 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoCoT: Overcoming the Exploration Bottleneck in Reinforcement Learning
Aug 11, 2025Reinforcement learning with verifiable reward (RLVR) has become a promising paradigm for post-training large language models (LLMs) to improve their reasoning capability. However, when the rollout accuracy is low on hard problems, the reward becomes sparse, limiting learning efficiency and causing exploration bottlenecks. Existing approaches either rely on stronger LLMs for distillation or filter out difficult problems, which limits scalability or restricts reasoning improvement through exploration. We propose EvoCoT, a self-evolving curriculum learning framework based on two-stage chain-of-thought (CoT) reasoning optimization. EvoCoT constrains the exploration space by self-generating and verifying CoT trajectories, then gradually shortens them to expand the space in a controlled way. This enables LLMs to stably learn from initially unsolved hard problems under sparse rewards. We apply EvoCoT to multiple LLM families, including Qwen, DeepSeek, and Llama. Experiments show that EvoCoT enables LLMs to solve previously unsolved problems, improves reasoning capability without external CoT supervision, and is compatible with various RL fine-tuning methods. We release the source code to support future research.
RL-PLUS: Countering Capability Boundary Collapse of LLMs in Reinforcement Learning with Hybrid-policy Optimization
Jul 31, 2025Reinforcement Learning with Verifiable Reward (RLVR) has significantly advanced the complex reasoning abilities of Large Language Models (LLMs). However, it struggles to break through the inherent capability boundaries of the base LLM, due to its inherently on-policy strategy with LLM's immense action space and sparse reward. Further, RLVR can lead to the capability boundary collapse, narrowing the LLM's problem-solving scope. To address this problem, we propose RL-PLUS, a novel approach that synergizes internal exploitation (i.e., Thinking) with external data (i.e., Learning) to achieve stronger reasoning capabilities and surpass the boundaries of base models. RL-PLUS integrates two core components: Multiple Importance Sampling to address for distributional mismatch from external data, and an Exploration-Based Advantage Function to guide the model towards high-value, unexplored reasoning paths. We provide both theoretical analysis and extensive experiments to demonstrate the superiority and generalizability of our approach. The results show that RL-PLUS achieves state-of-the-art performance compared with existing RLVR methods on six math reasoning benchmarks and exhibits superior performance on six out-of-distribution reasoning tasks. It also achieves consistent and significant gains across diverse model families, with average relative improvements ranging from 21.1\% to 69.2\%. Moreover, Pass@k curves across multiple benchmarks indicate that RL-PLUS effectively resolves the capability boundary collapse problem.
A Survey on Code Generation with LLM-based Agents
Jul 31, 2025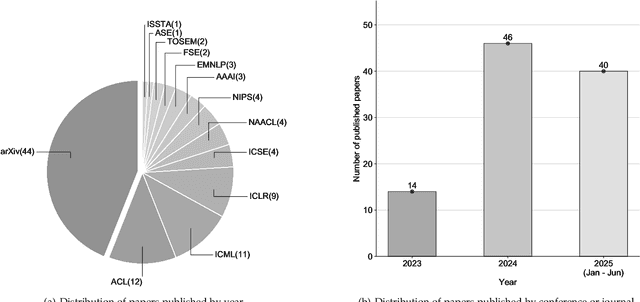
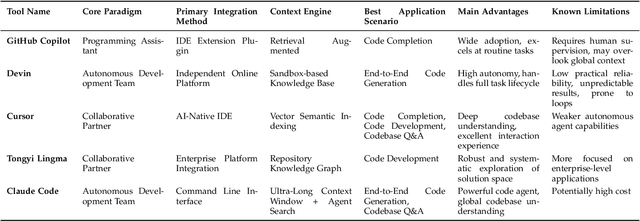
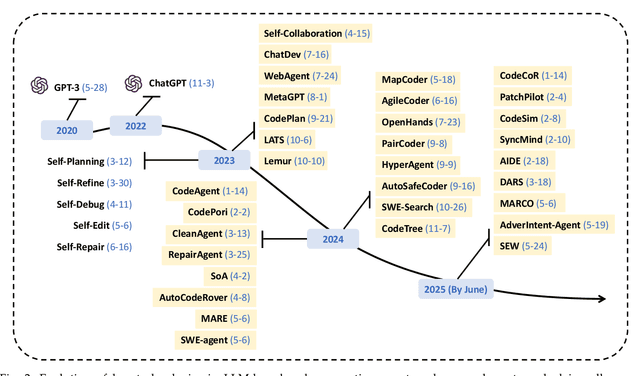
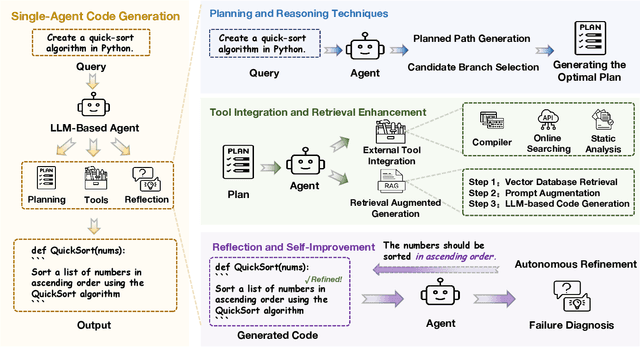
Code generation agents powered by large language models (LLMs) are revolutionizing the software development paradigm. Distinct from previous code generation techniques, code generation agents are characterized by three core features. 1) Autonomy: the ability to independently manage the entire workflow, from task decomposition to coding and debugging. 2) Expanded task scope: capabilities that extend beyond generating code snippets to encompass the full software development lifecycle (SDLC). 3) Enhancement of engineering practicality: a shift in research emphasis from algorithmic innovation toward practical engineering challenges, such as system reliability, process management, and tool integration. This domain has recently witnessed rapid development and an explosion in research, demonstrating significant application potential. This paper presents a systematic survey of the field of LLM-based code generation agents. We trace the technology's developmental trajectory from its inception and systematically categorize its core techniques, including both single-agent and multi-agent architectures. Furthermore, this survey details the applications of LLM-based agents across the full SDLC, summarizes mainstream evaluation benchmarks and metrics, and catalogs representative tools. Finally, by analyzing the primary challenges, we identify and propose several foundational, long-term research directions for the future work of the field.
DAVSP: Safety Alignment for Large Vision-Language Models via Deep Aligned Visual Safety Prompt
Jun 11, 2025Large Vision-Language Models (LVLMs) have achieved impressive progress across various applications but remain vulnerable to malicious queries that exploit the visual modality. Existing alignment approaches typically fail to resist malicious queries while preserving utility on benign ones effectively. To address these challenges, we propose Deep Aligned Visual Safety Prompt (DAVSP), which is built upon two key innovations. First, we introduce the Visual Safety Prompt, which appends a trainable padding region around the input image. It preserves visual features and expands the optimization space. Second, we propose Deep Alignment, a novel approach to train the visual safety prompt through supervision in the model's activation space. It enhances the inherent ability of LVLMs to perceive malicious queries, achieving deeper alignment than prior works. Extensive experiments across five benchmarks on two representative LVLMs demonstrate that DAVSP effectively resists malicious queries while preserving benign input utility. Furthermore, DAVSP exhibits great cross-model generation ability. Ablation studies further reveal that both the Visual Safety Prompt and Deep Alignment are essential components, jointly contributing to its overall effectiveness. The code is publicly available at https://github.com/zhangyitonggg/DAVSP.
BEAST: Efficient Tokenization of B-Splines Encoded Action Sequences for Imitation Learning
Jun 06, 2025We present the B-spline Encoded Action Sequence Tokenizer (BEAST), a novel action tokenizer that encodes action sequences into compact discrete or continuous tokens using B-splines. In contrast to existing action tokenizers based on vector quantization or byte pair encoding, BEAST requires no separate tokenizer training and consistently produces tokens of uniform length, enabling fast action sequence generation via parallel decoding. Leveraging our B-spline formulation, BEAST inherently ensures generating smooth trajectories without discontinuities between adjacent segments. We extensively evaluate BEAST by integrating it with three distinct model architectures: a Variational Autoencoder (VAE) with continuous tokens, a decoder-only Transformer with discrete tokens, and Florence-2, a pretrained Vision-Language Model with an encoder-decoder architecture, demonstrating BEAST's compatibility and scalability with large pretrained models. We evaluate BEAST across three established benchmarks consisting of 166 simulated tasks and on three distinct robot settings with a total of 8 real-world tasks. Experimental results demonstrate that BEAST (i) significantly reduces both training and inference computational costs, and (ii) consistently generates smooth, high-frequency control signals suitable for continuous control tasks while (iii) reliably achieves competitive task success rates compared to state-of-the-art methods.
SATURN: SAT-based Reinforcement Learning to Unleash Language Model Reasoning
May 22, 2025How to design reinforcement learning (RL) tasks that effectively unleash the reasoning capability of large language models (LLMs) remains an open question. Existing RL tasks (e.g., math, programming, and constructing reasoning tasks) suffer from three key limitations: (1) Scalability. They rely heavily on human annotation or expensive LLM synthesis to generate sufficient training data. (2) Verifiability. LLMs' outputs are hard to verify automatically and reliably. (3) Controllable Difficulty. Most tasks lack fine-grained difficulty control, making it hard to train LLMs to develop reasoning ability from easy to hard. To address these limitations, we propose Saturn, a SAT-based RL framework that uses Boolean Satisfiability (SAT) problems to train and evaluate LLM reasoning. Saturn enables scalable task construction, rule-based verification, and precise difficulty control. Saturn designs a curriculum learning pipeline that continuously improves LLMs' reasoning capability by constructing SAT tasks of increasing difficulty and training LLMs from easy to hard. To ensure stable training, we design a principled mechanism to control difficulty transitions. We introduce Saturn-2.6k, a dataset of 2,660 SAT problems with varying difficulty. It supports the evaluation of how LLM reasoning changes with problem difficulty. We apply Saturn to DeepSeek-R1-Distill-Qwen and obtain Saturn-1.5B and Saturn-7B. We achieve several notable results: (1) On SAT problems, Saturn-1.5B and Saturn-7B achieve average pass@3 improvements of +14.0 and +28.1, respectively. (2) On math and programming tasks, Saturn-1.5B and Saturn-7B improve average scores by +4.9 and +1.8 on benchmarks (e.g., AIME, LiveCodeBench). (3) Compared to the state-of-the-art (SOTA) approach in constructing RL tasks, Saturn achieves further improvements of +8.8%. We release the source code, data, and models to support future research.
CoT-Vid: Dynamic Chain-of-Thought Routing with Self Verification for Training-Free Video Reasoning
May 17, 2025



System2 reasoning is developing rapidly these days with the emergence of Deep- Thinking Models and chain-of-thought technology, which has become a centralized discussion point in the AI community. However, there is a relative gap in the research on complex video reasoning at present. In this work, we propose CoT-Vid, a novel training-free paradigm for the video domain with a multistage complex reasoning design. Distinguishing from existing video LLMs, which rely heavily on perceptual abilities, it achieved surprising performance gain with explicit reasoning mechanism. The paradigm consists of three main components: dynamic inference path routing, problem decoupling strategy, and video self-consistency verification. In addition, we propose a new standard for categorization of video questions. CoT- Vid showed outstanding results on a wide range of benchmarks, and outperforms its base model by 9.3% on Egochema and 5.6% on VideoEspresso, rivalling or even surpassing larger and proprietary models, such as GPT-4V, GPT-4o and Gemini-1.5-flash. Our codebase will be publicly available soon.
Rethinking Repetition Problems of LLMs in Code Generation
May 15, 2025With the advent of neural language models, the performance of code generation has been significantly boosted. However, the problem of repetitions during the generation process continues to linger. Previous work has primarily focused on content repetition, which is merely a fraction of the broader repetition problem in code generation. A more prevalent and challenging problem is structural repetition. In structural repetition, the repeated code appears in various patterns but possesses a fixed structure, which can be inherently reflected in grammar. In this paper, we formally define structural repetition and propose an efficient decoding approach called RPG, which stands for Repetition Penalization based on Grammar, to alleviate the repetition problems in code generation for LLMs. Specifically, RPG first leverages grammar rules to identify repetition problems during code generation, and then strategically decays the likelihood of critical tokens that contribute to repetitions, thereby mitigating them in code generation. To facilitate this study, we construct a new dataset CodeRepetEval to comprehensively evaluate approaches for mitigating the repetition problems in code generation. Extensive experimental results demonstrate that RPG substantially outperforms the best-performing baselines on CodeRepetEval dataset as well as HumanEval and MBPP benchmarks, effectively reducing repetitions and enhancing the quality of generated code.
Adaptive Detection of Fast Moving Celestial Objects Using a Mixture of Experts and Physical-Inspired Neural Network
Apr 10, 2025Fast moving celestial objects are characterized by velocities across the celestial sphere that significantly differ from the motions of background stars. In observational images, these objects exhibit distinct shapes, contrasting with the typical appearances of stars. Depending on the observational method employed, these celestial entities may be designated as near-Earth objects or asteroids. Historically, fast moving celestial objects have been observed using ground-based telescopes, where the relative stability of stars and Earth facilitated effective image differencing techniques alongside traditional fast moving celestial object detection and classification algorithms. However, the growing prevalence of space-based telescopes, along with their diverse observational modes, produces images with different properties, rendering conventional methods less effective. This paper presents a novel algorithm for detecting fast moving celestial objects within star fields. Our approach enhances state-of-the-art fast moving celestial object detection neural networks by transforming them into physical-inspired neural networks. These neural networks leverage the point spread function of the telescope and the specific observational mode as prior information; they can directly identify moving fast moving celestial objects within star fields without requiring additional training, thereby addressing the limitations of traditional techniques. Additionally, all neural networks are integrated using the mixture of experts technique, forming a comprehensive fast moving celestial object detection algorithm. We have evaluated our algorithm using simulated observational data that mimics various observations carried out by space based telescope scenarios and real observation images. Results demonstrate that our method effectively detects fast moving celestial objects across different observational modes.
Hierarchical Attention Networks for Lossless Point Cloud Attribute Compression
Apr 01, 2025In this paper, we propose a deep hierarchical attention context model for lossless attribute compression of point clouds, leveraging a multi-resolution spatial structure and residual learning. A simple and effective Level of Detail (LoD) structure is introduced to yield a coarse-to-fine representation. To enhance efficiency, points within the same refinement level are encoded in parallel, sharing a common context point group. By hierarchically aggregating information from neighboring points, our attention model learns contextual dependencies across varying scales and densities, enabling comprehensive feature extraction. We also adopt normalization for position coordinates and attributes to achieve scale-invariant compression. Additionally, we segment the point cloud into multiple slices to facilitate parallel processing, further optimizing time complexity. Experimental results demonstrate that the proposed method offers better coding performance than the latest G-PCC for color and reflectance attributes while maintaining more efficient encoding and decoding runtimes.