 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaBERT: Pretraining for Joint Understanding of Textual and Tabular Data
Paper and Code
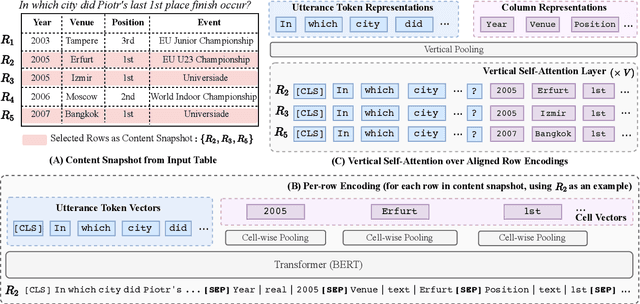
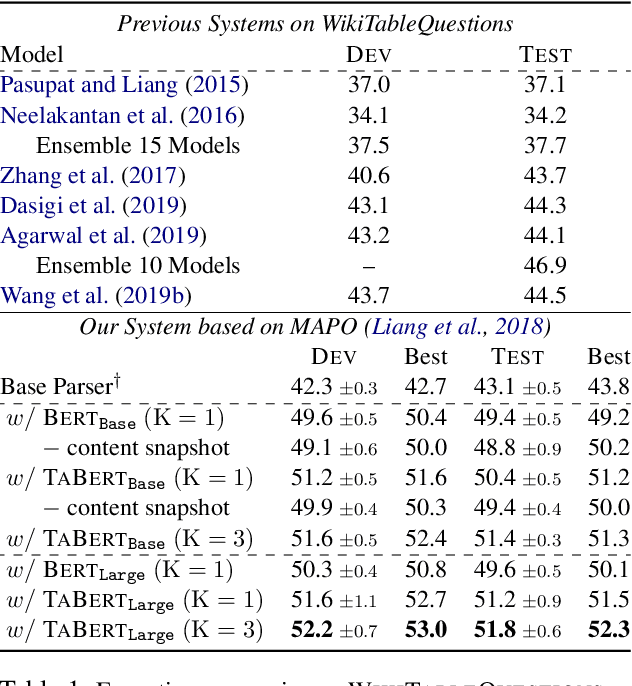
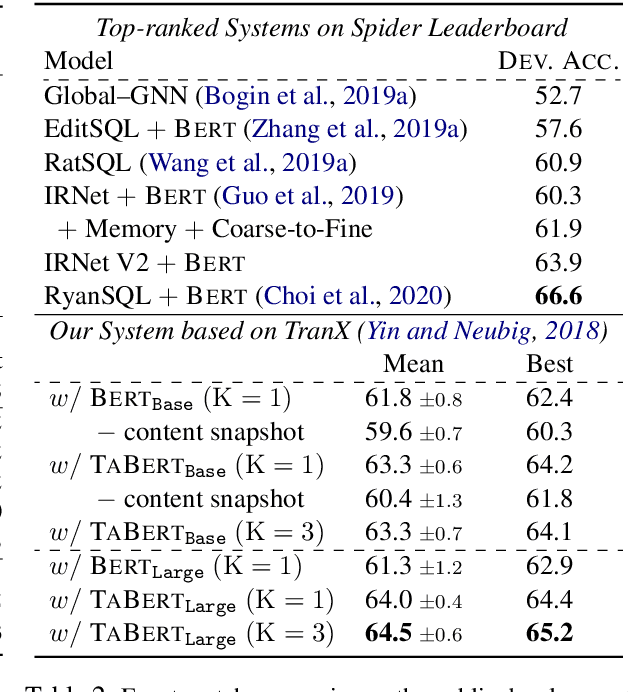
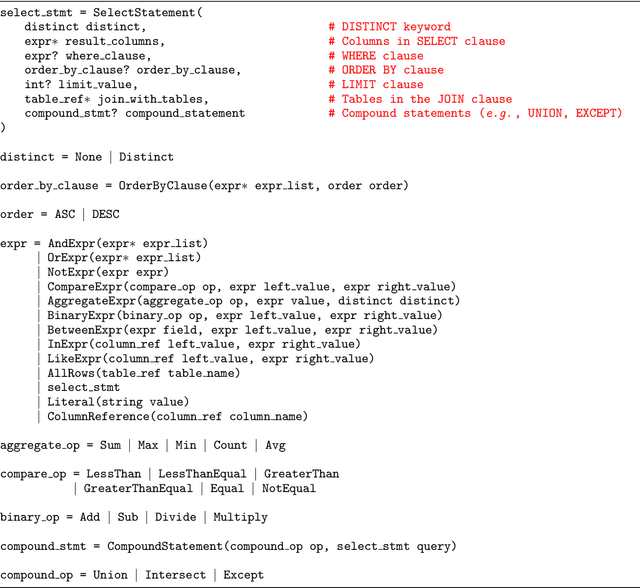
Recent years have witnessed the burgeoning of pretrained language models (LMs) for text-based natural language (NL) understanding tasks. Such models are typically trained on free-form NL text, hence may not be suitable for tasks like semantic parsing over structured data, which require reasoning over both free-form NL questions and structured tabular data (e.g., database tables). In this paper we present TaBERT, a pretrained LM that jointly learns representations for NL sentences and (semi-)structured tables. TaBERT is trained on a large corpus of 26 million tables and their English contexts. In experiments, neural semantic parsers using TaBERT as feature representation layers achieve new best results on the challenging weakly-supervised semantic parsing benchmark WikiTableQuestions, while performing competitively on the text-to-SQL dataset Spider. Implementation of the model will be available at http://fburl.com/TaBERT .