 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Control of Situated Agents through Natural Language
Sep 16, 2021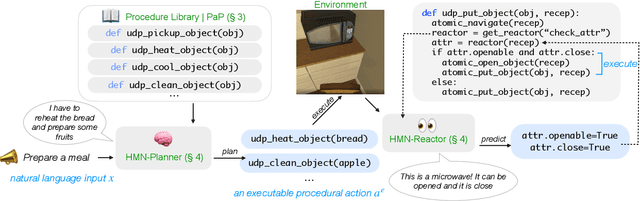


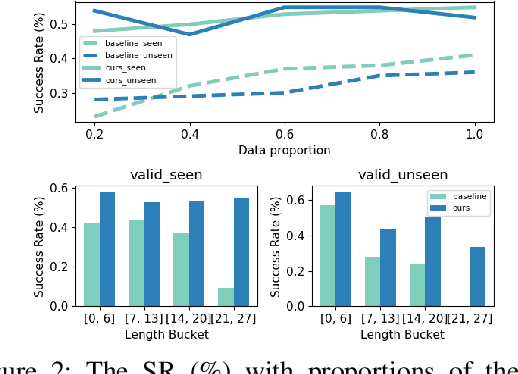
When humans conceive how to perform a particular task, they do so hierarchically: splitting higher-level tasks into smaller sub-tasks. However, in the literature on natural language (NL) command of situated agents, most works have treated the procedures to be executed as flat sequences of simple actions, or any hierarchies of procedures have been shallow at best. In this paper, we propose a formalism of procedures as programs, a powerful yet intuitive method of representing hierarchical procedural knowledge for agent command and control. We further propose a modeling paradigm of hierarchical modular networks, which consist of a planner and reactors that convert NL intents to predictions of executable programs and probe the environment for information necessary to complete the program execution. We instantiate this framework on the IQA and ALFRED datasets for NL instruction following. Our model outperforms reactive baselines by a large margin on both datasets. We also demonstrate that our framework is more data-efficient, and that it allows for fast iterative development.
When Does Translation Require Context? A Data-driven, Multilingual Exploration
Sep 15, 2021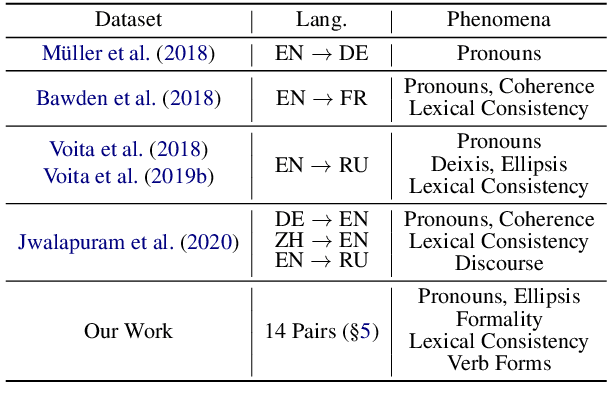
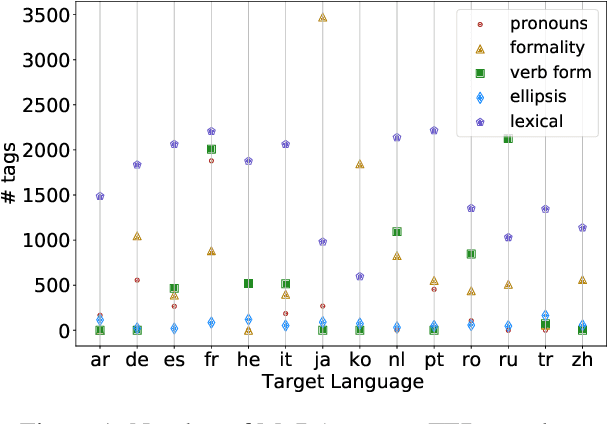

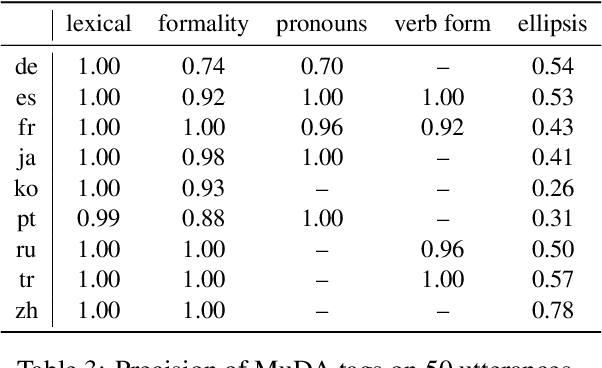
Although proper handling of discourse phenomena significantly contributes to the quality of machine translation (MT), common translation quality metrics do not adequately capture them. Recent works in context-aware MT attempt to target a small set of these phenomena during evaluation. In this paper, we propose a new metric, P-CXMI, which allows us to identify translations that require context systematically and confirm the difficulty of previously studied phenomena as well as uncover new ones that have not been addressed in previous work. We then develop the Multilingual Discourse-Aware (MuDA) benchmark, a series of taggers for these phenomena in 14 different language pairs, which we use to evaluate context-aware MT. We find that state-of-the-art context-aware MT models find marginal improvements over context-agnostic models on our benchmark, which suggests current models do not handle these ambiguities effectively. We release code and data to invite the MT research community to increase efforts on context-aware translation on discourse phenomena and languages that are currently overlooked.
Should We Be Pre-training? An Argument for End-task Aware Training as an Alternative
Sep 15, 2021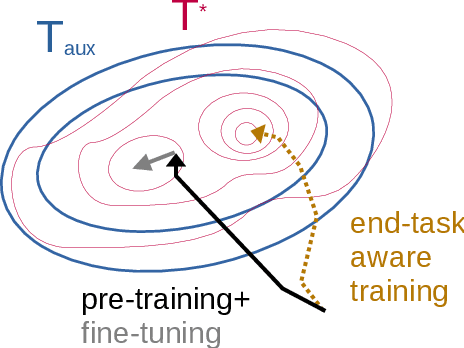

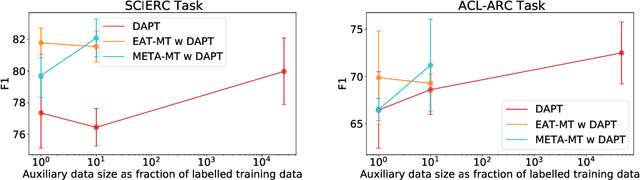
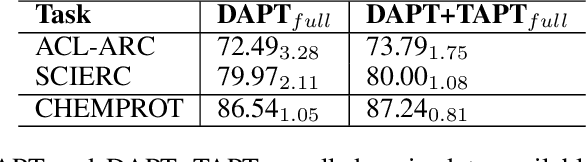
Pre-training, where models are trained on an auxiliary objective with abundant data before being fine-tuned on data from the downstream task, is now the dominant paradigm in NLP. In general, the pre-training step relies on little to no direct knowledge of the task on which the model will be fine-tuned, even when the end-task is known in advance. Our work challenges this status-quo of end-task agnostic pre-training. First, on three different low-resource NLP tasks from two domains, we demonstrate that multi-tasking the end-task and auxiliary objectives results in significantly better downstream task performance than the widely-used task-agnostic continued pre-training paradigm of Gururangan et al. (2020). We next introduce an online meta-learning algorithm that learns a set of multi-task weights to better balance among our multiple auxiliary objectives, achieving further improvements on end task performance and data efficiency.
When is Wall a Pared and when a Muro? -- Extracting Rules Governing Lexical Selection
Sep 13, 2021
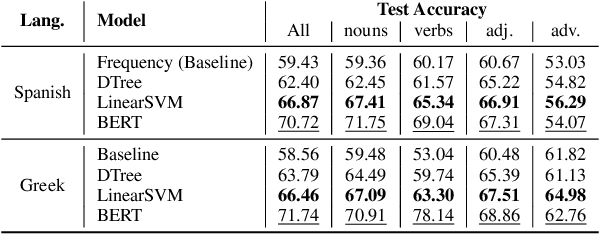
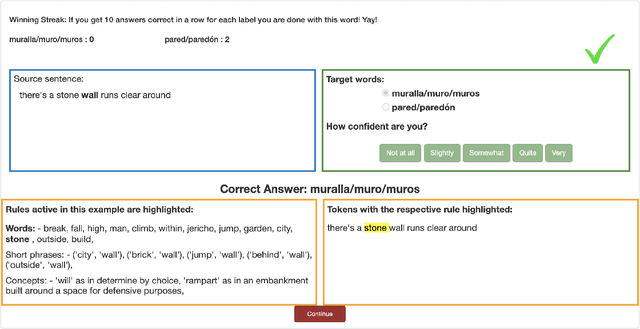

Learning fine-grained distinctions between vocabulary items is a key challenge in learning a new language. For example, the noun "wall" has different lexical manifestations in Spanish -- "pared" refers to an indoor wall while "muro" refers to an outside wall. However, this variety of lexical distinction may not be obvious to non-native learners unless the distinction is explained in such a way. In this work, we present a method for automatically identifying fine-grained lexical distinctions, and extracting concise descriptions explaining these distinctions in a human- and machine-readable format. We confirm the quality of these extracted descriptions in a language learning setup for two languages, Spanish and Greek, where we use them to teach non-native speakers when to translate a given ambiguous word into its different possible translations. Code and data are publicly released here (https://github.com/Aditi138/LexSelection)
Efficient Test Time Adapter Ensembling for Low-resource Language Varieties
Sep 10, 2021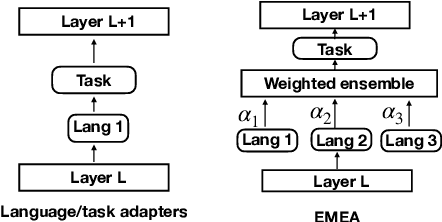

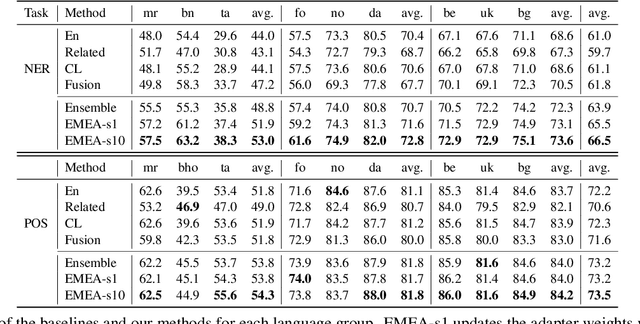
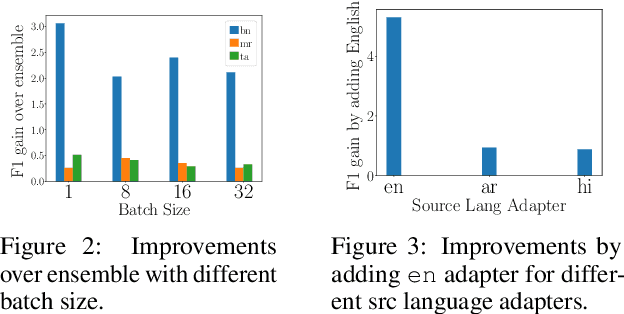
Adapters are light-weight modules that allow parameter-efficient fine-tuning of pretrained models. Specialized language and task adapters have recently been proposed to facilitate cross-lingual transfer of multilingual pretrained models (Pfeiffer et al., 2020b). However, this approach requires training a separate language adapter for every language one wishes to support, which can be impractical for languages with limited data. An intuitive solution is to use a related language adapter for the new language variety, but we observe that this solution can lead to sub-optimal performance. In this paper, we aim to improve the robustness of language adapters to uncovered languages without training new adapters. We find that ensembling multiple existing language adapters makes the fine-tuned model significantly more robust to other language varieties not included in these adapters. Building upon this observation, we propose Entropy Minimized Ensemble of Adapters (EMEA), a method that optimizes the ensemble weights of the pretrained language adapters for each test sentence by minimizing the entropy of its predictions. Experiments on three diverse groups of language varieties show that our method leads to significant improvements on both named entity recognition and part-of-speech tagging across all languages.
AfroMT: Pretraining Strategies and Reproducible Benchmarks for Translation of 8 African Languages
Sep 10, 2021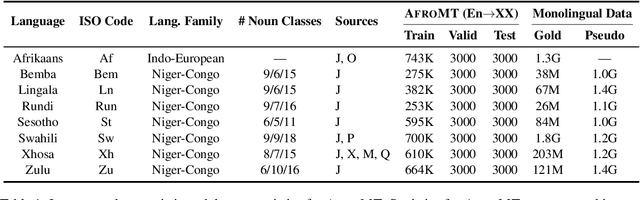
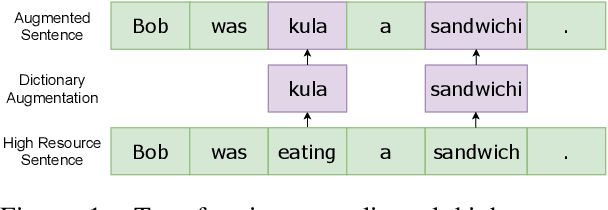
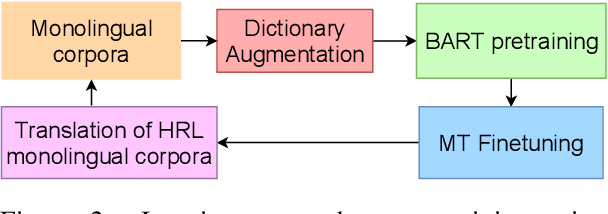
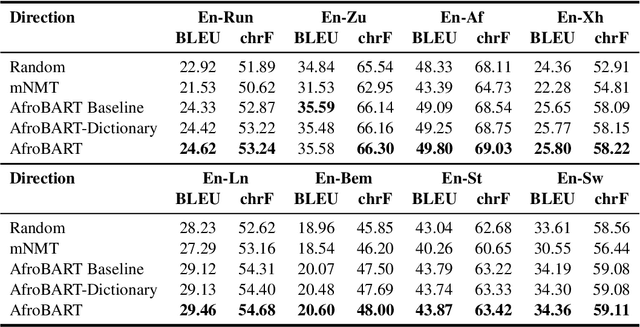
Reproducible benchmarks are crucial in driving progress of machine translation research. However, existing machine translation benchmarks have been mostly limited to high-resource or well-represented languages. Despite an increasing interest in low-resource machine translation, there are no standardized reproducible benchmarks for many African languages, many of which are used by millions of speakers but have less digitized textual data. To tackle these challenges, we propose AfroMT, a standardized, clean, and reproducible machine translation benchmark for eight widely spoken African languages. We also develop a suite of analysis tools for system diagnosis taking into account the unique properties of these languages. Furthermore, we explore the newly considered case of low-resource focused pretraining and develop two novel data augmentation-based strategies, leveraging word-level alignment information and pseudo-monolingual data for pretraining multilingual sequence-to-sequence models. We demonstrate significant improvements when pretraining on 11 languages, with gains of up to 2 BLEU points over strong baselines. We also show gains of up to 12 BLEU points over cross-lingual transfer baselines in data-constrained scenarios. All code and pretrained models will be released as further steps towards larger reproducible benchmarks for African languages.
Efficient Nearest Neighbor Language Models
Sep 09, 2021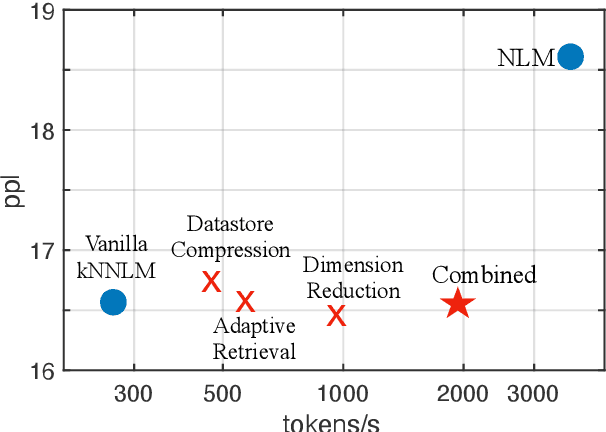
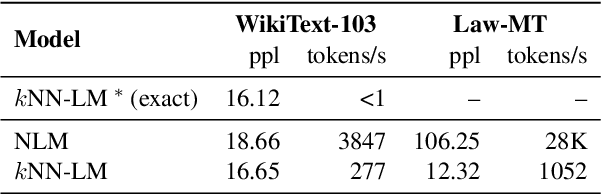
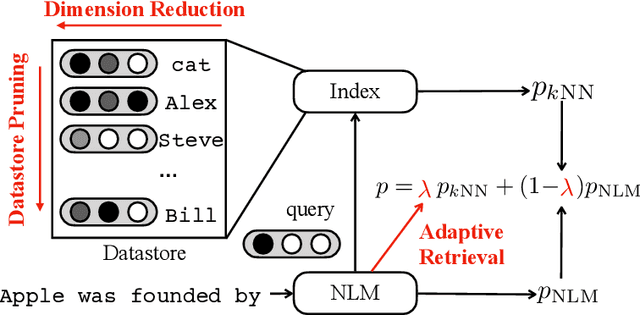

Non-parametric neural language models (NLMs) learn predictive distributions of text utilizing an external datastore, which allows them to learn through explicitly memorizing the training datapoints. While effective, these models often require retrieval from a large datastore at test time, significantly increasing the inference overhead and thus limiting the deployment of non-parametric NLMs in practical applications. In this paper, we take the recently proposed $k$-nearest neighbors language model (Khandelwal et al., 2019) as an example, exploring methods to improve its efficiency along various dimensions. Experiments on the standard WikiText-103 benchmark and domain-adaptation datasets show that our methods are able to achieve up to a 6x speed-up in inference speed while retaining comparable performance. The empirical analysis we present may provide guidelines for future research seeking to develop or deploy more efficient non-parametric NLMs.
Distributionally Robust Multilingual Machine Translation
Sep 09, 2021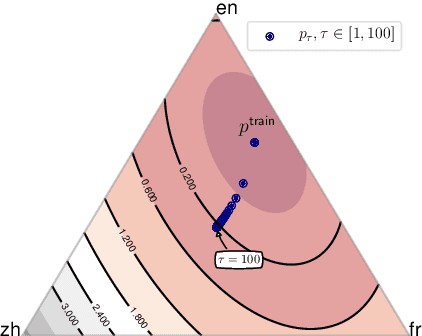
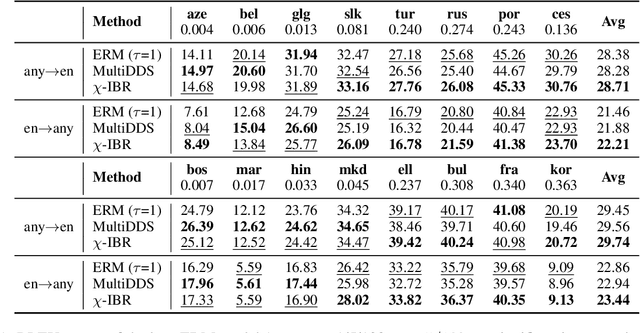
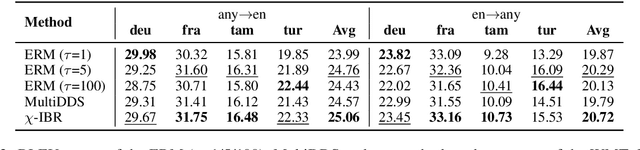
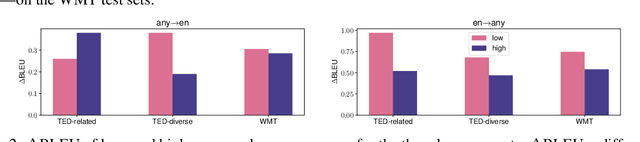
Multilingual neural machine translation (MNMT) learns to translate multiple language pairs with a single model, potentially improving both the accuracy and the memory-efficiency of deployed models. However, the heavy data imbalance between languages hinders the model from performing uniformly across language pairs. In this paper, we propose a new learning objective for MNMT based on distributionally robust optimization, which minimizes the worst-case expected loss over the set of language pairs. We further show how to practically optimize this objective for large translation corpora using an iterated best response scheme, which is both effective and incurs negligible additional computational cost compared to standard empirical risk minimization. We perform extensive experiments on three sets of languages from two datasets and show that our method consistently outperforms strong baseline methods in terms of average and per-language performance under both many-to-one and one-to-many translation settings.
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
Jul 28, 2021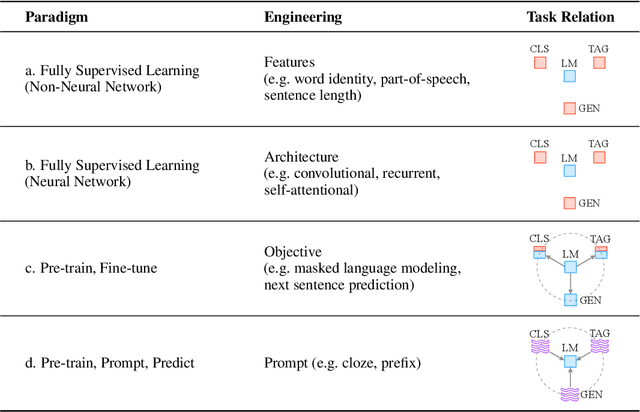
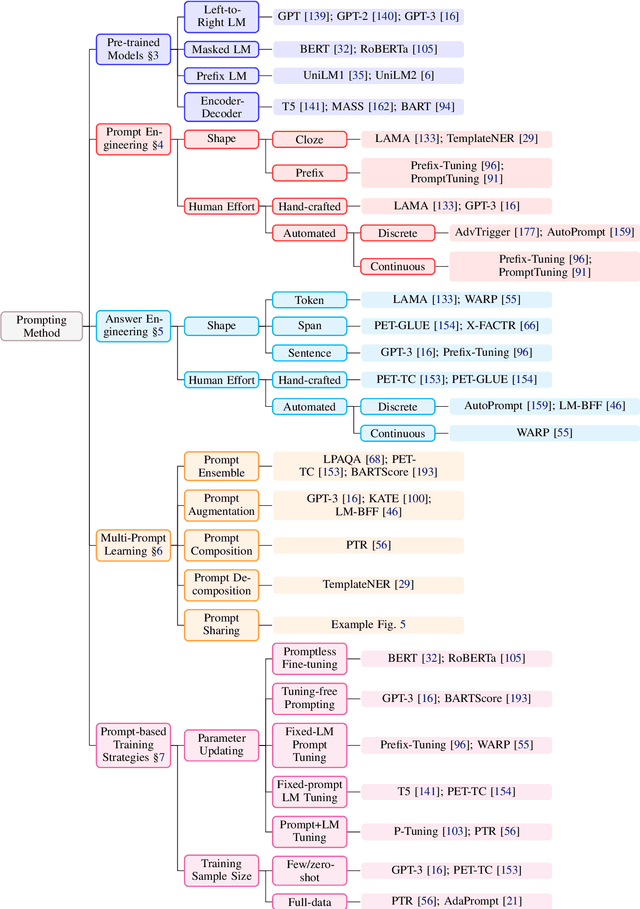
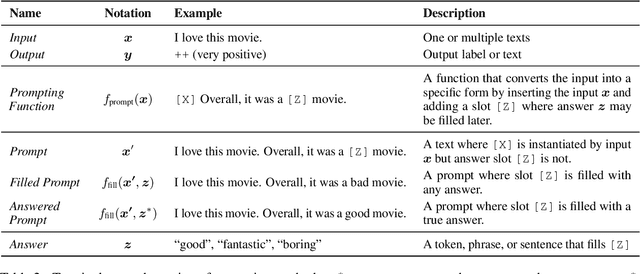
This paper surveys and organizes research works in a new paradigm in natural language processing, which we dub "prompt-based learning". Unlike traditional supervised learning, which trains a model to take in an input x and predict an output y as P(y|x), prompt-based learning is based on language models that model the probability of text directly. To use these models to perform prediction tasks, the original input x is modified using a template into a textual string prompt x' that has some unfilled slots, and then the language model is used to probabilistically fill the unfilled information to obtain a final string x, from which the final output y can be derived. This framework is powerful and attractive for a number of reasons: it allows the language model to be pre-trained on massive amounts of raw text, and by defining a new prompting function the model is able to perform few-shot or even zero-shot learning, adapting to new scenarios with few or no labeled data. In this paper we introduce the basics of this promising paradigm, describe a unified set of mathematical notations that can cover a wide variety of existing work, and organize existing work along several dimensions, e.g.the choice of pre-trained models, prompts, and tuning strategies. To make the field more accessible to interested beginners, we not only make a systematic review of existing works and a highly structured typology of prompt-based concepts, but also release other resources, e.g., a website http://pretrain.nlpedia.ai/ including constantly-updated survey, and paperlist.
Few-shot Language Coordination by Modeling Theory of Mind
Jul 12, 2021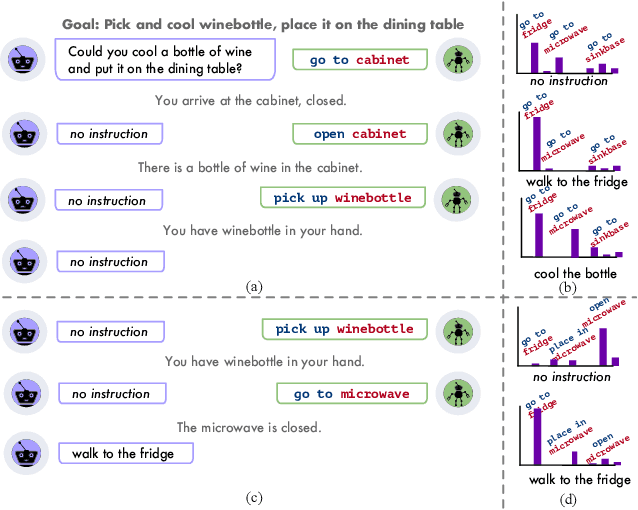
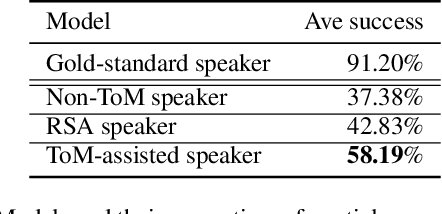
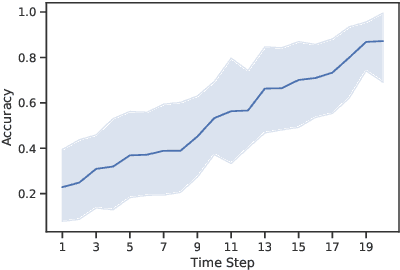
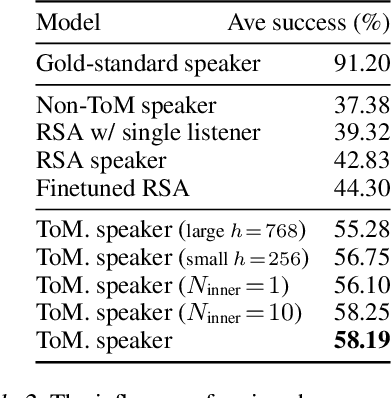
$\textit{No man is an island.}$ Humans communicate with a large community by coordinating with different interlocutors within short conversations. This ability has been understudied by the research on building neural communicative agents. We study the task of few-shot $\textit{language coordination}$: agents quickly adapting to their conversational partners' language abilities. Different from current communicative agents trained with self-play, we require the lead agent to coordinate with a $\textit{population}$ of agents with different linguistic abilities, quickly adapting to communicate with unseen agents in the population. This requires the ability to model the partner's beliefs, a vital component of human communication. Drawing inspiration from theory-of-mind (ToM; Premack& Woodruff (1978)), we study the effect of the speaker explicitly modeling the listeners' mental states. The speakers, as shown in our experiments, acquire the ability to predict the reactions of their partner, which helps it generate instructions that concisely express its communicative goal. We examine our hypothesis that the instructions generated with ToM modeling yield better communication performance in both a referential game and a language navigation task. Positive results from our experiments hint at the importance of explicitly modeling communication as a socio-pragmatic progress.