 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmplifying Prominent Representations in Multimodal Learning via Variational Dirichlet Process
Oct 23, 2025Developing effective multimodal fusion approaches has become increasingly essential in many real-world scenarios, such as health care and finance. The key challenge is how to preserve the feature expressiveness in each modality while learning cross-modal interactions. Previous approaches primarily focus on the cross-modal alignment, while over-emphasis on the alignment of marginal distributions of modalities may impose excess regularization and obstruct meaningful representations within each modality. The Dirichlet process (DP) mixture model is a powerful Bayesian non-parametric method that can amplify the most prominent features by its richer-gets-richer property, which allocates increasing weights to them. Inspired by this unique characteristic of DP, we propose a new DP-driven multimodal learning framework that automatically achieves an optimal balance between prominent intra-modal representation learning and cross-modal alignment. Specifically, we assume that each modality follows a mixture of multivariate Gaussian distributions and further adopt DP to calculate the mixture weights for all the components. This paradigm allows DP to dynamically allocate the contributions of features and select the most prominent ones, leveraging its richer-gets-richer property, thus facilitating multimodal feature fusion. Extensive experiments on several multimodal datasets demonstrate the superior performance of our model over other competitors. Ablation analysis further validates the effectiveness of DP in aligning modality distributions and its robustness to changes in key hyperparameters. Code is anonymously available at https://github.com/HKU-MedAI/DPMM.git
CapRL: Stimulating Dense Image Caption Capabilities via Reinforcement Learning
Sep 26, 2025Image captioning is a fundamental task that bridges the visual and linguistic domains, playing a critical role in pre-training Large Vision-Language Models (LVLMs). Current state-of-the-art captioning models are typically trained with Supervised Fine-Tuning (SFT), a paradigm that relies on expensive, non-scalable data annotated by humans or proprietary models. This approach often leads to models that memorize specific ground-truth answers, limiting their generality and ability to generate diverse, creative descriptions. To overcome the limitation of SFT, we propose applying the Reinforcement Learning with Verifiable Rewards (RLVR) paradigm to the open-ended task of image captioning. A primary challenge, however, is designing an objective reward function for the inherently subjective nature of what constitutes a "good" caption. We introduce Captioning Reinforcement Learning (CapRL), a novel training framework that redefines caption quality through its utility: a high-quality caption should enable a non-visual language model to accurately answer questions about the corresponding image. CapRL employs a decoupled two-stage pipeline where an LVLM generates a caption, and the objective reward is derived from the accuracy of a separate, vision-free LLM answering Multiple-Choice Questions based solely on that caption. As the first study to apply RLVR to the subjective image captioning task, we demonstrate that CapRL significantly enhances multiple settings. Pretraining on the CapRL-5M caption dataset annotated by CapRL-3B results in substantial gains across 12 benchmarks. Moreover, within the Prism Framework for caption quality evaluation, CapRL achieves performance comparable to Qwen2.5-VL-72B, while exceeding the baseline by an average margin of 8.4%. Code is available here: https://github.com/InternLM/CapRL.
In-Loop Filtering Using Learned Look-Up Tables for Video Coding
Sep 11, 2025In-loop filtering (ILF) is a key technology in video coding standards to reduce artifacts and enhance visual quality. Recently, neural network-based ILF schemes have achieved remarkable coding gains, emerging as a powerful candidate for next-generation video coding standards. However, the use of deep neural networks (DNN) brings significant computational and time complexity or high demands for dedicated hardware, making it challenging for general use. To address this limitation, we study a practical ILF solution by adopting look-up tables (LUTs). After training a DNN with a restricted reference range for ILF, all possible inputs are traversed, and the output values of the DNN are cached into LUTs. During the coding process, the filtering process is performed by simply retrieving the filtered pixel through locating the input pixels and interpolating between the cached values, instead of relying on heavy inference computations. In this paper, we propose a universal LUT-based ILF framework, termed LUT-ILF++. First, we introduce the cooperation of multiple kinds of filtering LUTs and propose a series of customized indexing mechanisms to enable better filtering reference perception with limited storage consumption. Second, we propose the cross-component indexing mechanism to enable the filtering of different color components jointly. Third, in order to make our solution practical for coding uses, we propose the LUT compaction scheme to enable the LUT pruning, achieving a lower storage cost of the entire solution. The proposed framework is implemented in the VVC reference software. Experimental results show that the proposed framework achieves on average 0.82%/2.97%/1.63% and 0.85%/4.11%/2.06% bitrate reduction for common test sequences, under the AI and RA configurations, respectively. Compared to DNN-based solutions, our proposed solution has much lower time complexity and storage cost.
Scaling Learned Image Compression Models up to 1 Billion
Aug 12, 2025Recent advances in large language models (LLMs) highlight a strong connection between intelligence and compression. Learned image compression, a fundamental task in modern data compression, has made significant progress in recent years. However, current models remain limited in scale, restricting their representation capacity, and how scaling model size influences compression performance remains unexplored. In this work, we present a pioneering study on scaling up learned image compression models and revealing the performance trends through scaling laws. Using the recent state-of-the-art HPCM model as baseline, we scale model parameters from 68.5 millions to 1 billion and fit power-law relations between test loss and key scaling variables, including model size and optimal training compute. The results reveal a scaling trend, enabling extrapolation to larger scale models. Experimental results demonstrate that the scaled-up HPCM-1B model achieves state-of-the-art rate-distortion performance. We hope this work inspires future exploration of large-scale compression models and deeper investigations into the connection between compression and intelligence.
Alleviating User-Sensitive bias with Fair Generative Sequential Recommendation Model
Jun 24, 2025Recommendation fairness has recently attracted much attention. In the real world, recommendation systems are driven by user behavior, and since users with the same sensitive feature (e.g., gender and age) tend to have the same patterns, recommendation models can easily capture the strong correlation preference of sensitive features and thus cause recommendation unfairness. Diffusion model (DM) as a new generative model paradigm has achieved great success in recommendation systems. DM's ability to model uncertainty and represent diversity, and its modeling mechanism has a high degree of adaptability with the real-world recommendation process with bias. Therefore, we use DM to effectively model the fairness of recommendation and enhance the diversity. This paper proposes a FairGENerative sequential Recommendation model based on DM, FairGENRec. In the training phase, we inject random noise into the original distribution under the guidance of the sensitive feature recognition model, and a sequential denoise model is designed for the reverse reconstruction of items. Simultaneously, recommendation fairness modeling is completed by injecting multi-interests representational information that eliminates the bias of sensitive user features into the generated results. In the inference phase, the model obtains the noise in the form of noise addition by using the history interactions which is followed by reverse iteration to reconstruct the target item representation. Finally, our extensive experiments on three datasets demonstrate the dual enhancement effect of FairGENRec on accuracy and fairness, while the statistical analysis of the cases visualizes the degree of improvement on the fairness of the recommendation.
ScaleCap: Inference-Time Scalable Image Captioning via Dual-Modality Debiasing
Jun 24, 2025
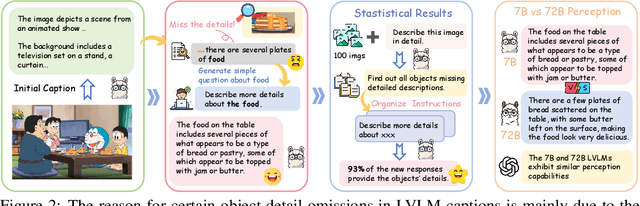

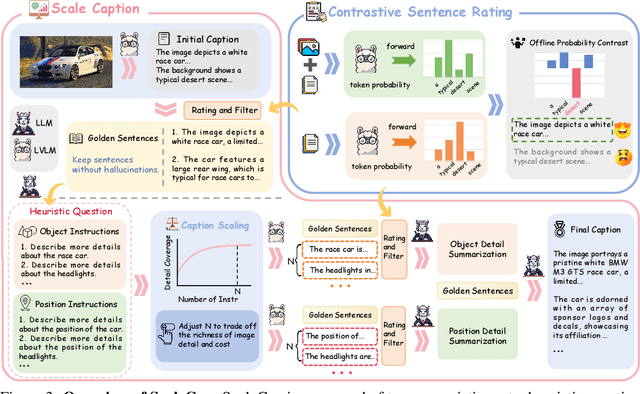
This paper presents ScaleCap, an inference-time scalable image captioning strategy that generates comprehensive and detailed image captions. The key challenges of high-quality image captioning lie in the inherent biases of LVLMs: multimodal bias resulting in imbalanced descriptive granularity, offering detailed accounts of some elements while merely skimming over others; linguistic bias leading to hallucinated descriptions of non-existent objects. To address these issues, we propose a scalable debiased captioning strategy, which continuously enriches and calibrates the caption with increased inference budget. Specifically, we propose two novel components: heuristic question answering and contrastive sentence rating. The former generates content-specific questions based on the image and answers them to progressively inject relevant information into the caption. The latter employs sentence-level offline contrastive decoding to effectively identify and eliminate hallucinations caused by linguistic biases. With increased inference cost, more heuristic questions are raised by ScaleCap to progressively capture additional visual details, generating captions that are more accurate, balanced, and informative. Extensive modality alignment experiments demonstrate the effectiveness of ScaleCap. Annotating 450K images with ScaleCap and using them for LVLM pretraining leads to consistent performance gains across 11 widely used benchmarks. Furthermore, ScaleCap showcases superb richness and fidelity of generated captions with two additional tasks: replacing images with captions in VQA task, and reconstructing images from captions to assess semantic coverage. Code is available at https://github.com/Cooperx521/ScaleCap.
Booster Gym: An End-to-End Reinforcement Learning Framework for Humanoid Robot Locomotion
Jun 18, 2025Recent advancements in reinforcement learning (RL) have led to significant progress in humanoid robot locomotion, simplifying the design and training of motion policies in simulation. However, the numerous implementation details make transferring these policies to real-world robots a challenging task. To address this, we have developed a comprehensive code framework that covers the entire process from training to deployment, incorporating common RL training methods, domain randomization, reward function design, and solutions for handling parallel structures. This library is made available as a community resource, with detailed descriptions of its design and experimental results. We validate the framework on the Booster T1 robot, demonstrating that the trained policies seamlessly transfer to the physical platform, enabling capabilities such as omnidirectional walking, disturbance resistance, and terrain adaptability. We hope this work provides a convenient tool for the robotics community, accelerating the development of humanoid robots. The code can be found in https://github.com/BoosterRobotics/booster_gym.
Cross-architecture universal feature coding via distribution alignment
Jun 15, 2025Feature coding has become increasingly important in scenarios where semantic representations rather than raw pixels are transmitted and stored. However, most existing methods are architecture-specific, targeting either CNNs or Transformers. This design limits their applicability in real-world scenarios where features from both architectures coexist. To address this gap, we introduce a new research problem: cross-architecture universal feature coding (CAUFC), which seeks to build a unified codec that can effectively compress features from heterogeneous architectures. To tackle this challenge, we propose a two-step distribution alignment method. First, we design the format alignment method that unifies CNN and Transformer features into a consistent 2D token format. Second, we propose the feature value alignment method that harmonizes statistical distributions via truncation and normalization. As a first attempt to study CAUFC, we evaluate our method on the image classification task. Experimental results demonstrate that our method achieves superior rate-accuracy trade-offs compared to the architecture-specific baseline. This work marks an initial step toward universal feature compression across heterogeneous model architectures.
CodeBrain: Bridging Decoupled Tokenizer and Multi-Scale Architecture for EEG Foundation Model
Jun 10, 2025



Electroencephalography (EEG) provides real-time insights into brain activity and is widely used in neuroscience. However, variations in channel configurations, sequence lengths, and task objectives limit the transferability of traditional task-specific models. Although recent EEG foundation models (EFMs) aim to learn generalizable representations, they struggle with limited heterogeneous representation capacity and inefficiency in capturing multi-scale brain dependencies. To address these challenges, we propose CodeBrain, an efficient EFM structurally aligned with brain organization, trained in two stages. (1) We introduce a TFDual-Tokenizer that independently tokenizes heterogeneous temporal and frequency components, enabling a quadratic expansion of the discrete representation space. This also offers a degree of interpretability through cross-domain token analysis. (2) We propose the EEGSSM, which combines a structured global convolution architecture and a sliding window attention mechanism to jointly model sparse long-range and local dependencies. Unlike fully connected Transformer models, EEGSSM better reflects the brain's small-world topology and efficiently captures EEG's inherent multi-scale structure. EEGSSM is trained with a masked self-supervised learning objective to predict token indices obtained in TFDual-Tokenizer. Comprehensive experiments on 10 public EEG datasets demonstrate the generalizability of CodeBrain with linear probing. By offering biologically informed and interpretable EEG modeling, CodeBrain lays the foundation for future neuroscience research. Both code and pretraining weights will be released in the future version.
HyperTree Planning: Enhancing LLM Reasoning via Hierarchical Thinking
May 05, 2025Recent advancements have significantly enhanced the performance of large language models (LLMs) in tackling complex reasoning tasks, achieving notable success in domains like mathematical and logical reasoning. However, these methods encounter challenges with complex planning tasks, primarily due to extended reasoning steps, diverse constraints, and the challenge of handling multiple distinct sub-tasks. To address these challenges, we propose HyperTree Planning (HTP), a novel reasoning paradigm that constructs hypertree-structured planning outlines for effective planning. The hypertree structure enables LLMs to engage in hierarchical thinking by flexibly employing the divide-and-conquer strategy, effectively breaking down intricate reasoning steps, accommodating diverse constraints, and managing multiple distinct sub-tasks in a well-organized manner. We further introduce an autonomous planning framework that completes the planning process by iteratively refining and expanding the hypertree-structured planning outlines. Experiments demonstrate the effectiveness of HTP, achieving state-of-the-art accuracy on the TravelPlanner benchmark with Gemini-1.5-Pro, resulting in a 3.6 times performance improvement over o1-preview.