 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Comparable Data Collection for Low-Resource Languages via Images
Paper and Code

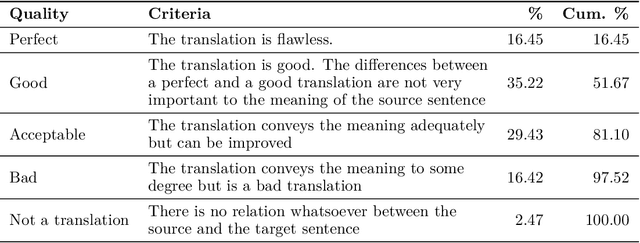

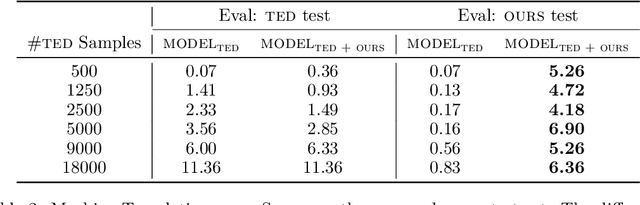
We propose a method of curating high-quality comparable training data for low-resource languages with monolingual annotators. Our method involves using a carefully selected set of images as a pivot between the source and target languages by getting captions for such images in both languages independently. Human evaluations on the English-Hindi comparable corpora created with our method show that 81.1% of the pairs are acceptable translations, and only 2.47% of the pairs are not translations at all. We further establish the potential of the dataset collected through our approach by experimenting on two downstream tasks - machine translation and dictionary extraction. All code and data are available at https://github.com/madaan/PML4DC-Comparable-Data-Collection.