 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration and Exploitation of Unlabeled Data for Open-Set Semi-Supervised Learning
Jun 30, 2023



In this paper, we address a complex but practical scenario in semi-supervised learning (SSL) named open-set SSL, where unlabeled data contain both in-distribution (ID) and out-of-distribution (OOD) samples. Unlike previous methods that only consider ID samples to be useful and aim to filter out OOD ones completely during training, we argue that the exploration and exploitation of both ID and OOD samples can benefit SSL. To support our claim, i) we propose a prototype-based clustering and identification algorithm that explores the inherent similarity and difference among samples at feature level and effectively cluster them around several predefined ID and OOD prototypes, thereby enhancing feature learning and facilitating ID/OOD identification; ii) we propose an importance-based sampling method that exploits the difference in importance of each ID and OOD sample to SSL, thereby reducing the sampling bias and improving the training. Our proposed method achieves state-of-the-art in several challenging benchmarks, and improves upon existing SSL methods even when ID samples are totally absent in unlabeled data.
CausalVLR: A Toolbox and Benchmark for Visual-Linguistic Causal Reasoning
Jun 30, 2023We present CausalVLR (Causal Visual-Linguistic Reasoning), an open-source toolbox containing a rich set of state-of-the-art causal relation discovery and causal inference methods for various visual-linguistic reasoning tasks, such as VQA, image/video captioning, medical report generation, model generalization and robustness, etc. These methods have been included in the toolbox with PyTorch implementations under NVIDIA computing system. It not only includes training and inference codes, but also provides model weights. We believe this toolbox is by far the most complete visual-linguitic causal reasoning toolbox. We wish that the toolbox and benchmark could serve the growing research community by providing a flexible toolkit to re-implement existing methods and develop their own new causal reasoning methods. Code and models are available at https://github.com/HCPLab-SYSU/Causal-VLReasoning. The project is under active development by HCP-Lab's contributors and we will keep this document updated.
DreamEditor: Text-Driven 3D Scene Editing with Neural Fields
Jun 29, 2023



Neural fields have achieved impressive advancements in view synthesis and scene reconstruction. However, editing these neural fields remains challenging due to the implicit encoding of geometry and texture information. In this paper, we propose DreamEditor, a novel framework that enables users to perform controlled editing of neural fields using text prompts. By representing scenes as mesh-based neural fields, DreamEditor allows localized editing within specific regions. DreamEditor utilizes the text encoder of a pretrained text-to-Image diffusion model to automatically identify the regions to be edited based on the semantics of the text prompts. Subsequently, DreamEditor optimizes the editing region and aligns its geometry and texture with the text prompts through score distillation sampling [29]. Extensive experiments have demonstrated that DreamEditor can accurately edit neural fields of real-world scenes according to the given text prompts while ensuring consistency in irrelevant areas. DreamEditor generates highly realistic textures and geometry, significantly surpassing previous works in both quantitative and qualitative evaluations.
DenseLight: Efficient Control for Large-scale Traffic Signals with Dense Feedback
Jun 13, 2023



Traffic Signal Control (TSC) aims to reduce the average travel time of vehicles in a road network, which in turn enhances fuel utilization efficiency, air quality, and road safety, benefiting society as a whole. Due to the complexity of long-horizon control and coordination, most prior TSC methods leverage deep reinforcement learning (RL) to search for a control policy and have witnessed great success. However, TSC still faces two significant challenges. 1) The travel time of a vehicle is delayed feedback on the effectiveness of TSC policy at each traffic intersection since it is obtained after the vehicle has left the road network. Although several heuristic reward functions have been proposed as substitutes for travel time, they are usually biased and not leading the policy to improve in the correct direction. 2) The traffic condition of each intersection is influenced by the non-local intersections since vehicles traverse multiple intersections over time. Therefore, the TSC agent is required to leverage both the local observation and the non-local traffic conditions to predict the long-horizontal traffic conditions of each intersection comprehensively. To address these challenges, we propose DenseLight, a novel RL-based TSC method that employs an unbiased reward function to provide dense feedback on policy effectiveness and a non-local enhanced TSC agent to better predict future traffic conditions for more precise traffic control. Extensive experiments and ablation studies demonstrate that DenseLight can consistently outperform advanced baselines on various road networks with diverse traffic flows. The code is available at https://github.com/junfanlin/DenseLight.
Parametric Implicit Face Representation for Audio-Driven Facial Reenactment
Jun 13, 2023



Audio-driven facial reenactment is a crucial technique that has a range of applications in film-making, virtual avatars and video conferences. Existing works either employ explicit intermediate face representations (e.g., 2D facial landmarks or 3D face models) or implicit ones (e.g., Neural Radiance Fields), thus suffering from the trade-offs between interpretability and expressive power, hence between controllability and quality of the results. In this work, we break these trade-offs with our novel parametric implicit face representation and propose a novel audio-driven facial reenactment framework that is both controllable and can generate high-quality talking heads. Specifically, our parametric implicit representation parameterizes the implicit representation with interpretable parameters of 3D face models, thereby taking the best of both explicit and implicit methods. In addition, we propose several new techniques to improve the three components of our framework, including i) incorporating contextual information into the audio-to-expression parameters encoding; ii) using conditional image synthesis to parameterize the implicit representation and implementing it with an innovative tri-plane structure for efficient learning; iii) formulating facial reenactment as a conditional image inpainting problem and proposing a novel data augmentation technique to improve model generalizability. Extensive experiments demonstrate that our method can generate more realistic results than previous methods with greater fidelity to the identities and talking styles of speakers.
YONA: You Only Need One Adjacent Reference-frame for Accurate and Fast Video Polyp Detection
Jun 06, 2023



Accurate polyp detection is essential for assisting clinical rectal cancer diagnoses. Colonoscopy videos contain richer information than still images, making them a valuable resource for deep learning methods. Great efforts have been made to conduct video polyp detection through multi-frame temporal/spatial aggregation. However, unlike common fixed-camera video, the camera-moving scene in colonoscopy videos can cause rapid video jitters, leading to unstable training for existing video detection models. Additionally, the concealed nature of some polyps and the complex background environment further hinder the performance of existing video detectors. In this paper, we propose the \textbf{YONA} (\textbf{Y}ou \textbf{O}nly \textbf{N}eed one \textbf{A}djacent Reference-frame) method, an efficient end-to-end training framework for video polyp detection. YONA fully exploits the information of one previous adjacent frame and conducts polyp detection on the current frame without multi-frame collaborations. Specifically, for the foreground, YONA adaptively aligns the current frame's channel activation patterns with its adjacent reference frames according to their foreground similarity. For the background, YONA conducts background dynamic alignment guided by inter-frame difference to eliminate the invalid features produced by drastic spatial jitters. Moreover, YONA applies cross-frame contrastive learning during training, leveraging the ground truth bounding box to improve the model's perception of polyp and background. Quantitative and qualitative experiments on three public challenging benchmarks demonstrate that our proposed YONA outperforms previous state-of-the-art competitors by a large margin in both accuracy and speed.
Long-term Wind Power Forecasting with Hierarchical Spatial-Temporal Transformer
May 30, 2023Wind power is attracting increasing attention around the world due to its renewable, pollution-free, and other advantages. However, safely and stably integrating the high permeability intermittent power energy into electric power systems remains challenging. Accurate wind power forecasting (WPF) can effectively reduce power fluctuations in power system operations. Existing methods are mainly designed for short-term predictions and lack effective spatial-temporal feature augmentation. In this work, we propose a novel end-to-end wind power forecasting model named Hierarchical Spatial-Temporal Transformer Network (HSTTN) to address the long-term WPF problems. Specifically, we construct an hourglass-shaped encoder-decoder framework with skip-connections to jointly model representations aggregated in hierarchical temporal scales, which benefits long-term forecasting. Based on this framework, we capture the inter-scale long-range temporal dependencies and global spatial correlations with two parallel Transformer skeletons and strengthen the intra-scale connections with downsampling and upsampling operations. Moreover, the complementary information from spatial and temporal features is fused and propagated in each other via Contextual Fusion Blocks (CFBs) to promote the prediction further. Extensive experimental results on two large-scale real-world datasets demonstrate the superior performance of our HSTTN over existing solutions.
Identity-Preserving Talking Face Generation with Landmark and Appearance Priors
May 15, 2023



Generating talking face videos from audio attracts lots of research interest. A few person-specific methods can generate vivid videos but require the target speaker's videos for training or fine-tuning. Existing person-generic methods have difficulty in generating realistic and lip-synced videos while preserving identity information. To tackle this problem, we propose a two-stage framework consisting of audio-to-landmark generation and landmark-to-video rendering procedures. First, we devise a novel Transformer-based landmark generator to infer lip and jaw landmarks from the audio. Prior landmark characteristics of the speaker's face are employed to make the generated landmarks coincide with the facial outline of the speaker. Then, a video rendering model is built to translate the generated landmarks into face images. During this stage, prior appearance information is extracted from the lower-half occluded target face and static reference images, which helps generate realistic and identity-preserving visual content. For effectively exploring the prior information of static reference images, we align static reference images with the target face's pose and expression based on motion fields. Moreover, auditory features are reused to guarantee that the generated face images are well synchronized with the audio. Extensive experiments demonstrate that our method can produce more realistic, lip-synced, and identity-preserving videos than existing person-generic talking face generation methods.
Visual Causal Scene Refinement for Video Question Answering
May 07, 2023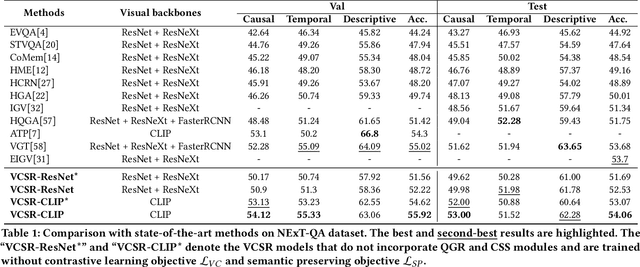
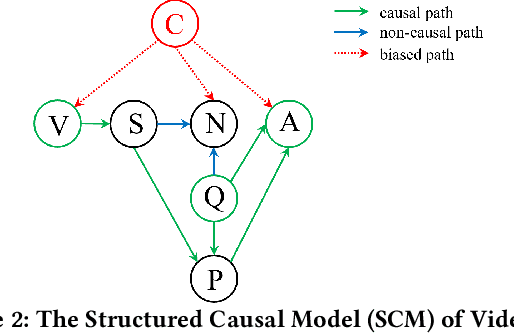
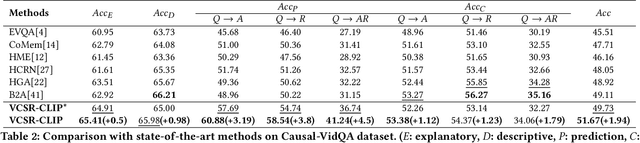
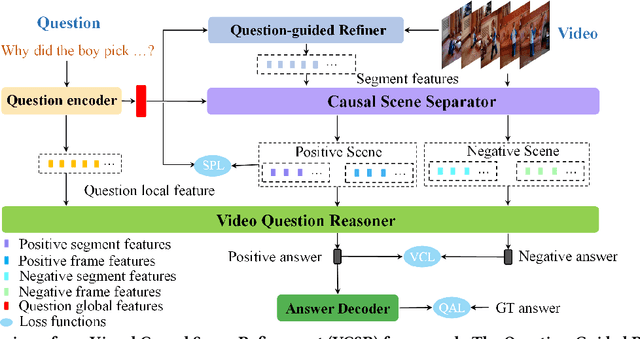
Existing methods for video question answering (VideoQA) often suffer from spurious correlations between different modalities, leading to a failure in identifying the dominant visual evidence and the intended question. Moreover, these methods function as black boxes, making it difficult to interpret the visual scene during the QA process. In this paper, to discover critical video segments and frames that serve as the visual causal scene for generating reliable answers, we present a causal analysis of VideoQA and propose a framework for cross-modal causal relational reasoning, named Visual Causal Scene Refinement (VCSR). Particularly, a set of causal front-door intervention operations is introduced to explicitly find the visual causal scenes at both segment and frame levels. Our VCSR involves two essential modules: i) the Question-Guided Refiner (QGR) module, which refines consecutive video frames guided by the question semantics to obtain more representative segment features for causal front-door intervention; ii) the Causal Scene Separator (CSS) module, which discovers a collection of visual causal and non-causal scenes based on the visual-linguistic causal relevance and estimates the causal effect of the scene-separating intervention in a contrastive learning manner. Extensive experiments on the NExT-QA, Causal-VidQA, and MSRVTT-QA datasets demonstrate the superiority of our VCSR in discovering visual causal scene and achieving robust video question answering.
SCoDA: Domain Adaptive Shape Completion for Real Scans
Apr 24, 20233D shape completion from point clouds is a challenging task, especially from scans of real-world objects. Considering the paucity of 3D shape ground truths for real scans, existing works mainly focus on benchmarking this task on synthetic data, e.g. 3D computer-aided design models. However, the domain gap between synthetic and real data limits the generalizability of these methods. Thus, we propose a new task, SCoDA, for the domain adaptation of real scan shape completion from synthetic data. A new dataset, ScanSalon, is contributed with a bunch of elaborate 3D models created by skillful artists according to scans. To address this new task, we propose a novel cross-domain feature fusion method for knowledge transfer and a novel volume-consistent self-training framework for robust learning from real data. Extensive experiments prove our method is effective to bring an improvement of 6%~7% mIoU.