 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Staff: Offline Reinforcement Learning and Fine-Tuned LLMs for Warehouse Staffing Optimization
Mar 25, 2026We investigate machine learning approaches for optimizing real-time staffing decisions in semi-automated warehouse sortation systems. Operational decision-making can be supported at different levels of abstraction, with different trade-offs. We evaluate two approaches, each in a matching simulation environment. First, we train custom Transformer-based policies using offline reinforcement learning on detailed historical state representations, achieving a 2.4% throughput improvement over historical baselines in learned simulators. In high-volume warehouse operations, improvements of this size translate to significant savings. Second, we explore LLMs operating on abstracted, human-readable state descriptions. These are a natural fit for decisions that warehouse managers make using high-level operational summaries. We systematically compare prompting techniques, automatic prompt optimization, and fine-tuning strategies. While prompting alone proves insufficient, supervised fine-tuning combined with Direct Preference Optimization on simulator-generated preferences achieves performance that matches or slightly exceeds historical baselines in a hand-crafted simulator. Our findings demonstrate that both approaches offer viable paths toward AI-assisted operational decision-making. Offline RL excels with task-specific architectures. LLMs support human-readable inputs and can be combined with an iterative feedback loop that can incorporate manager preferences.
Hurdle-IMDL: An Imbalanced Learning Framework for Infrared Rainfall Retrieval
Oct 23, 2025Artificial intelligence has advanced quantitative remote sensing, yet its effectiveness is constrained by imbalanced label distribution. This imbalance leads conventionally trained models to favor common samples, which in turn degrades retrieval performance for rare ones. Rainfall retrieval exemplifies this issue, with performance particularly compromised for heavy rain. This study proposes Hurdle-Inversion Model Debiasing Learning (IMDL) framework. Following a divide-and-conquer strategy, imbalance in the rain distribution is decomposed into two components: zero inflation, defined by the predominance of non-rain samples; and long tail, defined by the disproportionate abundance of light-rain samples relative to heavy-rain samples. A hurdle model is adopted to handle the zero inflation, while IMDL is proposed to address the long tail by transforming the learning object into an unbiased ideal inverse model. Comprehensive evaluation via statistical metrics and case studies investigating rainy weather in eastern China confirms Hurdle-IMDL's superiority over conventional, cost-sensitive, generative, and multi-task learning methods. Its key advancements include effective mitigation of systematic underestimation and a marked improvement in the retrieval of heavy-to-extreme rain. IMDL offers a generalizable approach for addressing imbalance in distributions of environmental variables, enabling enhanced retrieval of rare yet high-impact events.
Uncovering Customer Issues through Topological Natural Language Analysis
Feb 24, 2024E-commerce companies deal with a high volume of customer service requests daily. While a simple annotation system is often used to summarize the topics of customer contacts, thoroughly exploring each specific issue can be challenging. This presents a critical concern, especially during an emerging outbreak where companies must quickly identify and address specific issues. To tackle this challenge, we propose a novel machine learning algorithm that leverages natural language techniques and topological data analysis to monitor emerging and trending customer issues. Our approach involves an end-to-end deep learning framework that simultaneously tags the primary question sentence of each customer's transcript and generates sentence embedding vectors. We then whiten the embedding vectors and use them to construct an undirected graph. From there, we define trending and emerging issues based on the topological properties of each transcript. We have validated our results through various methods and found that they are highly consistent with news sources.
Universal Model in Online Customer Service
Feb 24, 2024



Building machine learning models can be a time-consuming process that often takes several months to implement in typical business scenarios. To ensure consistent model performance and account for variations in data distribution, regular retraining is necessary. This paper introduces a solution for improving online customer service in e-commerce by presenting a universal model for predict-ing labels based on customer questions, without requiring training. Our novel approach involves using machine learning techniques to tag customer questions in transcripts and create a repository of questions and corresponding labels. When a customer requests assistance, an information retrieval model searches the repository for similar questions, and statistical analysis is used to predict the corresponding label. By eliminating the need for individual model training and maintenance, our approach reduces both the model development cycle and costs. The repository only requires periodic updating to maintain accuracy.
Teacher-Student Learning on Complexity in Intelligent Routing
Feb 24, 2024



Customer service is often the most time-consuming aspect for e-commerce websites, with each contact typically taking 10-15 minutes. Effectively routing customers to appropriate agents without transfers is therefore crucial for e-commerce success. To this end, we have developed a machine learning framework that predicts the complexity of customer contacts and routes them to appropriate agents accordingly. The framework consists of two parts. First, we train a teacher model to score the complexity of a contact based on the post-contact transcripts. Then, we use the teacher model as a data annotator to provide labels to train a student model that predicts the complexity based on pre-contact data only. Our experiments show that such a framework is successful and can significantly improve customer experience. We also propose a useful metric called complexity AUC that evaluates the effectiveness of customer service at a statistical level.
DenseLight: Efficient Control for Large-scale Traffic Signals with Dense Feedback
Jun 13, 2023



Traffic Signal Control (TSC) aims to reduce the average travel time of vehicles in a road network, which in turn enhances fuel utilization efficiency, air quality, and road safety, benefiting society as a whole. Due to the complexity of long-horizon control and coordination, most prior TSC methods leverage deep reinforcement learning (RL) to search for a control policy and have witnessed great success. However, TSC still faces two significant challenges. 1) The travel time of a vehicle is delayed feedback on the effectiveness of TSC policy at each traffic intersection since it is obtained after the vehicle has left the road network. Although several heuristic reward functions have been proposed as substitutes for travel time, they are usually biased and not leading the policy to improve in the correct direction. 2) The traffic condition of each intersection is influenced by the non-local intersections since vehicles traverse multiple intersections over time. Therefore, the TSC agent is required to leverage both the local observation and the non-local traffic conditions to predict the long-horizontal traffic conditions of each intersection comprehensively. To address these challenges, we propose DenseLight, a novel RL-based TSC method that employs an unbiased reward function to provide dense feedback on policy effectiveness and a non-local enhanced TSC agent to better predict future traffic conditions for more precise traffic control. Extensive experiments and ablation studies demonstrate that DenseLight can consistently outperform advanced baselines on various road networks with diverse traffic flows. The code is available at https://github.com/junfanlin/DenseLight.
Online Metro Origin-Destination Prediction via Heterogeneous Information Aggregation
Aug 02, 2021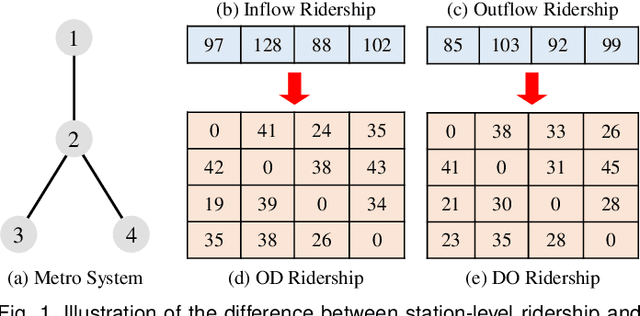
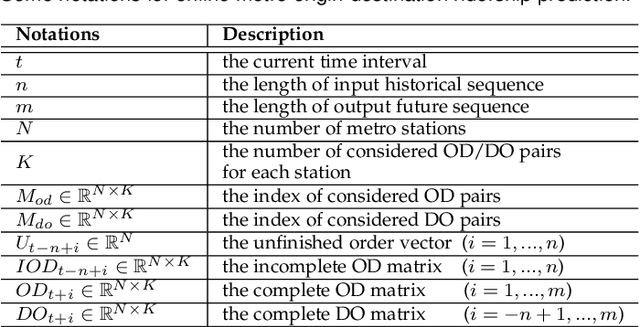
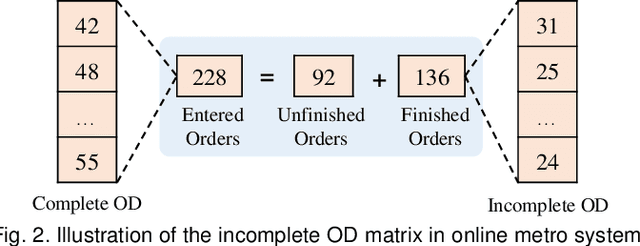
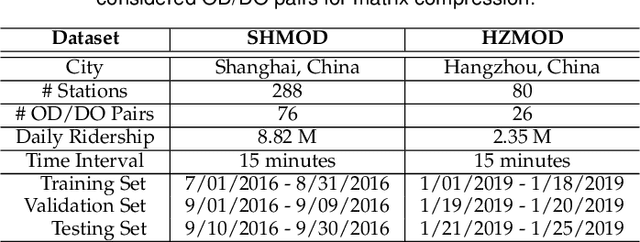
Metro origin-destination prediction is a crucial yet challenging time-series analysis task in intelligent transportation systems, which aims to accurately forecast two specific types of cross-station ridership, i.e., Origin-Destination (OD) one and Destination-Origin (DO) one. However, complete OD matrices of previous time intervals can not be obtained immediately in online metro systems, and conventional methods only used limited information to forecast the future OD and DO ridership separately. In this work, we proposed a novel neural network module termed Heterogeneous Information Aggregation Machine (HIAM), which fully exploits heterogeneous information of historical data (e.g., incomplete OD matrices, unfinished order vectors, and DO matrices) to jointly learn the evolutionary patterns of OD and DO ridership. Specifically, an OD modeling branch estimates the potential destinations of unfinished orders explicitly to complement the information of incomplete OD matrices, while a DO modeling branch takes DO matrices as input to capture the spatial-temporal distribution of DO ridership. Moreover, a Dual Information Transformer is introduced to propagate the mutual information among OD features and DO features for modeling the OD-DO causality and correlation. Based on the proposed HIAM, we develop a unified Seq2Seq network to forecast the future OD and DO ridership simultaneously. Extensive experiments conducted on two large-scale benchmarks demonstrate the effectiveness of our method for online metro origin-destination prediction.
MTGAT: Multimodal Temporal Graph Attention Networks for Unaligned Human Multimodal Language Sequences
Oct 22, 2020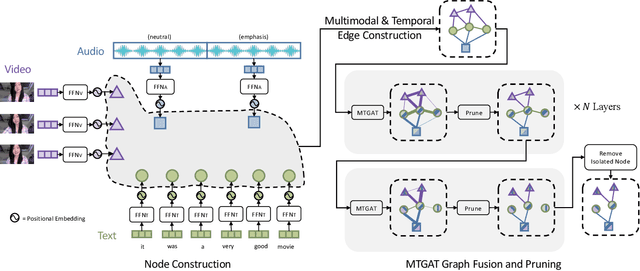
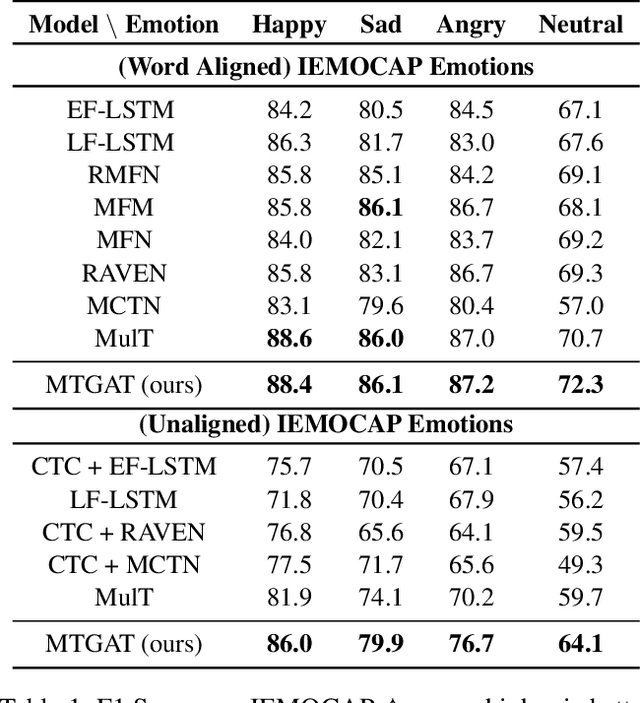
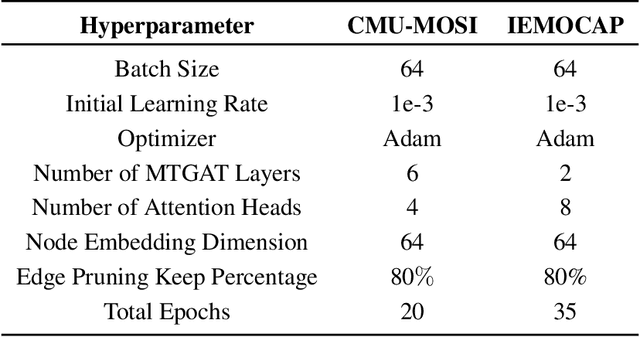
Human communication is multimodal in nature; it is through multiple modalities, i.e., language, voice, and facial expressions, that opinions and emotions are expressed. Data in this domain exhibits complex multi-relational and temporal interactions. Learning from this data is a fundamentally challenging research problem. In this paper, we propose Multimodal Temporal Graph Attention Networks (MTGAT). MTGAT is an interpretable graph-based neural model that provides a suitable framework for analyzing this type of multimodal sequential data. We first introduce a procedure to convert unaligned multimodal sequence data into a graph with heterogeneous nodes and edges that captures the rich interactions between different modalities through time. Then, a novel graph operation, called Multimodal Temporal Graph Attention, along with a dynamic pruning and read-out technique is designed to efficiently process this multimodal temporal graph. By learning to focus only on the important interactions within the graph, our MTGAT is able to achieve state-of-the-art performance on multimodal sentiment analysis and emotion recognition benchmarks including IEMOCAP and CMU-MOSI, while utilizing significantly fewer computations.
What Gives the Answer Away? Question Answering Bias Analysis on Video QA Datasets
Jul 07, 2020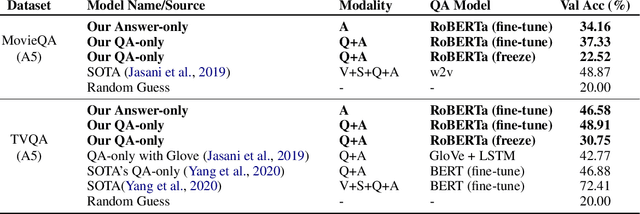
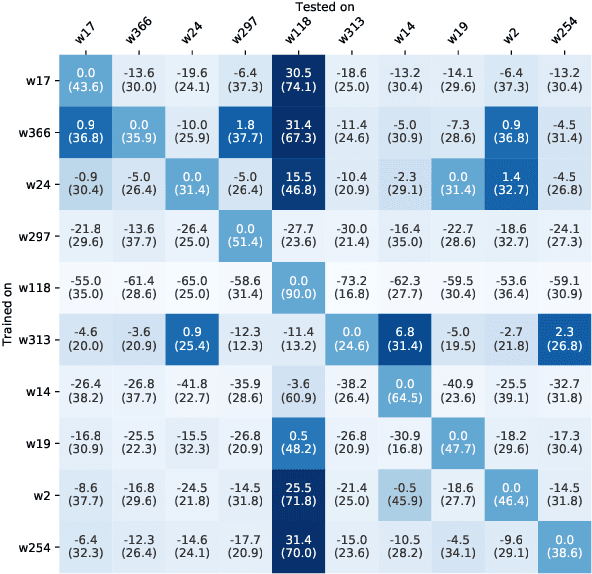

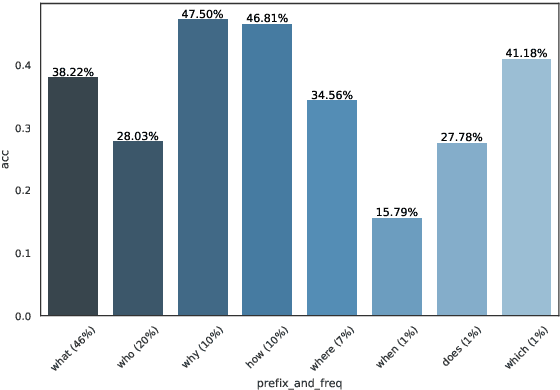
Question answering biases in video QA datasets can mislead multimodal model to overfit to QA artifacts and jeopardize the model's ability to generalize. Understanding how strong these QA biases are and where they come from helps the community measure progress more accurately and provide researchers insights to debug their models. In this paper, we analyze QA biases in popular video question answering datasets and discover pretrained language models can answer 37-48% questions correctly without using any multimodal context information, far exceeding the 20% random guess baseline for 5-choose-1 multiple-choice questions. Our ablation study shows biases can come from annotators and type of questions. Specifically, annotators that have been seen during training are better predicted by the model and reasoning, abstract questions incur more biases than factual, direct questions. We also show empirically that using annotator-non-overlapping train-test splits can reduce QA biases for video QA datasets.
CAN-NER: Convolutional Attention Network for Chinese Named Entity Recognition
Apr 30, 2019
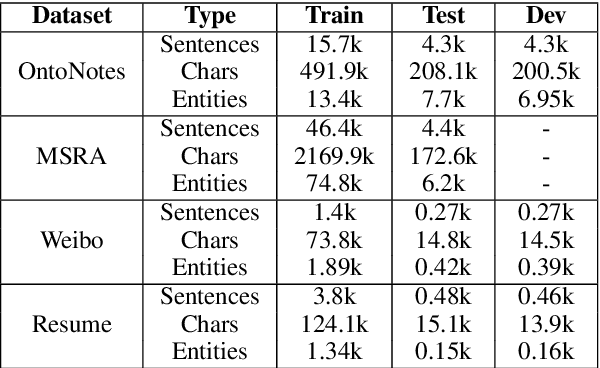
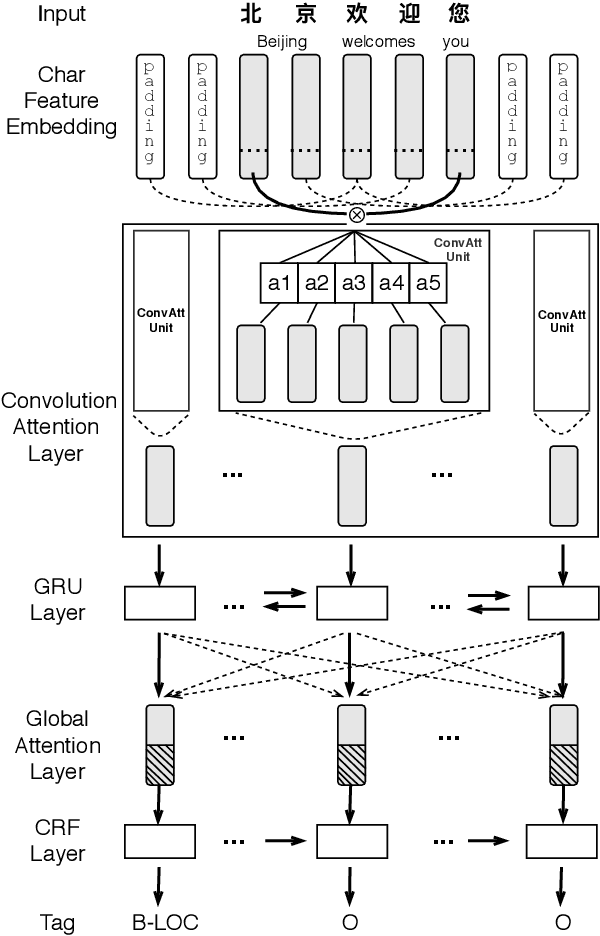
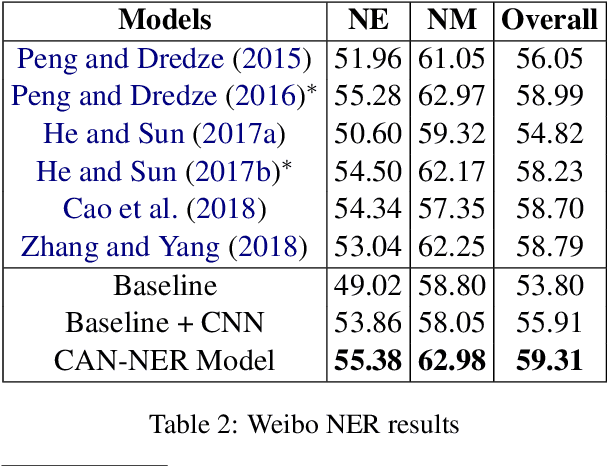
Named entity recognition (NER) in Chinese is essential but difficult because of the lack of natural delimiters. Therefore, Chinese Word Segmentation (CWS) is usually considered as the first step for Chinese NER. However, models based on word-level embeddings and lexicon features often suffer from segmentation errors and out-of-vocabulary (OOV) words. In this paper, we investigate a Convolutional Attention Network called CAN for Chinese NER, which consists of a character-based convolutional neural network (CNN) with local-attention layer and a gated recurrent unit (GRU) with global self-attention layer to capture the information from adjacent characters and sentence contexts. Also, compared to other models, not depending on any external resources like lexicons and employing small size of char embeddings make our model more practical. Extensive experimental results show that our approach outperforms state-of-the-art methods without word embedding and external lexicon resources on different domain datasets including Weibo, MSRA and Chinese Resume NER dataset.