 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Formal Reasoning Capabilities of Large Language Models through Chomsky Hierarchy
Apr 03, 2026The formal reasoning capabilities of LLMs are crucial for advancing automated software engineering. However, existing benchmarks for LLMs lack systematic evaluation based on computation and complexity, leaving a critical gap in understanding their formal reasoning capabilities. Therefore, it is still unknown whether SOTA LLMs can grasp the structured, hierarchical complexity of formal languages as defined by Computation Theory. To address this, we introduce ChomskyBench, a benchmark for systematically evaluating LLMs through the lens of Chomsky Hierarchy. Unlike prior work that uses vectorized classification for neural networks, ChomskyBench is the first to combine full Chomsky Hierarchy coverage, process-trace evaluation via natural language, and deterministic symbolic verifiability. ChomskyBench is composed of a comprehensive suite of language recognition and generation tasks designed to test capabilities at each level. Extensive experiments indicate a clear performance stratification that correlates with the hierarchy's levels of complexity. Our analysis reveals a direct relationship where increasing task difficulty substantially impacts both inference length and performance. Furthermore, we find that while larger models and advanced inference methods offer notable relative gains, they face severe efficiency barriers: achieving practical reliability would require prohibitive computational costs, revealing that current limitations stem from inefficiency rather than absolute capability bounds. A time complexity analysis further indicates that LLMs are significantly less efficient than traditional algorithmic programs for these formal tasks. These results delineate the practical limits of current LLMs, highlight the indispensability of traditional software tools, and provide insights to guide the development of future LLMs with more powerful formal reasoning capabilities.
KOCO-BENCH: Can Large Language Models Leverage Domain Knowledge in Software Development?
Jan 19, 2026Large language models (LLMs) excel at general programming but struggle with domain-specific software development, necessitating domain specialization methods for LLMs to learn and utilize domain knowledge and data. However, existing domain-specific code benchmarks cannot evaluate the effectiveness of domain specialization methods, which focus on assessing what knowledge LLMs possess rather than how they acquire and apply new knowledge, lacking explicit knowledge corpora for developing domain specialization methods. To this end, we present KOCO-BENCH, a novel benchmark designed for evaluating domain specialization methods in real-world software development. KOCO-BENCH contains 6 emerging domains with 11 software frameworks and 25 projects, featuring curated knowledge corpora alongside multi-granularity evaluation tasks including domain code generation (from function-level to project-level with rigorous test suites) and domain knowledge understanding (via multiple-choice Q&A). Unlike previous benchmarks that only provide test sets for direct evaluation, KOCO-BENCH requires acquiring and applying diverse domain knowledge (APIs, rules, constraints, etc.) from knowledge corpora to solve evaluation tasks. Our evaluations reveal that KOCO-BENCH poses significant challenges to state-of-the-art LLMs. Even with domain specialization methods (e.g., SFT, RAG, kNN-LM) applied, improvements remain marginal. Best-performing coding agent, Claude Code, achieves only 34.2%, highlighting the urgent need for more effective domain specialization methods. We release KOCO-BENCH, evaluation code, and baselines to advance further research at https://github.com/jiangxxxue/KOCO-bench.
A Survey on Code Generation with LLM-based Agents
Jul 31, 2025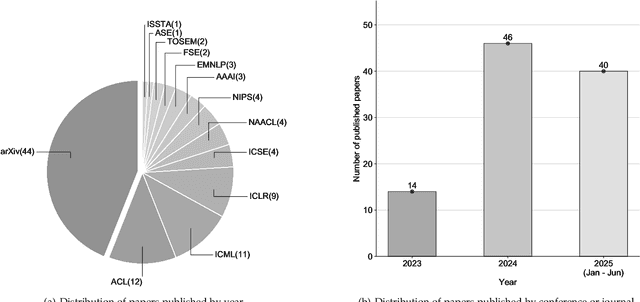
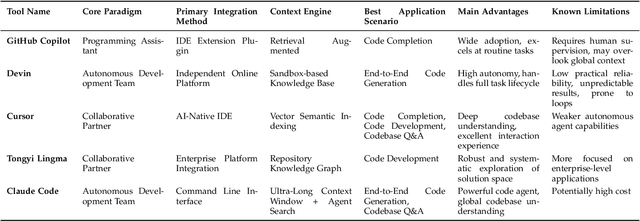
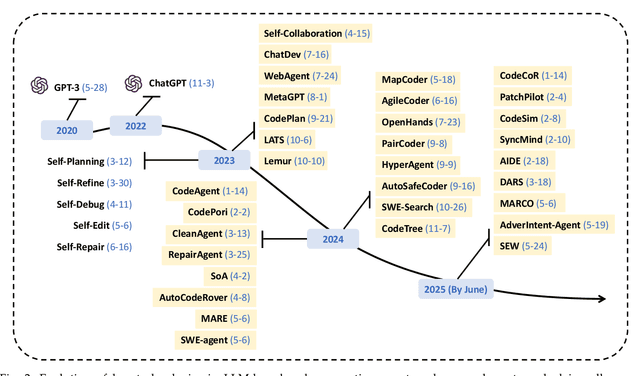
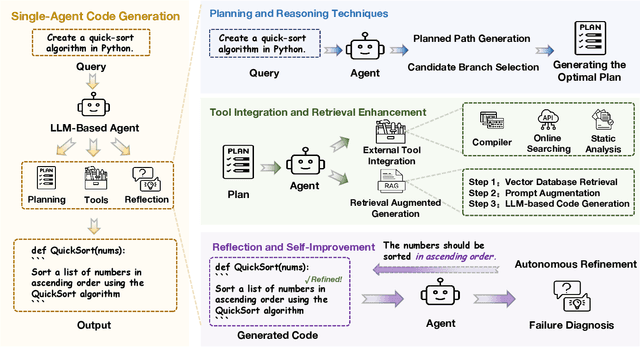
Code generation agents powered by large language models (LLMs) are revolutionizing the software development paradigm. Distinct from previous code generation techniques, code generation agents are characterized by three core features. 1) Autonomy: the ability to independently manage the entire workflow, from task decomposition to coding and debugging. 2) Expanded task scope: capabilities that extend beyond generating code snippets to encompass the full software development lifecycle (SDLC). 3) Enhancement of engineering practicality: a shift in research emphasis from algorithmic innovation toward practical engineering challenges, such as system reliability, process management, and tool integration. This domain has recently witnessed rapid development and an explosion in research, demonstrating significant application potential. This paper presents a systematic survey of the field of LLM-based code generation agents. We trace the technology's developmental trajectory from its inception and systematically categorize its core techniques, including both single-agent and multi-agent architectures. Furthermore, this survey details the applications of LLM-based agents across the full SDLC, summarizes mainstream evaluation benchmarks and metrics, and catalogs representative tools. Finally, by analyzing the primary challenges, we identify and propose several foundational, long-term research directions for the future work of the field.