 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based Machine Learning for Fast SAT Solvers and Logic Synthesis
Jul 15, 2021
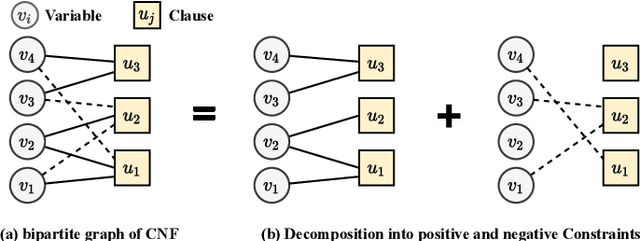
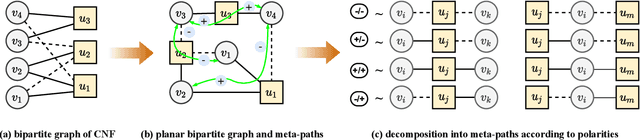
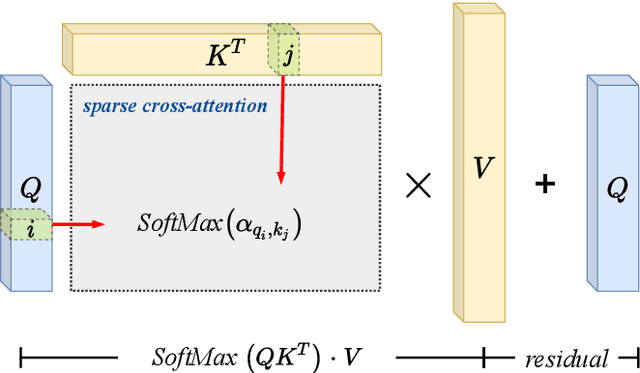
CNF-based SAT and MaxSAT solvers are central to logic synthesis and verification systems. The increasing popularity of these constraint problems in electronic design automation encourages studies on different SAT problems and their properties for further computational efficiency. There has been both theoretical and practical success of modern Conflict-driven clause learning SAT solvers, which allows solving very large industrial instances in a relatively short amount of time. Recently, machine learning approaches provide a new dimension to solving this challenging problem. Neural symbolic models could serve as generic solvers that can be specialized for specific domains based on data without any changes to the structure of the model. In this work, we propose a one-shot model derived from the Transformer architecture to solve the MaxSAT problem, which is the optimization version of SAT where the goal is to satisfy the maximum number of clauses. Our model has a scale-free structure which could process varying size of instances. We use meta-path and self-attention mechanism to capture interactions among homogeneous nodes. We adopt cross-attention mechanisms on the bipartite graph to capture interactions among heterogeneous nodes. We further apply an iterative algorithm to our model to satisfy additional clauses, enabling a solution approaching that of an exact-SAT problem. The attention mechanisms leverage the parallelism for speedup. Our evaluation indicates improved speedup compared to heuristic approaches and improved completion rate compared to machine learning approaches.
STAR: Sparse Transformer-based Action Recognition
Jul 15, 2021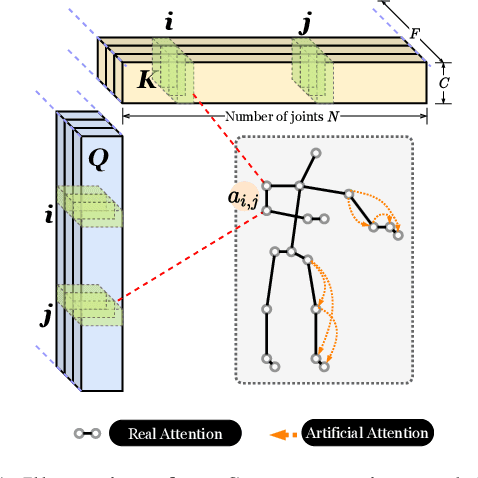
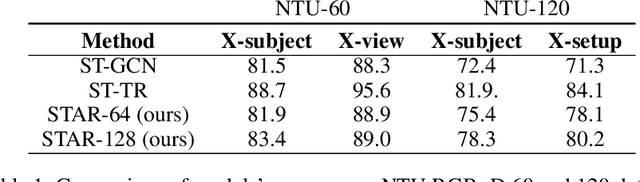
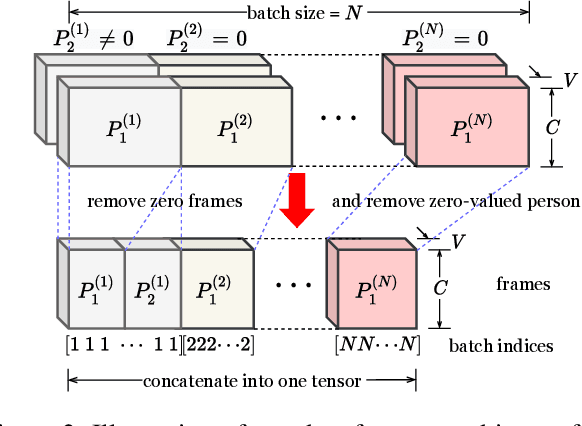
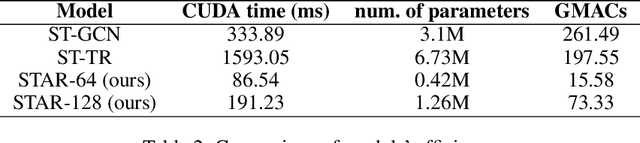
The cognitive system for human action and behavior has evolved into a deep learning regime, and especially the advent of Graph Convolution Networks has transformed the field in recent years. However, previous works have mainly focused on over-parameterized and complex models based on dense graph convolution networks, resulting in low efficiency in training and inference. Meanwhile, the Transformer architecture-based model has not yet been well explored for cognitive application in human action and behavior estimation. This work proposes a novel skeleton-based human action recognition model with sparse attention on the spatial dimension and segmented linear attention on the temporal dimension of data. Our model can also process the variable length of video clips grouped as a single batch. Experiments show that our model can achieve comparable performance while utilizing much less trainable parameters and achieve high speed in training and inference. Experiments show that our model achieves 4~18x speedup and 1/7~1/15 model size compared with the baseline models at competitive accuracy.
VersaGNN: a Versatile accelerator for Graph neural networks
May 04, 2021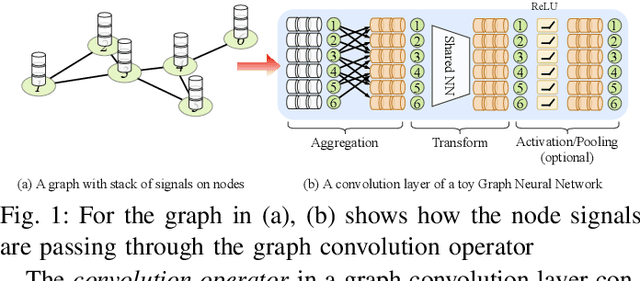
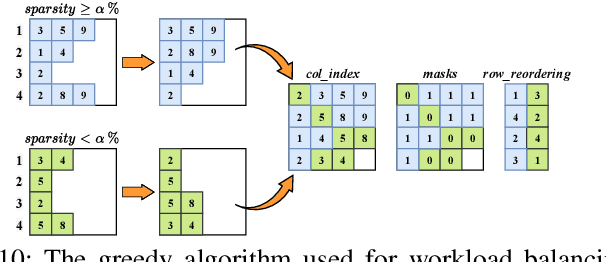
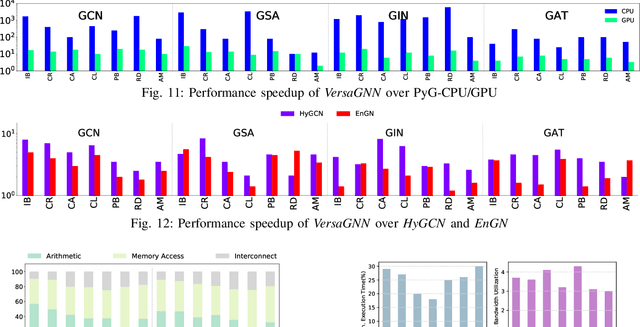
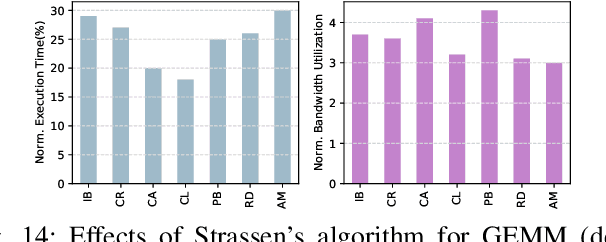
\textit{Graph Neural Network} (GNN) is a promising approach for analyzing graph-structured data that tactfully captures their dependency information via node-level message passing. It has achieved state-of-the-art performances in many tasks, such as node classification, graph matching, clustering, and graph generation. As GNNs operate on non-Euclidean data, their irregular data access patterns cause considerable computational costs and overhead on conventional architectures, such as GPU and CPU. Our analysis shows that GNN adopts a hybrid computing model. The \textit{Aggregation} (or \textit{Message Passing}) phase performs vector additions where vectors are fetched with irregular strides. The \textit{Transformation} (or \textit{Node Embedding}) phase can be either dense or sparse-dense matrix multiplication. In this work, We propose \textit{VersaGNN}, an ultra-efficient, systolic-array-based versatile hardware accelerator that unifies dense and sparse matrix multiplication. By applying this single optimized systolic array to both aggregation and transformation phases, we have significantly reduced chip sizes and energy consumption. We then divide the computing engine into blocked systolic arrays to support the \textit{Strassen}'s algorithm for dense matrix multiplication, dramatically scaling down the number of multiplications and enabling high-throughput computation of GNNs. To balance the workload of sparse-dense matrix multiplication, we also introduced a greedy algorithm to combine sparse sub-matrices of compressed format into condensed ones to reduce computational cycles. Compared with current state-of-the-art GNN software frameworks, \textit{VersaGNN} achieves on average 3712$\times$ speedup with 1301.25$\times$ energy reduction on CPU, and 35.4$\times$ speedup with 17.66$\times$ energy reduction on GPU.
A novel multiple instance learning framework for COVID-19 severity assessment via data augmentation and self-supervised learning
Feb 07, 2021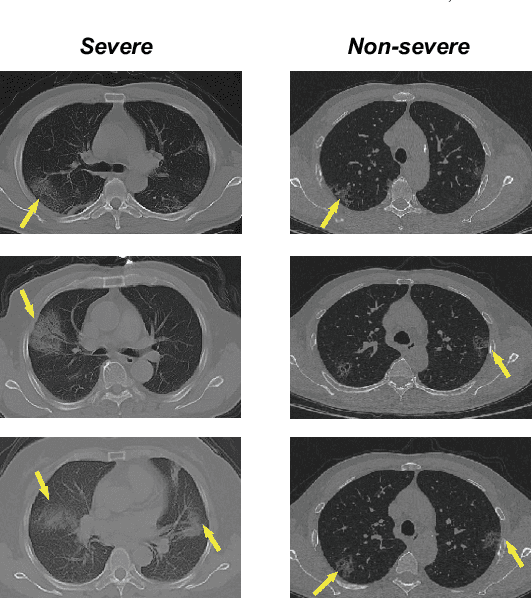
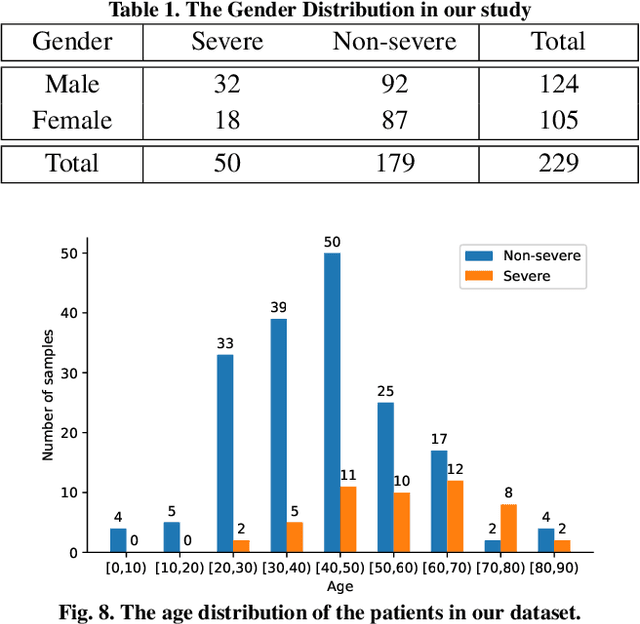
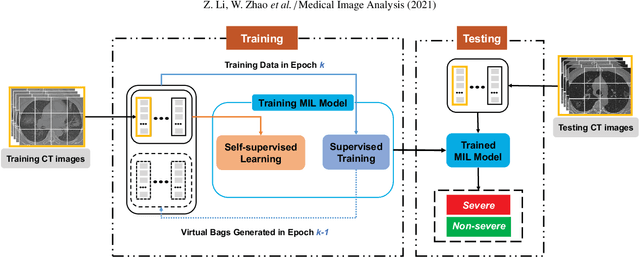

How to fast and accurately assess the severity level of COVID-19 is an essential problem, when millions of people are suffering from the pandemic around the world. Currently, the chest CT is regarded as a popular and informative imaging tool for COVID-19 diagnosis. However, we observe that there are two issues -- weak annotation and insufficient data that may obstruct automatic COVID-19 severity assessment with CT images. To address these challenges, we propose a novel three-component method, i.e., 1) a deep multiple instance learning component with instance-level attention to jointly classify the bag and also weigh the instances, 2) a bag-level data augmentation component to generate virtual bags by reorganizing high confidential instances, and 3) a self-supervised pretext component to aid the learning process. We have systematically evaluated our method on the CT images of 229 COVID-19 cases, including 50 severe and 179 non-severe cases. Our method could obtain an average accuracy of 95.8%, with 93.6% sensitivity and 96.4% specificity, which outperformed previous works.
Structured Attention for Unsupervised Dialogue Structure Induction
Oct 09, 2020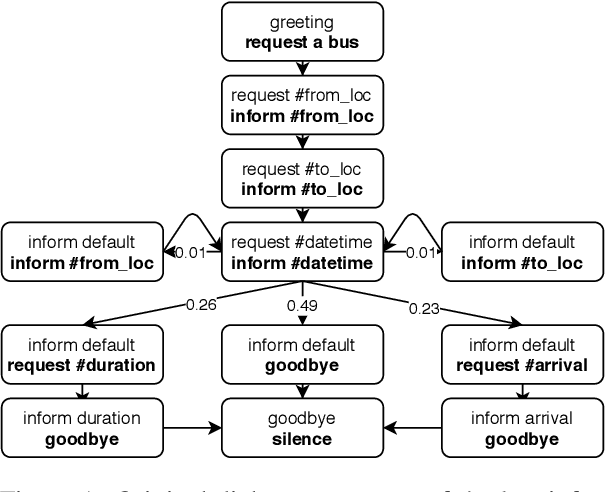

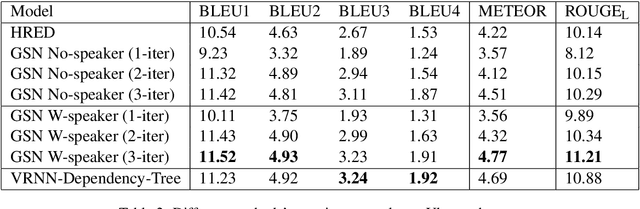
Inducing a meaningful structural representation from one or a set of dialogues is a crucial but challenging task in computational linguistics. Advancement made in this area is critical for dialogue system design and discourse analysis. It can also be extended to solve grammatical inference. In this work, we propose to incorporate structured attention layers into a Variational Recurrent Neural Network (VRNN) model with discrete latent states to learn dialogue structure in an unsupervised fashion. Compared to a vanilla VRNN, structured attention enables a model to focus on different parts of the source sentence embeddings while enforcing a structural inductive bias. Experiments show that on two-party dialogue datasets, VRNN with structured attention learns semantic structures that are similar to templates used to generate this dialogue corpus. While on multi-party dialogue datasets, our model learns an interactive structure demonstrating its capability of distinguishing speakers or addresses, automatically disentangling dialogues without explicit human annotation.
Synergistic Learning of Lung Lobe Segmentation and Hierarchical Multi-Instance Classification for Automated Severity Assessment of COVID-19 in CT Images
May 24, 2020
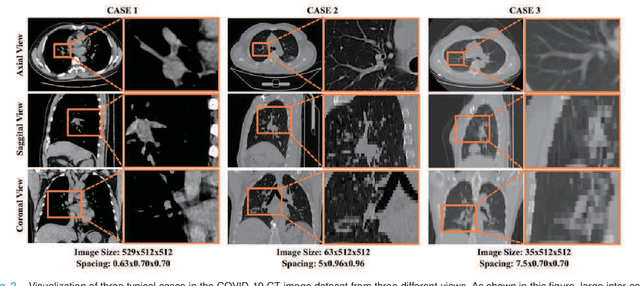
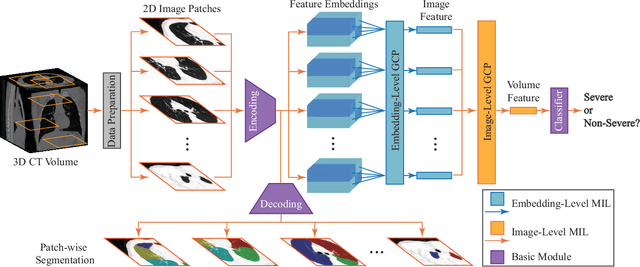
Understanding chest CT imaging of the coronavirus disease 2019 (COVID-19) will help detect infections early and assess the disease progression. Especially, automated severity assessment of COVID-19 in CT images plays an essential role in identifying cases that are in great need of intensive clinical care. However, it is often challenging to accurately assess the severity of this disease in CT images, due to variable infection regions in the lungs, similar imaging biomarkers, and large inter-case variations. To this end, we propose a synergistic learning framework for automated severity assessment of COVID-19 in 3D CT images, by jointly performing lung lobe segmentation and multi-instance classification. Considering that only a few infection regions in a CT image are related to the severity assessment, we first represent each input image by a bag that contains a set of 2D image patches (with each cropped from a specific slice). A multi-task multi-instance deep network (called M$^2$UNet) is then developed to assess the severity of COVID-19 patients and also segment the lung lobe simultaneously. Our M$^2$UNet consists of a patch-level encoder, a segmentation sub-network for lung lobe segmentation, and a classification sub-network for severity assessment (with a unique hierarchical multi-instance learning strategy). Here, the context information provided by segmentation can be implicitly employed to improve the performance of severity assessment. Extensive experiments were performed on a real COVID-19 CT image dataset consisting of 666 chest CT images, with results suggesting the effectiveness of our proposed method compared to several state-of-the-art methods.
Dual-Sampling Attention Network for Diagnosis of COVID-19 from Community Acquired Pneumonia
May 20, 2020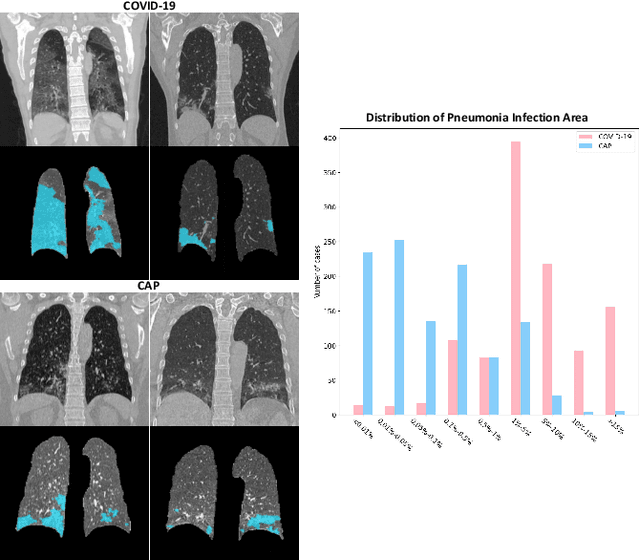
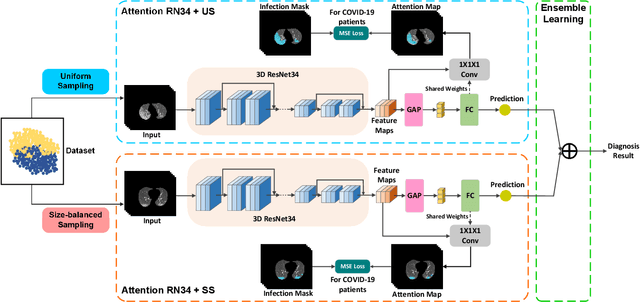
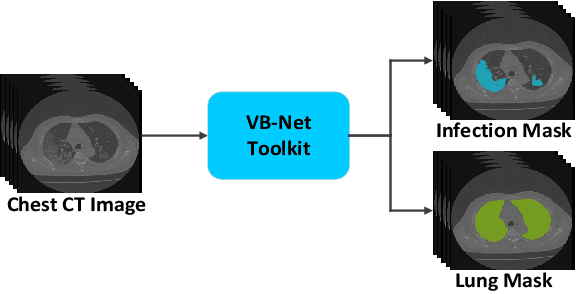
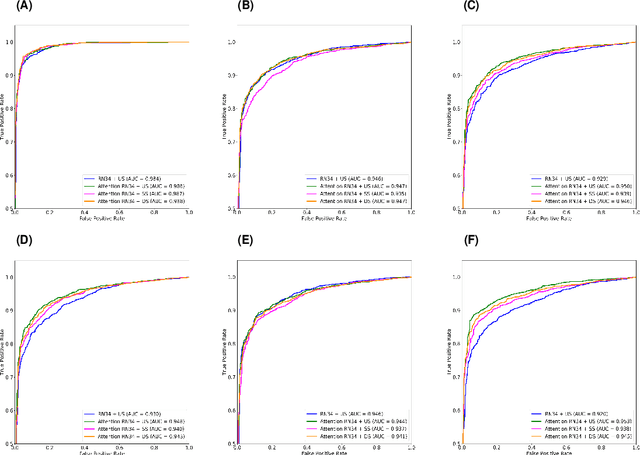
The coronavirus disease (COVID-19) is rapidly spreading all over the world, and has infected more than 1,436,000 people in more than 200 countries and territories as of April 9, 2020. Detecting COVID-19 at early stage is essential to deliver proper healthcare to the patients and also to protect the uninfected population. To this end, we develop a dual-sampling attention network to automatically diagnose COVID- 19 from the community acquired pneumonia (CAP) in chest computed tomography (CT). In particular, we propose a novel online attention module with a 3D convolutional network (CNN) to focus on the infection regions in lungs when making decisions of diagnoses. Note that there exists imbalanced distribution of the sizes of the infection regions between COVID-19 and CAP, partially due to fast progress of COVID-19 after symptom onset. Therefore, we develop a dual-sampling strategy to mitigate the imbalanced learning. Our method is evaluated (to our best knowledge) upon the largest multi-center CT data for COVID-19 from 8 hospitals. In the training-validation stage, we collect 2186 CT scans from 1588 patients for a 5-fold cross-validation. In the testing stage, we employ another independent large-scale testing dataset including 2796 CT scans from 2057 patients. Results show that our algorithm can identify the COVID-19 images with the area under the receiver operating characteristic curve (AUC) value of 0.944, accuracy of 87.5%, sensitivity of 86.9%, specificity of 90.1%, and F1-score of 82.0%. With this performance, the proposed algorithm could potentially aid radiologists with COVID-19 diagnosis from CAP, especially in the early stage of the COVID-19 outbreak.
Joint Prediction and Time Estimation of COVID-19 Developing Severe Symptoms using Chest CT Scan
May 07, 2020
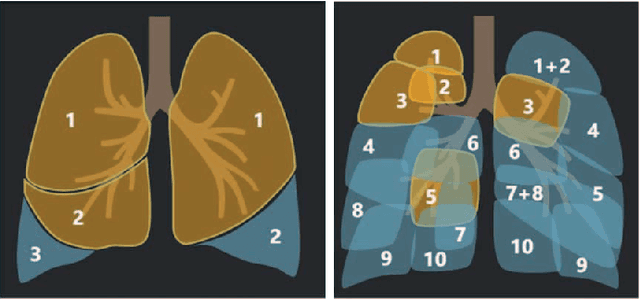
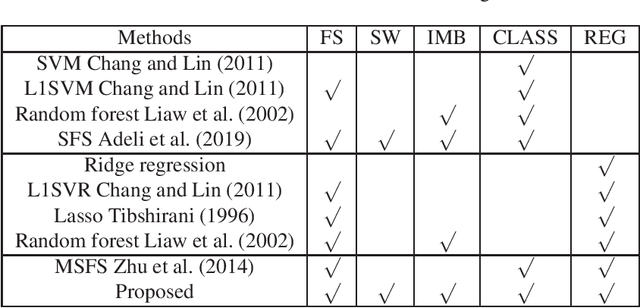
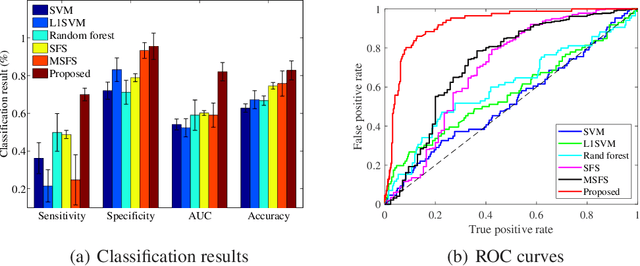
With the rapidly worldwide spread of Coronavirus disease (COVID-19), it is of great importance to conduct early diagnosis of COVID-19 and predict the time that patients might convert to the severe stage, for designing effective treatment plan and reducing the clinicians' workloads. In this study, we propose a joint classification and regression method to determine whether the patient would develop severe symptoms in the later time, and if yes, predict the possible conversion time that the patient would spend to convert to the severe stage. To do this, the proposed method takes into account 1) the weight for each sample to reduce the outliers' influence and explore the problem of imbalance classification, and 2) the weight for each feature via a sparsity regularization term to remove the redundant features of high-dimensional data and learn the shared information across the classification task and the regression task. To our knowledge, this study is the first work to predict the disease progression and the conversion time, which could help clinicians to deal with the potential severe cases in time or even save the patients' lives. Experimental analysis was conducted on a real data set from two hospitals with 422 chest computed tomography (CT) scans, where 52 cases were converted to severe on average 5.64 days and 34 cases were severe at admission. Results show that our method achieves the best classification (e.g., 85.91% of accuracy) and regression (e.g., 0.462 of the correlation coefficient) performance, compared to all comparison methods. Moreover, our proposed method yields 76.97% of accuracy for predicting the severe cases, 0.524 of the correlation coefficient, and 0.55 days difference for the converted time.
Hypergraph Learning for Identification of COVID-19 with CT Imaging
May 07, 2020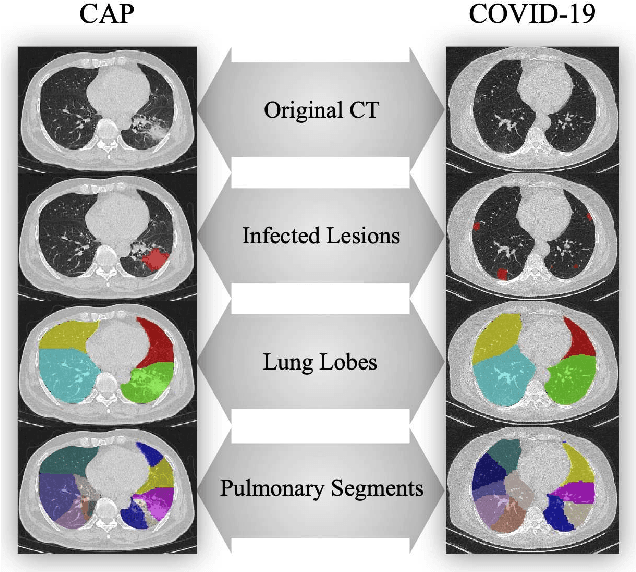

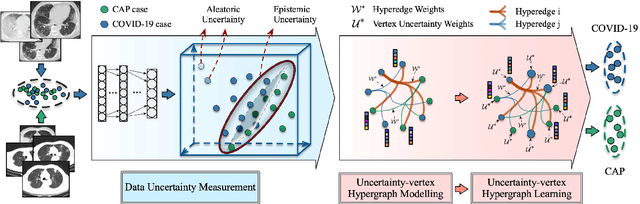

The coronavirus disease, named COVID-19, has become the largest global public health crisis since it started in early 2020. CT imaging has been used as a complementary tool to assist early screening, especially for the rapid identification of COVID-19 cases from community acquired pneumonia (CAP) cases. The main challenge in early screening is how to model the confusing cases in the COVID-19 and CAP groups, with very similar clinical manifestations and imaging features. To tackle this challenge, we propose an Uncertainty Vertex-weighted Hypergraph Learning (UVHL) method to identify COVID-19 from CAP using CT images. In particular, multiple types of features (including regional features and radiomics features) are first extracted from CT image for each case. Then, the relationship among different cases is formulated by a hypergraph structure, with each case represented as a vertex in the hypergraph. The uncertainty of each vertex is further computed with an uncertainty score measurement and used as a weight in the hypergraph. Finally, a learning process of the vertex-weighted hypergraph is used to predict whether a new testing case belongs to COVID-19 or not. Experiments on a large multi-center pneumonia dataset, consisting of 2,148 COVID-19 cases and 1,182 CAP cases from five hospitals, are conducted to evaluate the performance of the proposed method. Results demonstrate the effectiveness and robustness of our proposed method on the identification of COVID-19 in comparison to state-of-the-art methods.
Adaptive Feature Selection Guided Deep Forest for COVID-19 Classification with Chest CT
May 07, 2020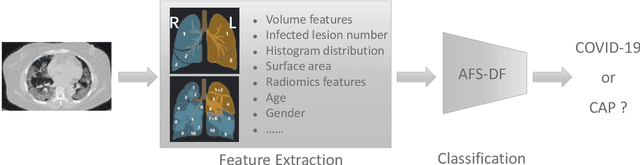
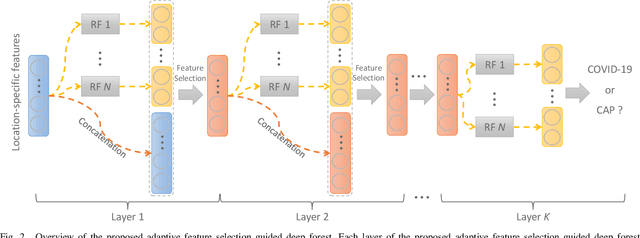
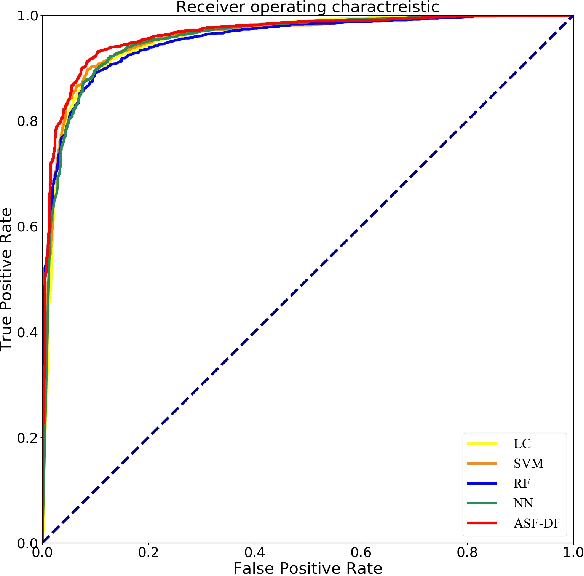
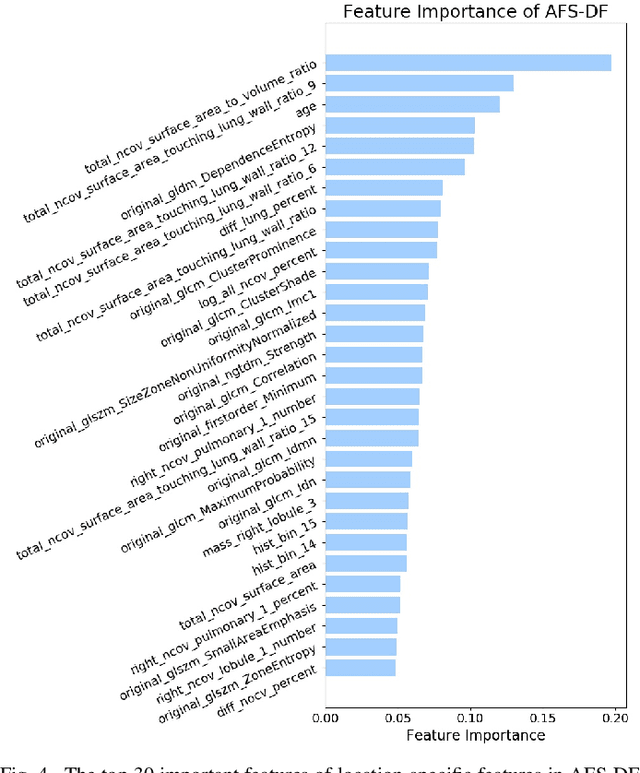
Chest computed tomography (CT) becomes an effective tool to assist the diagnosis of coronavirus disease-19 (COVID-19). Due to the outbreak of COVID-19 worldwide, using the computed-aided diagnosis technique for COVID-19 classification based on CT images could largely alleviate the burden of clinicians. In this paper, we propose an Adaptive Feature Selection guided Deep Forest (AFS-DF) for COVID-19 classification based on chest CT images. Specifically, we first extract location-specific features from CT images. Then, in order to capture the high-level representation of these features with the relatively small-scale data, we leverage a deep forest model to learn high-level representation of the features. Moreover, we propose a feature selection method based on the trained deep forest model to reduce the redundancy of features, where the feature selection could be adaptively incorporated with the COVID-19 classification model. We evaluated our proposed AFS-DF on COVID-19 dataset with 1495 patients of COVID-19 and 1027 patients of community acquired pneumonia (CAP). The accuracy (ACC), sensitivity (SEN), specificity (SPE) and AUC achieved by our method are 91.79%, 93.05%, 89.95% and 96.35%, respectively. Experimental results on the COVID-19 dataset suggest that the proposed AFS-DF achieves superior performance in COVID-19 vs. CAP classification, compared with 4 widely used machine learning methods.