 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Range-Velocity-Azimuth Estimation for OFDM-Based Integrated Sensing and Communication
Dec 20, 2023



Orthogonal frequency division multiplexing (OFDM)-based integrated sensing and communication (ISAC) is promising for future sixth-generation mobile communication systems. Existing works focus on the joint estimation of the targets' range and velocity for OFDM-based ISAC systems. In contrast, this paper studies the three-dimensional joint estimation (3DJE) of range, velocity, and azimuth for OFDM-based ISAC systems with multiple receive antennas. First, we establish the signal model and derive the Cramer-Rao bounds (CRBs) on the 3DJE. Furthermore, an auto-paired super-resolution 3DJE algorithm is proposed by exploiting the reconstructed observation sub-signal's translational invariance property in the time, frequency, and space domains. Finally, with the 5G New Radio parameter setup, simulation results show that the proposed algorithm achieves better estimation performance and its root mean square error is closer to the root of CRBs than existing methods.
SoftMAC: Differentiable Soft Body Simulation with Forecast-based Contact Model and Two-way Coupling with Articulated Rigid Bodies and Clothes
Dec 06, 2023



Differentiable physics simulation provides an avenue for tackling previously intractable challenges through gradient-based optimization, thereby greatly improving the efficiency of solving robotics-related problems. To apply differentiable simulation in diverse robotic manipulation scenarios, a key challenge is to integrate various materials in a unified framework. We present SoftMAC, a differentiable simulation framework coupling soft bodies with articulated rigid bodies and clothes. SoftMAC simulates soft bodies with the continuum-mechanics-based Material Point Method (MPM). We provide a forecast-based contact model for MPM, which greatly reduces artifacts like penetration and unnatural rebound. To couple MPM particles with deformable and non-volumetric clothes meshes, we also propose a penetration tracing algorithm that reconstructs the signed distance field in local area. Based on simulators for each modality and the contact model, we develop a differentiable coupling mechanism to simulate the interactions between soft bodies and the other two types of materials. Comprehensive experiments are conducted to validate the effectiveness and accuracy of the proposed differentiable pipeline in downstream robotic manipulation applications. Supplementary materials and videos are available on our project website at https://sites.google.com/view/softmac.
Jade: A Differentiable Physics Engine for Articulated Rigid Bodies with Intersection-Free Frictional Contact
Sep 09, 2023



We present Jade, a differentiable physics engine for articulated rigid bodies. Jade models contacts as the Linear Complementarity Problem (LCP). Compared to existing differentiable simulations, Jade offers features including intersection-free collision simulation and stable LCP solutions for multiple frictional contacts. We use continuous collision detection to detect the time of impact and adopt the backtracking strategy to prevent intersection between bodies with complex geometry shapes. We derive the gradient calculation to ensure the whole simulation process is differentiable under the backtracking mechanism. We modify the popular Dantzig algorithm to get valid solutions under multiple frictional contacts. We conduct extensive experiments to demonstrate the effectiveness of our differentiable physics simulation over a variety of contact-rich tasks.
Exploring the Potential of Integrated Optical Sensing and Communication (IOSAC) Systems with Si Waveguides for Future Networks
Jun 27, 2023



Advanced silicon photonic technologies enable integrated optical sensing and communication (IOSAC) in real time for the emerging application requirements of simultaneous sensing and communication for next-generation networks. Here, we propose and demonstrate the IOSAC system on the silicon nitride (SiN) photonics platform. The IOSAC devices based on microring resonators are capable of monitoring the variation of analytes, transmitting the information to the terminal along with the modulated optical signal in real-time, and replacing bulk optics in high-precision and high-speed applications. By directly integrating SiN ring resonators with optical communication networks, simultaneous sensing and optical communication are demonstrated by an optical signal transmission experimental system using especially filtering amplified spontaneous emission spectra. The refractive index (RI) sensing ring with a sensitivity of 172 nm/RIU, a figure of merit (FOM) of 1220, and a detection limit (DL) of 8.2*10-6 RIU is demonstrated. Simultaneously, the 1.25 Gbps optical on-off-keying (OOK) signal is transmitted at the concentration of different NaCl solutions, which indicates the bit-error-ratio (BER) decreases with the increase in concentration. The novel IOSAC technology shows the potential to realize high-performance simultaneous biosensing and communication in real time and further accelerate the development of IoT and 6G networks.
HIDFlowNet: A Flow-Based Deep Network for Hyperspectral Image Denoising
Jun 20, 2023



Hyperspectral image (HSI) denoising is essentially ill-posed since a noisy HSI can be degraded from multiple clean HSIs. However, current deep learning-based approaches ignore this fact and restore the clean image with deterministic mapping (i.e., the network receives a noisy HSI and outputs a clean HSI). To alleviate this issue, this paper proposes a flow-based HSI denoising network (HIDFlowNet) to directly learn the conditional distribution of the clean HSI given the noisy HSI and thus diverse clean HSIs can be sampled from the conditional distribution. Overall, our HIDFlowNet is induced from the flow methodology and contains an invertible decoder and a conditional encoder, which can fully decouple the learning of low-frequency and high-frequency information of HSI. Specifically, the invertible decoder is built by staking a succession of invertible conditional blocks (ICBs) to capture the local high-frequency details since the invertible network is information-lossless. The conditional encoder utilizes down-sampling operations to obtain low-resolution images and uses transformers to capture correlations over a long distance so that global low-frequency information can be effectively extracted. Extensive experimental results on simulated and real HSI datasets verify the superiority of our proposed HIDFlowNet compared with other state-of-the-art methods both quantitatively and visually.
PanFlowNet: A Flow-Based Deep Network for Pan-sharpening
May 16, 2023Pan-sharpening aims to generate a high-resolution multispectral (HRMS) image by integrating the spectral information of a low-resolution multispectral (LRMS) image with the texture details of a high-resolution panchromatic (PAN) image. It essentially inherits the ill-posed nature of the super-resolution (SR) task that diverse HRMS images can degrade into an LRMS image. However, existing deep learning-based methods recover only one HRMS image from the LRMS image and PAN image using a deterministic mapping, thus ignoring the diversity of the HRMS image. In this paper, to alleviate this ill-posed issue, we propose a flow-based pan-sharpening network (PanFlowNet) to directly learn the conditional distribution of HRMS image given LRMS image and PAN image instead of learning a deterministic mapping. Specifically, we first transform this unknown conditional distribution into a given Gaussian distribution by an invertible network, and the conditional distribution can thus be explicitly defined. Then, we design an invertible Conditional Affine Coupling Block (CACB) and further build the architecture of PanFlowNet by stacking a series of CACBs. Finally, the PanFlowNet is trained by maximizing the log-likelihood of the conditional distribution given a training set and can then be used to predict diverse HRMS images. The experimental results verify that the proposed PanFlowNet can generate various HRMS images given an LRMS image and a PAN image. Additionally, the experimental results on different kinds of satellite datasets also demonstrate the superiority of our PanFlowNet compared with other state-of-the-art methods both visually and quantitatively.
Segmentation-based Information Extraction and Amalgamation in Fundus Images for Glaucoma Detection
Sep 23, 2022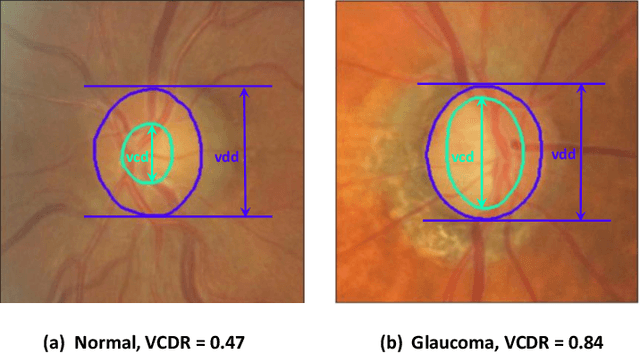

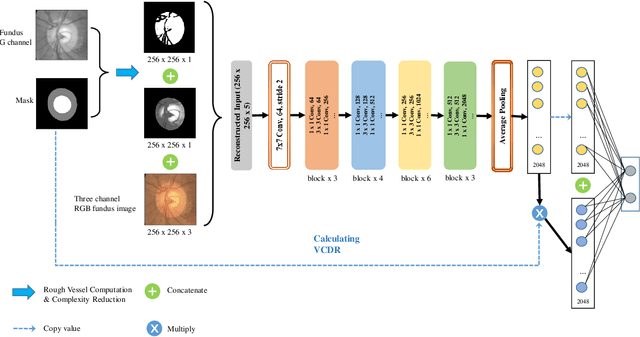

Glaucoma is a severe blinding disease, for which automatic detection methods are urgently needed to alleviate the scarcity of ophthalmologists. Many works have proposed to employ deep learning methods that involve the segmentation of optic disc and cup for glaucoma detection, in which the segmentation process is often considered merely as an upstream sub-task. The relationship between fundus images and segmentation masks in terms of joint decision-making in glaucoma assessment is rarely explored. We propose a novel segmentation-based information extraction and amalgamation method for the task of glaucoma detection, which leverages the robustness of segmentation masks without disregarding the rich information in the original fundus images. Experimental results on both private and public datasets demonstrate that our proposed method outperforms all models that utilize solely either fundus images or masks.
Model-Guided Multi-Contrast Deep Unfolding Network for MRI Super-resolution Reconstruction
Sep 15, 2022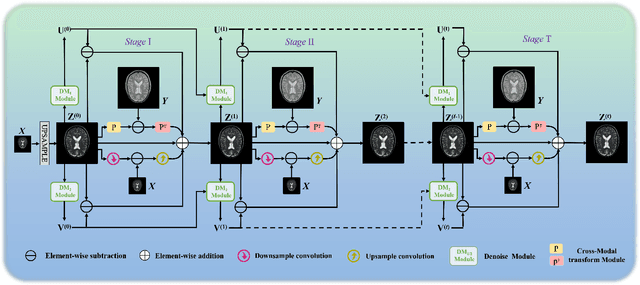
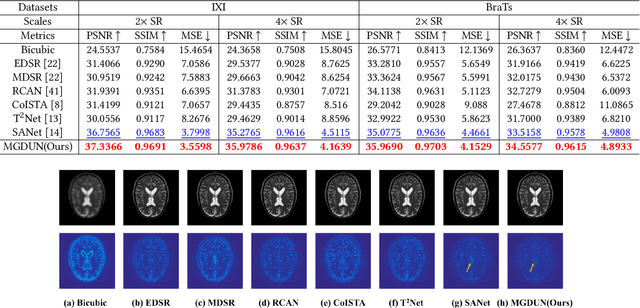
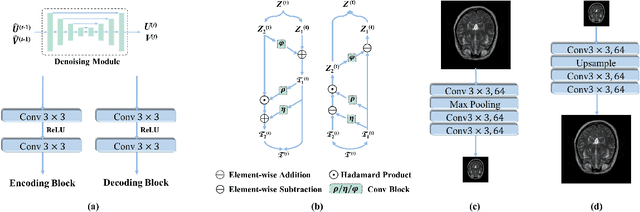
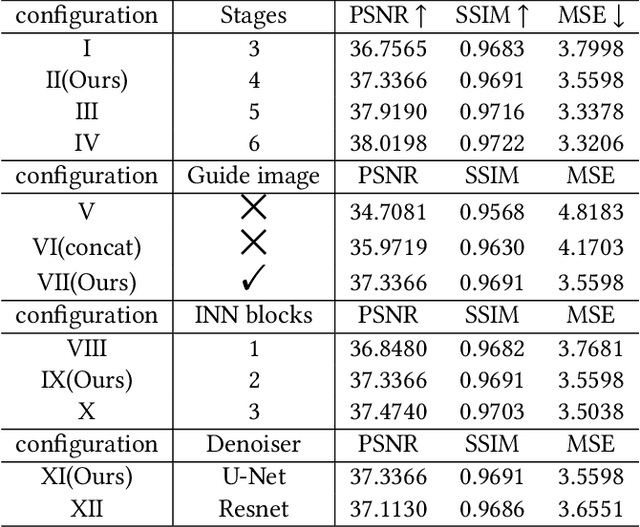
Magnetic resonance imaging (MRI) with high resolution (HR) provides more detailed information for accurate diagnosis and quantitative image analysis. Despite the significant advances, most existing super-resolution (SR) reconstruction network for medical images has two flaws: 1) All of them are designed in a black-box principle, thus lacking sufficient interpretability and further limiting their practical applications. Interpretable neural network models are of significant interest since they enhance the trustworthiness required in clinical practice when dealing with medical images. 2) most existing SR reconstruction approaches only use a single contrast or use a simple multi-contrast fusion mechanism, neglecting the complex relationships between different contrasts that are critical for SR improvement. To deal with these issues, in this paper, a novel Model-Guided interpretable Deep Unfolding Network (MGDUN) for medical image SR reconstruction is proposed. The Model-Guided image SR reconstruction approach solves manually designed objective functions to reconstruct HR MRI. We show how to unfold an iterative MGDUN algorithm into a novel model-guided deep unfolding network by taking the MRI observation matrix and explicit multi-contrast relationship matrix into account during the end-to-end optimization. Extensive experiments on the multi-contrast IXI dataset and BraTs 2019 dataset demonstrate the superiority of our proposed model.
TANet: Transformer-based Asymmetric Network for RGB-D Salient Object Detection
Jul 04, 2022



Existing RGB-D SOD methods mainly rely on a symmetric two-stream CNN-based network to extract RGB and depth channel features separately. However, there are two problems with the symmetric conventional network structure: first, the ability of CNN in learning global contexts is limited; second, the symmetric two-stream structure ignores the inherent differences between modalities. In this paper, we propose a Transformer-based asymmetric network (TANet) to tackle the issues mentioned above. We employ the powerful feature extraction capability of Transformer (PVTv2) to extract global semantic information from RGB data and design a lightweight CNN backbone (LWDepthNet) to extract spatial structure information from depth data without pre-training. The asymmetric hybrid encoder (AHE) effectively reduces the number of parameters in the model while increasing speed without sacrificing performance. Then, we design a cross-modal feature fusion module (CMFFM), which enhances and fuses RGB and depth features with each other. Finally, we add edge prediction as an auxiliary task and propose an edge enhancement module (EEM) to generate sharper contours. Extensive experiments demonstrate that our method achieves superior performance over 14 state-of-the-art RGB-D methods on six public datasets. Our code will be released at https://github.com/lc012463/TANet.
Highly accelerated MR parametric mapping by undersampling the k-space and reducing the contrast number simultaneously with deep learning
Dec 01, 2021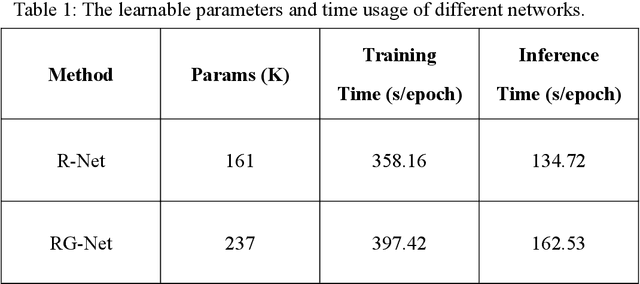
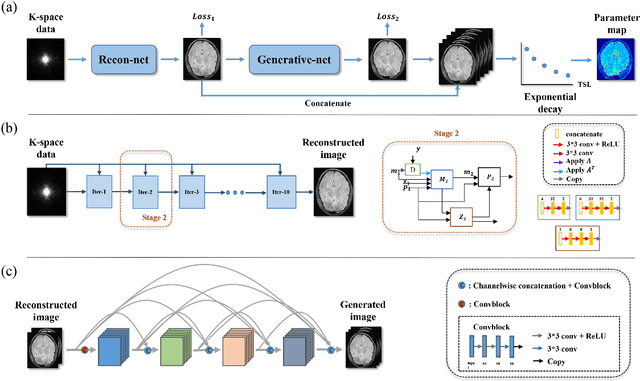
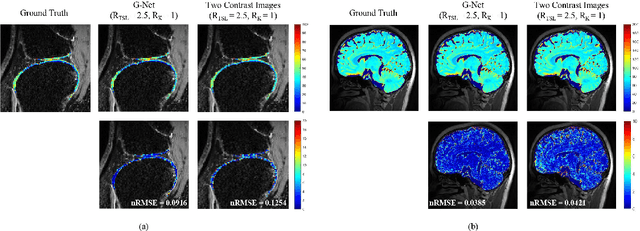
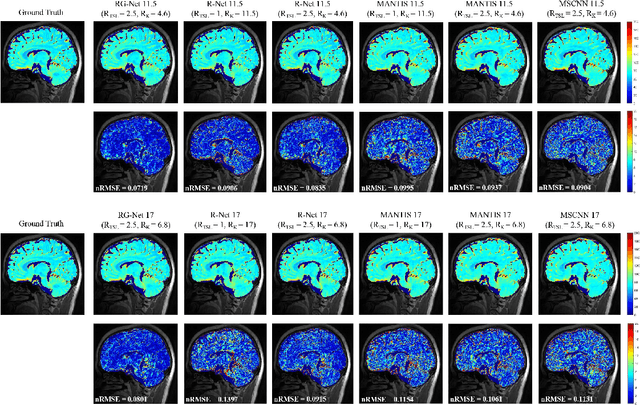
Purpose: To propose a novel deep learning-based method called RG-Net (reconstruction and generation network) for highly accelerated MR parametric mapping by undersampling k-space and reducing the acquired contrast number simultaneously. Methods: The proposed framework consists of a reconstruction module and a generative module. The reconstruction module reconstructs MR images from the acquired few undersampled k-space data with the help of a data prior. The generative module then synthesizes the remaining multi-contrast images from the reconstructed images, where the exponential model is implicitly incorporated into the image generation through the supervision of fully sampled labels. The RG-Net was evaluated on the T1\r{ho} mapping data of knee and brain at different acceleration rates. Regional T1\r{ho} analysis for cartilage and the brain was performed to access the performance of RG-Net. Results: RG-Net yields a high-quality T1\r{ho} map at a high acceleration rate of 17. Compared with the competing methods that only undersample k-space, our framework achieves better performance in T1\r{ho} value analysis. Our method also improves quality of T1\r{ho} maps on patient with glioma. Conclusion: The proposed RG-Net that adopted a new strategy by undersampling k-space and reducing the contrast number simultaneously for fast MR parametric mapping, can achieve a high acceleration rate while maintaining good reconstruction quality. The generative module of our framework can also be used as an insert module in other fast MR parametric mapping methods. Keywords: Deep learning, convolutional neural network, fast MR parametric mapping