 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEAGG: Embodiment-Aligned Grasp Generation via Geometry-Aware Graph Conditioning
Jun 16, 2026Cross-end-effector grasp generation seeks a unified model that generalizes across objects and across embodiments ranging from parallel grippers to dexterous end effectors. Existing grasp generators are typically designed for a fixed embodiment or encode embodiment identity with a static descriptor, which weakens transfer when topology, actuation coupling, and contact geometry differ substantially. We present EAGG, an embodiment-aligned grasp generator that represents each embodiment with a topology-aware end-effector graph and an embodiment-specific low-dimensional end-effector control space. A frozen end-effector-cognition backbone converts the current articulated state into geometry-aware tokens that act as a reusable morphology prior, and iterative geometry injection refreshes these tokens throughout sampling so that conditioning remains synchronized with the evolving end-effector geometry. On the MultiGripperGrasp benchmark, EAGG reaches 56.17% average success across six training end effectors, remaining within 1.10 percentage points of specialized training while preserving transfer to finetuning and zero-shot end effectors. Iterative geometry injection further reduces the pooled median contact distance from 0.239 cm to 0.189 cm. These results show that cross-end-effector grasp generation is strengthened by aligning embodiment structure inside a shared generator rather than suppressing embodiment differences. Code is available at https://github.com/wanhaoniu/EAGG.
LightAgent: Production-level Open-source Agentic AI Framework
Sep 11, 2025With the rapid advancement of large language models (LLMs), Multi-agent Systems (MAS) have achieved significant progress in various application scenarios. However, substantial challenges remain in designing versatile, robust, and efficient platforms for agent deployment. To address these limitations, we propose \textbf{LightAgent}, a lightweight yet powerful agentic framework, effectively resolving the trade-off between flexibility and simplicity found in existing frameworks. LightAgent integrates core functionalities such as Memory (mem0), Tools, and Tree of Thought (ToT), while maintaining an extremely lightweight structure. As a fully open-source solution, it seamlessly integrates with mainstream chat platforms, enabling developers to easily build self-learning agents. We have released LightAgent at \href{https://github.com/wxai-space/LightAgent}{https://github.com/wxai-space/LightAgent}
FinGAIA: An End-to-End Benchmark for Evaluating AI Agents in Finance
Jul 23, 2025



The booming development of AI agents presents unprecedented opportunities for automating complex tasks across various domains. However, their multi-step, multi-tool collaboration capabilities in the financial sector remain underexplored. This paper introduces FinGAIA, an end-to-end benchmark designed to evaluate the practical abilities of AI agents in the financial domain. FinGAIA comprises 407 meticulously crafted tasks, spanning seven major financial sub-domains: securities, funds, banking, insurance, futures, trusts, and asset management. These tasks are organized into three hierarchical levels of scenario depth: basic business analysis, asset decision support, and strategic risk management. We evaluated 10 mainstream AI agents in a zero-shot setting. The best-performing agent, ChatGPT, achieved an overall accuracy of 48.9\%, which, while superior to non-professionals, still lags financial experts by over 35 percentage points. Error analysis has revealed five recurring failure patterns: Cross-modal Alignment Deficiency, Financial Terminological Bias, Operational Process Awareness Barrier, among others. These patterns point to crucial directions for future research. Our work provides the first agent benchmark closely related to the financial domain, aiming to objectively assess and promote the development of agents in this crucial field. Partial data is available at https://github.com/SUFE-AIFLM-Lab/FinGAIA.
Attributed Graph Clustering: A Deep Attentional Embedding Approach
Jun 15, 2019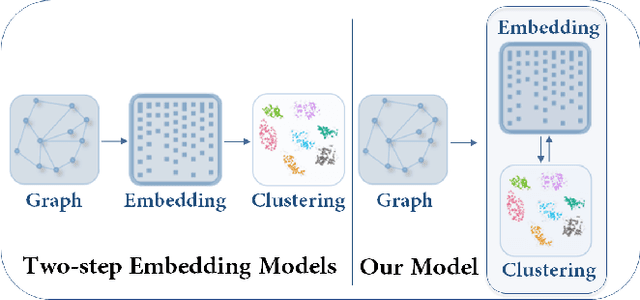
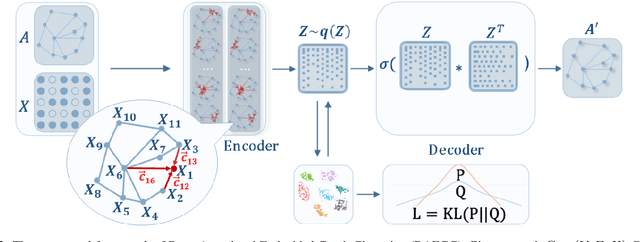
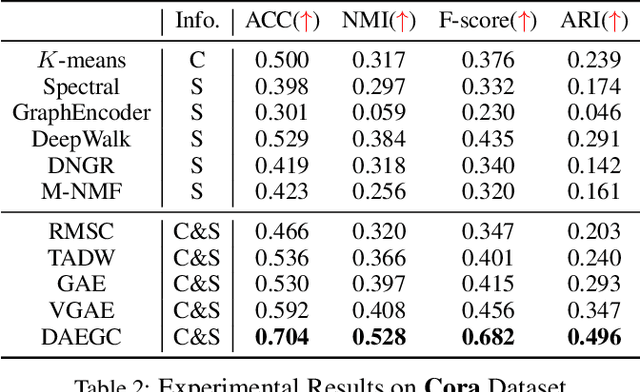
Graph clustering is a fundamental task which discovers communities or groups in networks. Recent studies have mostly focused on developing deep learning approaches to learn a compact graph embedding, upon which classic clustering methods like k-means or spectral clustering algorithms are applied. These two-step frameworks are difficult to manipulate and usually lead to suboptimal performance, mainly because the graph embedding is not goal-directed, i.e., designed for the specific clustering task. In this paper, we propose a goal-directed deep learning approach, Deep Attentional Embedded Graph Clustering (DAEGC for short). Our method focuses on attributed graphs to sufficiently explore the two sides of information in graphs. By employing an attention network to capture the importance of the neighboring nodes to a target node, our DAEGC algorithm encodes the topological structure and node content in a graph to a compact representation, on which an inner product decoder is trained to reconstruct the graph structure. Furthermore, soft labels from the graph embedding itself are generated to supervise a self-training graph clustering process, which iteratively refines the clustering results. The self-training process is jointly learned and optimized with the graph embedding in a unified framework, to mutually benefit both components. Experimental results compared with state-of-the-art algorithms demonstrate the superiority of our method.
Learning Graph Embedding with Adversarial Training Methods
Jan 04, 2019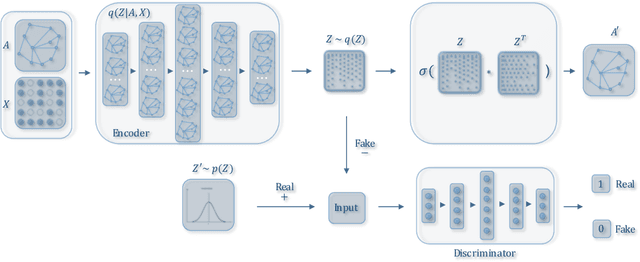
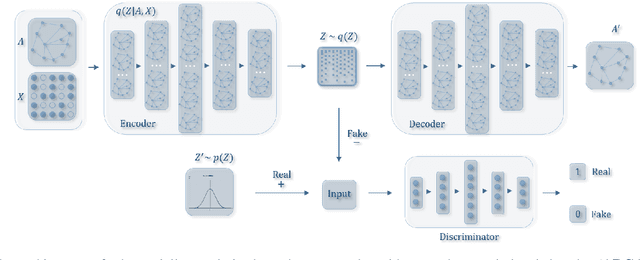
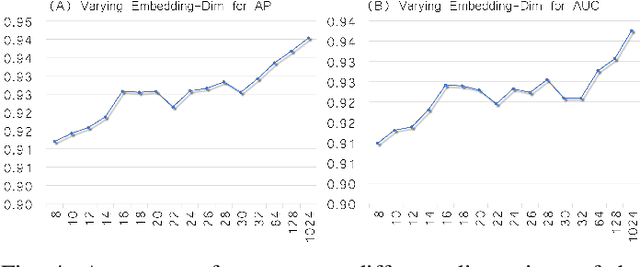
Graph embedding aims to transfer a graph into vectors to facilitate subsequent graph analytics tasks like link prediction and graph clustering. Most approaches on graph embedding focus on preserving the graph structure or minimizing the reconstruction errors for graph data. They have mostly overlooked the embedding distribution of the latent codes, which unfortunately may lead to inferior representation in many cases. In this paper, we present a novel adversarially regularized framework for graph embedding. By employing the graph convolutional network as an encoder, our framework embeds the topological information and node content into a vector representation, from which a graph decoder is further built to reconstruct the input graph. The adversarial training principle is applied to enforce our latent codes to match a prior Gaussian or Uniform distribution. Based on this framework, we derive two variants of adversarial models, the adversarially regularized graph autoencoder (ARGA) and its variational version, adversarially regularized variational graph autoencoder (ARVGA), to learn the graph embedding effectively. We also exploit other potential variations of ARGA and ARVGA to get a deeper understanding on our designs. Experimental results compared among twelve algorithms for link prediction and twenty algorithms for graph clustering validate our solutions.
Adversarially Regularized Graph Autoencoder
Feb 13, 2018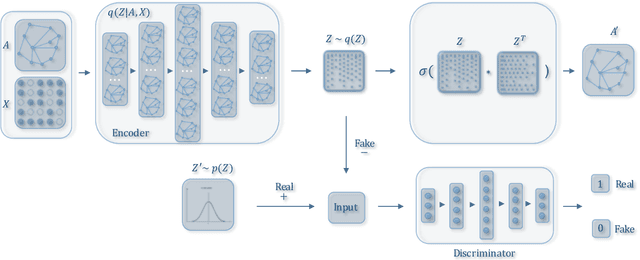
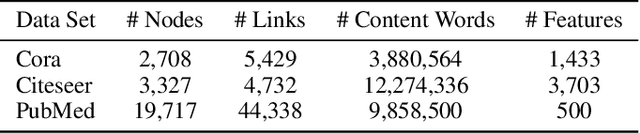
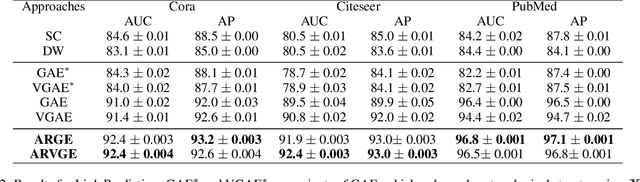
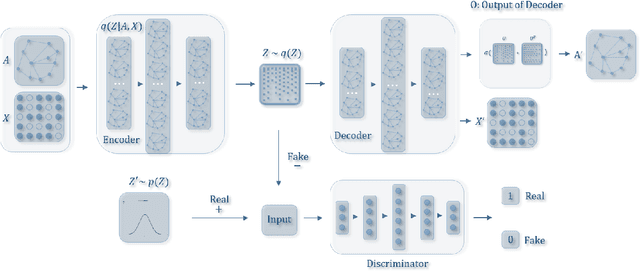
Graph embedding is an effective method to represent graph data in a low dimensional space for graph analytics. Most existing embedding algorithms typically focus on preserving the topological structure or minimizing the reconstruction errors of graph data, but they have mostly ignored the data distribution of the latent codes from the graphs, which often results in inferior embedding in real-world graph data. In this paper, we propose a novel adversarial graph embedding framework for graph data. The framework encodes the topological structure and node content in a graph to a compact representation, on which a decoder is trained to reconstruct the graph structure. Furthermore, the latent representation is enforced to match a prior distribution via an adversarial training scheme. To learn a robust embedding, two variants of adversarial approaches, adversarially regularized graph autoencoder (ARGA) and adversarially regularized variational graph autoencoder (ARVGA), are developed. Experimental studies on real-world graphs validate our design and demonstrate that our algorithms outperform baselines by a wide margin in link prediction, graph clustering, and graph visualization tasks.