 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Structured Procedural Knowledge Extraction from Cooking Videos
Paper and Code
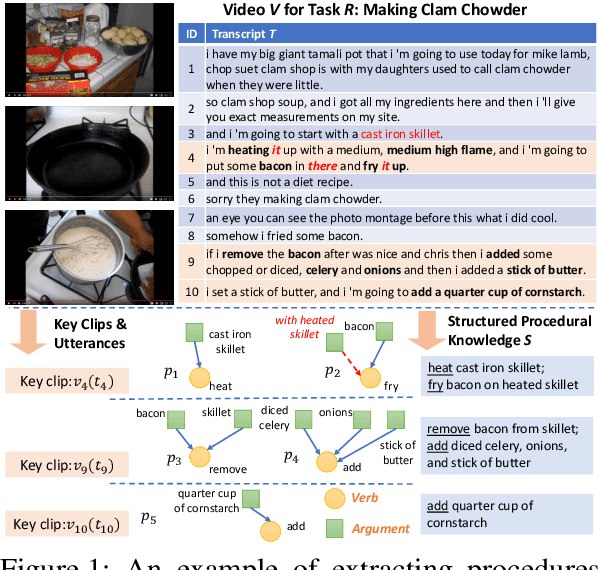
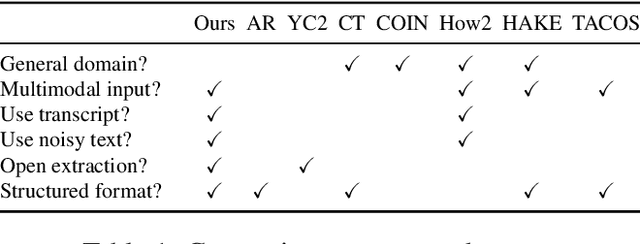
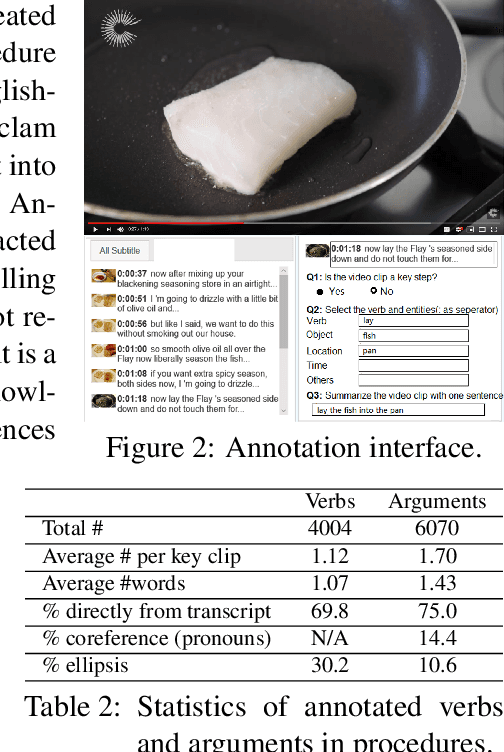

Procedural knowledge, which we define as concrete information about the sequence of actions that go into performing a particular procedure, plays an important role in understanding real-world tasks and actions. Humans often learn this knowledge from instructional text and video, and in this paper we aim to perform automatic extraction of this knowledge in a similar way. As a concrete step in this direction, we propose the new task of inferring procedures in a structured form(a data structure containing verbs and arguments) from multimodal instructional video contents and their corresponding transcripts. We first create a manually annotated, large evaluation dataset including over350 instructional cooking videos along with over 15,000 English sentences in transcripts spanning over 89 recipes. We conduct analysis of the challenges posed by this task and dataset with experiments with unsupervised segmentation, semantic role labeling, and visual action detection based baselines. The dataset and code will be publicly available at https://github.com/frankxu2004/cooking-procedural-extraction.