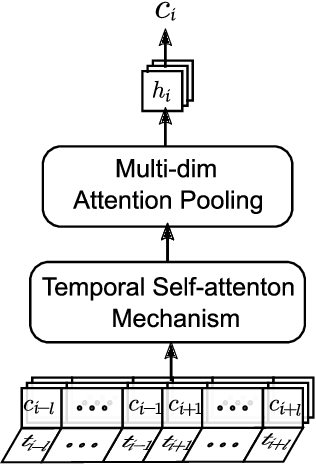

In longitudinal electronic health records (EHRs), the event records of a patient are distributed over a long period of time and the temporal relations between the events reflect sufficient domain knowledge to benefit prediction tasks such as the rate of inpatient mortality. Medical concept embedding as a feature extraction method that transforms a set of medical concepts with a specific time stamp into a vector, which will be fed into a supervised learning algorithm. The quality of the embedding significantly determines the learning performance over the medical data. In this paper, we propose a medical concept embedding method based on applying a self-attention mechanism to represent each medical concept. We propose a novel attention mechanism which captures the contextual information and temporal relationships between medical concepts. A light-weight neural net, "Temporal Self-Attention Network (TeSAN)", is then proposed to learn medical concept embedding based solely on the proposed attention mechanism. To test the effectiveness of our proposed methods, we have conducted clustering and prediction tasks on two public EHRs datasets comparing TeSAN against five state-of-the-art embedding methods. The experimental results demonstrate that the proposed TeSAN model is superior to all the compared methods. To the best of our knowledge, this work is the first to exploit temporal self-attentive relations between medical events.
Learning to Propagate for Graph Meta-Learning
Sep 11, 2019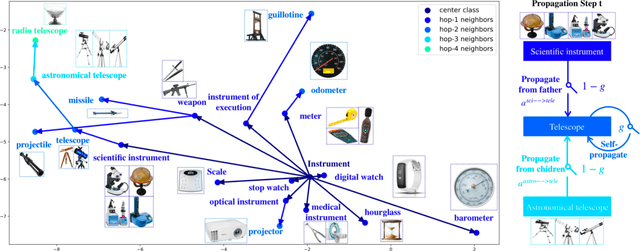

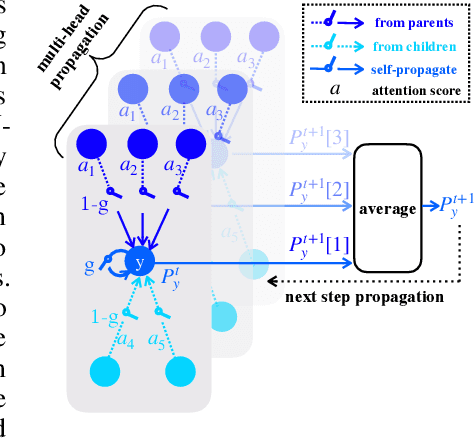

Meta-learning extracts the common knowledge acquired from learning different tasks and uses it for unseen tasks. It demonstrates a clear advantage on tasks that have insufficient training data, e.g., few-shot learning. In most meta-learning methods, tasks are implicitly related via the shared model or optimizer. In this paper, we show that a meta-learner that explicitly relates tasks on a graph describing the relations of their output dimensions (e.g., classes) can significantly improve the performance of few-shot learning. This type of graph is usually free or cheap to obtain but has rarely been explored in previous works. We study the prototype based few-shot classification, in which a prototype is generated for each class, such that the nearest neighbor search between the prototypes produces an accurate classification. We introduce "Gated Propagation Network (GPN)", which learns to propagate messages between prototypes of different classes on the graph, so that learning the prototype of each class benefits from the data of other related classes. In GPN, an attention mechanism is used for the aggregation of messages from neighboring classes, and a gate is deployed to choose between the aggregated messages and the message from the class itself. GPN is trained on a sequence of tasks from many-shot to few-shot generated by subgraph sampling. During training, it is able to reuse and update previously achieved prototypes from the memory in a life-long learning cycle. In experiments, we change the training-test discrepancy and test task generation settings for thorough evaluations. GPN outperforms recent meta-learning methods on two benchmark datasets in all studied cases.
Effective Search of Logical Forms for Weakly Supervised Knowledge-Based Question Answering
Sep 06, 2019
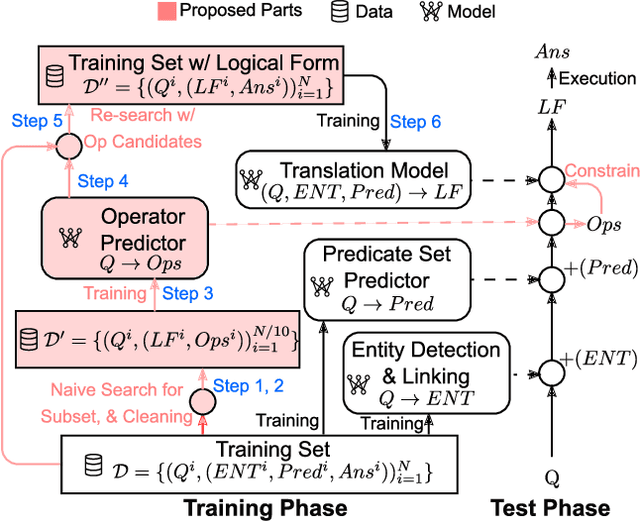
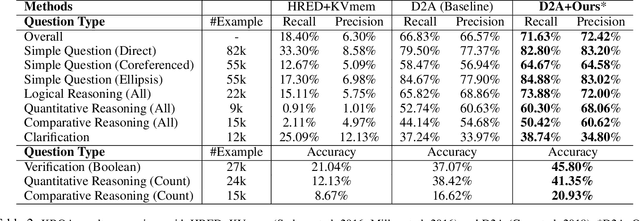
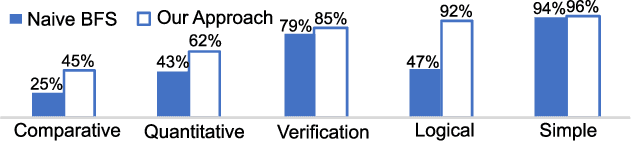
Many algorithms for Knowledge-Based Question Answering (KBQA) depend on semantic parsing, which translates a question to its logical form. When only weak supervision is provided, it is usually necessary to search valid logical forms for model training. However, a complex question typically involves a huge search space, which creates two main problems: 1) the solutions limited by computation time and memory usually reduce the success rate of the search, and 2) spurious logical forms in the search results degrade the quality of training data. These two problems lead to a poorly-trained semantic parsing model. In this work, we propose an effective search method for weakly supervised KBQA based on operator prediction for questions. With search space constrained by predicted operators, sufficient search paths can be explored, more valid logical forms can be derived, and operators possibly causing spurious logical forms can be avoided. As a result, a larger proportion of questions in a weakly supervised training set are equipped with logical forms, and fewer spurious logical forms are generated. Such high-quality training data directly contributes to a better semantic parsing model. Experimental results on one of the largest KBQA datasets (i.e., CSQA) verify the effectiveness of our approach: improving the precision from 67% to 72% and the recall from 67% to 72% in terms of the overall score.
Attributed Graph Clustering: A Deep Attentional Embedding Approach
Jun 15, 2019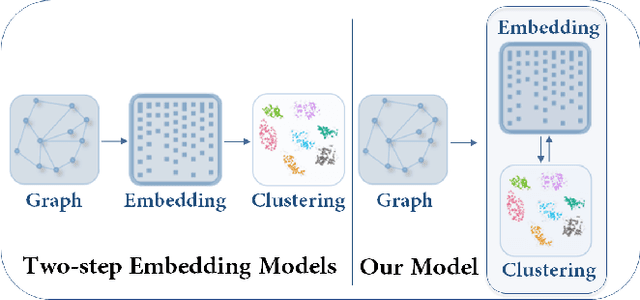
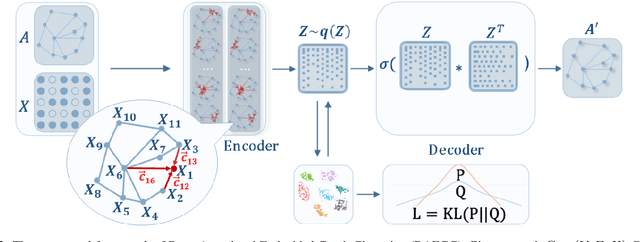
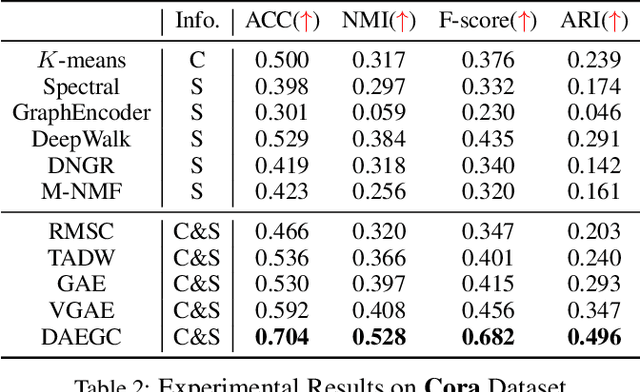
Graph clustering is a fundamental task which discovers communities or groups in networks. Recent studies have mostly focused on developing deep learning approaches to learn a compact graph embedding, upon which classic clustering methods like k-means or spectral clustering algorithms are applied. These two-step frameworks are difficult to manipulate and usually lead to suboptimal performance, mainly because the graph embedding is not goal-directed, i.e., designed for the specific clustering task. In this paper, we propose a goal-directed deep learning approach, Deep Attentional Embedded Graph Clustering (DAEGC for short). Our method focuses on attributed graphs to sufficiently explore the two sides of information in graphs. By employing an attention network to capture the importance of the neighboring nodes to a target node, our DAEGC algorithm encodes the topological structure and node content in a graph to a compact representation, on which an inner product decoder is trained to reconstruct the graph structure. Furthermore, soft labels from the graph embedding itself are generated to supervise a self-training graph clustering process, which iteratively refines the clustering results. The self-training process is jointly learned and optimized with the graph embedding in a unified framework, to mutually benefit both components. Experimental results compared with state-of-the-art algorithms demonstrate the superiority of our method.
Prototype Propagation Networks (PPN) for Weakly-supervised Few-shot Learning on Category Graph
Jun 02, 2019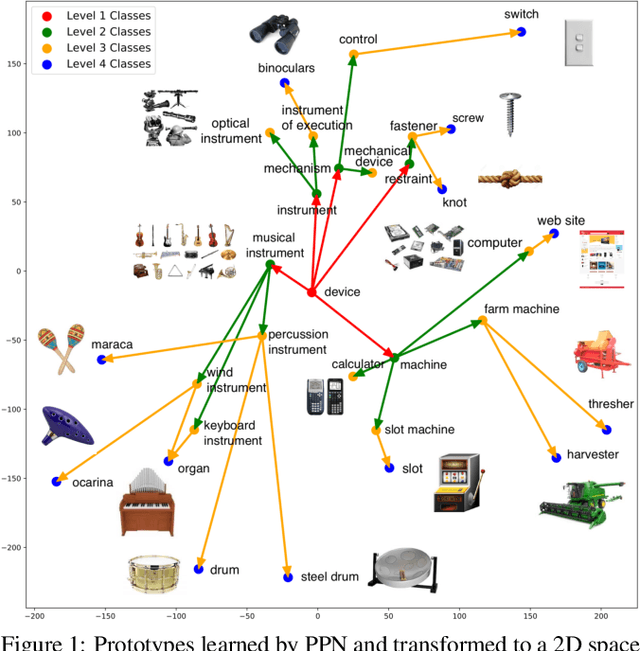
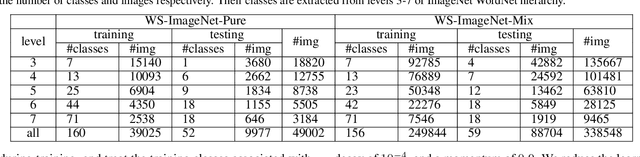

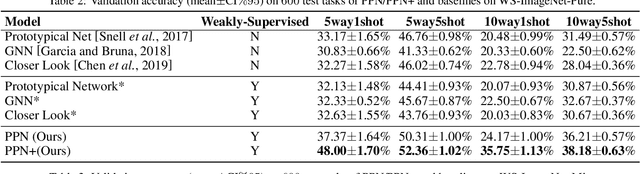
A variety of machine learning applications expect to achieve rapid learning from a limited number of labeled data. However, the success of most current models is the result of heavy training on big data. Meta-learning addresses this problem by extracting common knowledge across different tasks that can be quickly adapted to new tasks. However, they do not fully explore weakly-supervised information, which is usually free or cheap to collect. In this paper, we show that weakly-labeled data can significantly improve the performance of meta-learning on few-shot classification. We propose prototype propagation network (PPN) trained on few-shot tasks together with data annotated by coarse-label. Given a category graph of the targeted fine-classes and some weakly-labeled coarse-classes, PPN learns an attention mechanism which propagates the prototype of one class to another on the graph, so that the K-nearest neighbor (KNN) classifier defined on the propagated prototypes results in high accuracy across different few-shot tasks. The training tasks are generated by subgraph sampling, and the training objective is obtained by accumulating the level-wise classification loss on the subgraph. The resulting graph of prototypes can be continually re-used and updated for new tasks and classes. We also introduce two practical test/inference settings which differ according to whether the test task can leverage any weakly-supervised information as in training. On two benchmarks, PPN significantly outperforms most recent few-shot learning methods in different settings, even when they are also allowed to train on weakly-labeled data.