 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeletonMAE: Graph-based Masked Autoencoder for Skeleton Sequence Pre-training
Jul 17, 2023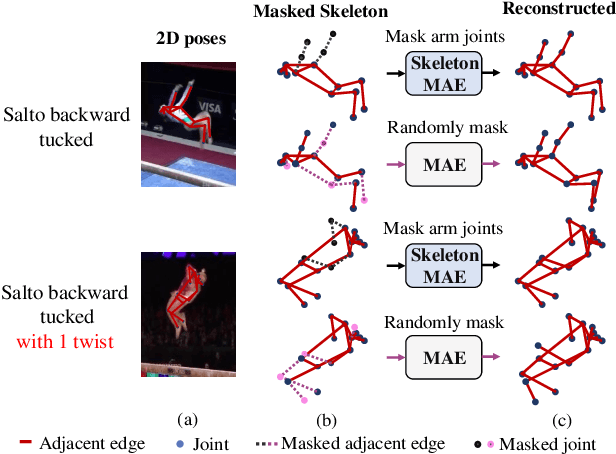
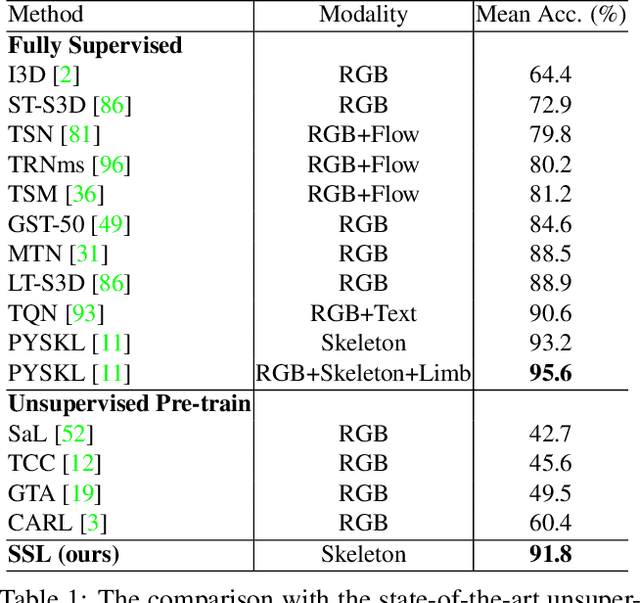
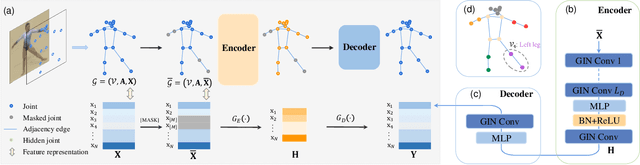
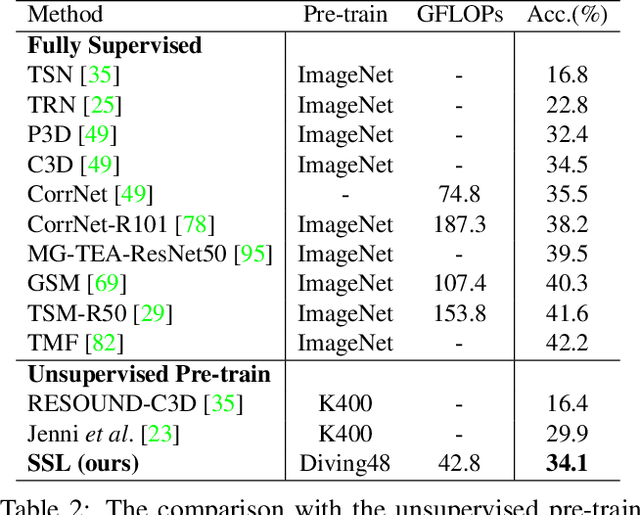
Skeleton sequence representation learning has shown great advantages for action recognition due to its promising ability to model human joints and topology. However, the current methods usually require sufficient labeled data for training computationally expensive models, which is labor-intensive and time-consuming. Moreover, these methods ignore how to utilize the fine-grained dependencies among different skeleton joints to pre-train an efficient skeleton sequence learning model that can generalize well across different datasets. In this paper, we propose an efficient skeleton sequence learning framework, named Skeleton Sequence Learning (SSL). To comprehensively capture the human pose and obtain discriminative skeleton sequence representation, we build an asymmetric graph-based encoder-decoder pre-training architecture named SkeletonMAE, which embeds skeleton joint sequence into Graph Convolutional Network (GCN) and reconstructs the masked skeleton joints and edges based on the prior human topology knowledge. Then, the pre-trained SkeletonMAE encoder is integrated with the Spatial-Temporal Representation Learning (STRL) module to build the SSL framework. Extensive experimental results show that our SSL generalizes well across different datasets and outperforms the state-of-the-art self-supervised skeleton-based action recognition methods on FineGym, Diving48, NTU 60 and NTU 120 datasets. Additionally, we obtain comparable performance to some fully supervised methods. The code is avaliable at https://github.com/HongYan1123/SkeletonMAE.
Visual Causal Scene Refinement for Video Question Answering
May 07, 2023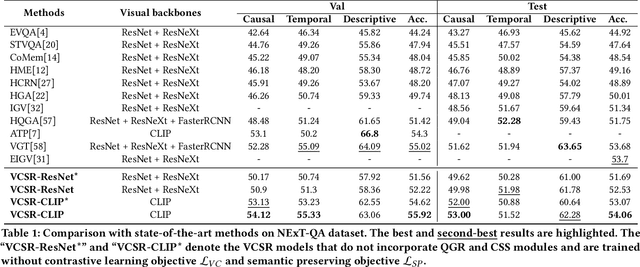
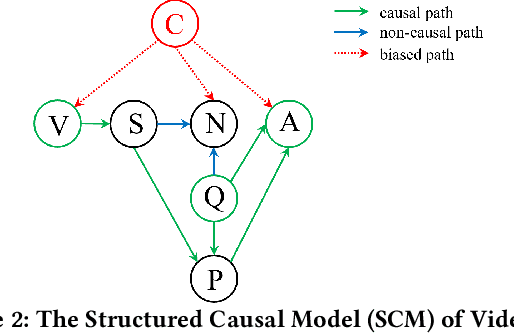
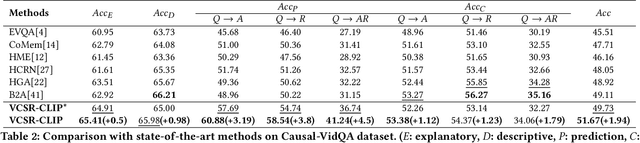
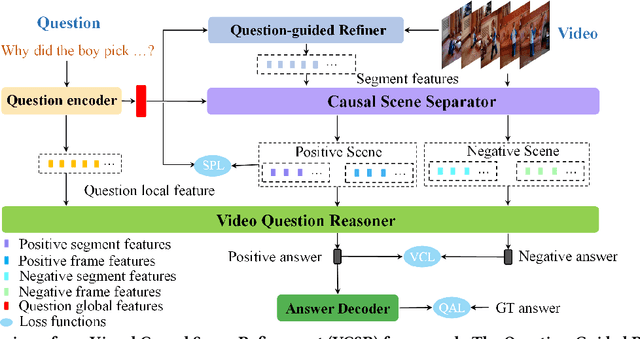
Existing methods for video question answering (VideoQA) often suffer from spurious correlations between different modalities, leading to a failure in identifying the dominant visual evidence and the intended question. Moreover, these methods function as black boxes, making it difficult to interpret the visual scene during the QA process. In this paper, to discover critical video segments and frames that serve as the visual causal scene for generating reliable answers, we present a causal analysis of VideoQA and propose a framework for cross-modal causal relational reasoning, named Visual Causal Scene Refinement (VCSR). Particularly, a set of causal front-door intervention operations is introduced to explicitly find the visual causal scenes at both segment and frame levels. Our VCSR involves two essential modules: i) the Question-Guided Refiner (QGR) module, which refines consecutive video frames guided by the question semantics to obtain more representative segment features for causal front-door intervention; ii) the Causal Scene Separator (CSS) module, which discovers a collection of visual causal and non-causal scenes based on the visual-linguistic causal relevance and estimates the causal effect of the scene-separating intervention in a contrastive learning manner. Extensive experiments on the NExT-QA, Causal-VidQA, and MSRVTT-QA datasets demonstrate the superiority of our VCSR in discovering visual causal scene and achieving robust video question answering.
Causal Reasoning with Spatial-temporal Representation Learning: A Prospective Study
May 05, 2022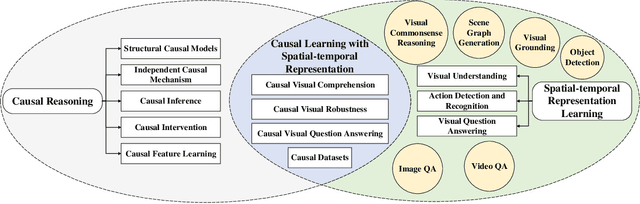
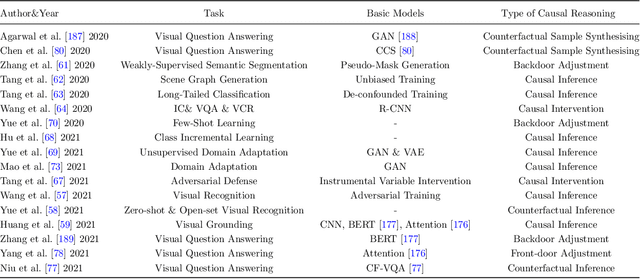
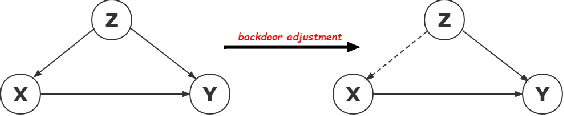
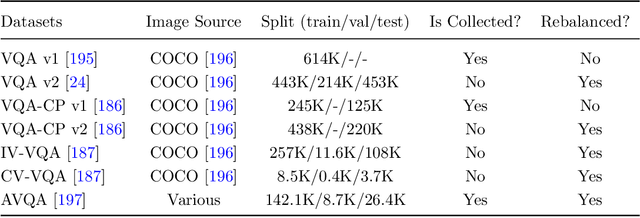
Spatial-temporal representation learning is ubiquitous in various real-world applications, including visual comprehension, video understanding, multi-modal analysis, human-computer interaction, and urban computing. Due to the emergence of huge amounts of multi-modal heterogeneous spatial/temporal/spatial-temporal data in big data era, the lack of interpretability, robustness, and out-of-distribution generalization are becoming the challenges of the existing visual models. The majority of the existing methods tend to fit the original data/variable distributions and ignore the essential causal relations behind the multi-modal knowledge, which lacks an unified guidance and analysis about why modern spatial-temporal representation learning methods are easily collapse into data bias and have limited generalization and cognitive abilities. Inspired by the strong inference ability of human-level agents, recent years have therefore witnessed great effort in developing causal reasoning paradigms to realize robust representation and model learning with good cognitive ability. In this paper, we conduct a comprehensive review of existing causal reasoning methods for spatial-temporal representation learning, covering fundamental theories, models, and datasets. The limitations of current methods and datasets are also discussed. Moreover, we propose some primary challenges, opportunities, and future research directions for benchmarking causal reasoning algorithms in spatial-temporal representation learning. This paper aims to provide a comprehensive overview of this emerging field, attract attention, encourage discussions, bring to the forefront the urgency of developing novel causal reasoning methods, publicly available benchmarks, and consensus-building standards for reliable spatial-temporal representation learning and related real-world applications more efficiently.