 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb Photo Source Identification based on Neural Enhanced Camera Fingerprint
Feb 18, 2023With the growing popularity of smartphone photography in recent years, web photos play an increasingly important role in all walks of life. Source camera identification of web photos aims to establish a reliable linkage from the captured images to their source cameras, and has a broad range of applications, such as image copyright protection, user authentication, investigated evidence verification, etc. This paper presents an innovative and practical source identification framework that employs neural-network enhanced sensor pattern noise to trace back web photos efficiently while ensuring security. Our proposed framework consists of three main stages: initial device fingerprint registration, fingerprint extraction and cryptographic connection establishment while taking photos, and connection verification between photos and source devices. By incorporating metric learning and frequency consistency into the deep network design, our proposed fingerprint extraction algorithm achieves state-of-the-art performance on modern smartphone photos for reliable source identification. Meanwhile, we also propose several optimization sub-modules to prevent fingerprint leakage and improve accuracy and efficiency. Finally for practical system design, two cryptographic schemes are introduced to reliably identify the correlation between registered fingerprint and verified photo fingerprint, i.e. fuzzy extractor and zero-knowledge proof (ZKP). The codes for fingerprint extraction network and benchmark dataset with modern smartphone cameras photos are all publicly available at https://github.com/PhotoNecf/PhotoNecf.
Unsupervised Seismic Footprint Removal With Physical Prior Augmented Deep Autoencoder
Feb 08, 2023Seismic acquisition footprints appear as stably faint and dim structures and emerge fully spatially coherent, causing inevitable damage to useful signals during the suppression process. Various footprint removal methods, including filtering and sparse representation (SR), have been reported to attain promising results for surmounting this challenge. However, these methods, e.g., SR, rely solely on the handcrafted image priors of useful signals, which is sometimes an unreasonable demand if complex geological structures are contained in the given seismic data. As an alternative, this article proposes a footprint removal network (dubbed FR-Net) for the unsupervised suppression of acquired footprints without any assumptions regarding valuable signals. The key to the FR-Net is to design a unidirectional total variation (UTV) model for footprint acquisition according to the intrinsically directional property of noise. By strongly regularizing a deep convolutional autoencoder (DCAE) using the UTV model, our FR-Net transforms the DCAE from an entirely data-driven model to a \textcolor{black}{prior-augmented} approach, inheriting the superiority of the DCAE and our footprint model. Subsequently, the complete separation of the footprint noise and useful signals is projected in an unsupervised manner, specifically by optimizing the FR-Net via the backpropagation (BP) algorithm. We provide qualitative and quantitative evaluations conducted on three synthetic and field datasets, demonstrating that our FR-Net surpasses the previous state-of-the-art (SOTA) methods.
TransVCL: Attention-enhanced Video Copy Localization Network with Flexible Supervision
Nov 24, 2022



Video copy localization aims to precisely localize all the copied segments within a pair of untrimmed videos in video retrieval applications. Previous methods typically start from frame-to-frame similarity matrix generated by cosine similarity between frame-level features of the input video pair, and then detect and refine the boundaries of copied segments on similarity matrix under temporal constraints. In this paper, we propose TransVCL: an attention-enhanced video copy localization network, which is optimized directly from initial frame-level features and trained end-to-end with three main components: a customized Transformer for feature enhancement, a correlation and softmax layer for similarity matrix generation, and a temporal alignment module for copied segments localization. In contrast to previous methods demanding the handcrafted similarity matrix, TransVCL incorporates long-range temporal information between feature sequence pair using self- and cross- attention layers. With the joint design and optimization of three components, the similarity matrix can be learned to present more discriminative copied patterns, leading to significant improvements over previous methods on segment-level labeled datasets (VCSL and VCDB). Besides the state-of-the-art performance in fully supervised setting, the attention architecture facilitates TransVCL to further exploit unlabeled or simply video-level labeled data. Additional experiments of supplementing video-level labeled datasets including SVD and FIVR reveal the high flexibility of TransVCL from full supervision to semi-supervision (with or without video-level annotation). Code is publicly available at https://github.com/transvcl/TransVCL.
A Cooperative Perception Environment for Traffic Operations and Control
Aug 04, 2022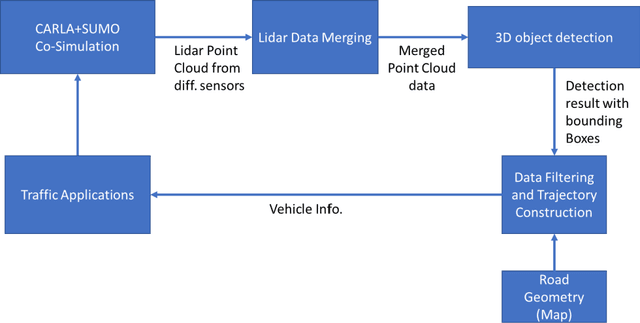


Existing data collection methods for traffic operations and control usually rely on infrastructure-based loop detectors or probe vehicle trajectories. Connected and automated vehicles (CAVs) not only can report data about themselves but also can provide the status of all detected surrounding vehicles. Integration of perception data from multiple CAVs as well as infrastructure sensors (e.g., LiDAR) can provide richer information even under a very low penetration rate. This paper aims to develop a cooperative data collection system, which integrates Lidar point cloud data from both infrastructure and CAVs to create a cooperative perception environment for various transportation applications. The state-of-the-art 3D detection models are applied to detect vehicles in the merged point cloud. We test the proposed cooperative perception environment with the max pressure adaptive signal control model in a co-simulation platform with CARLA and SUMO. Results show that very low penetration rates of CAV plus an infrastructure sensor are sufficient to achieve comparable performance with 30% or higher penetration rates of connected vehicles (CV). We also show the equivalent CV penetration rate (E-CVPR) under different CAV penetration rates to demonstrate the data collection efficiency of the cooperative perception environment.
A Large-scale Comprehensive Dataset and Copy-overlap Aware Evaluation Protocol for Segment-level Video Copy Detection
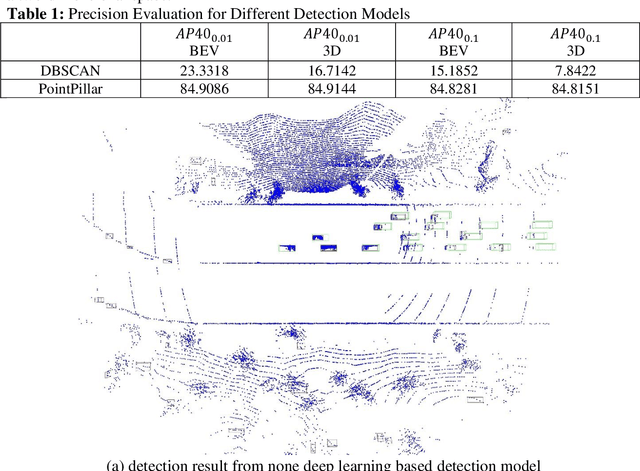
Mar 05, 2022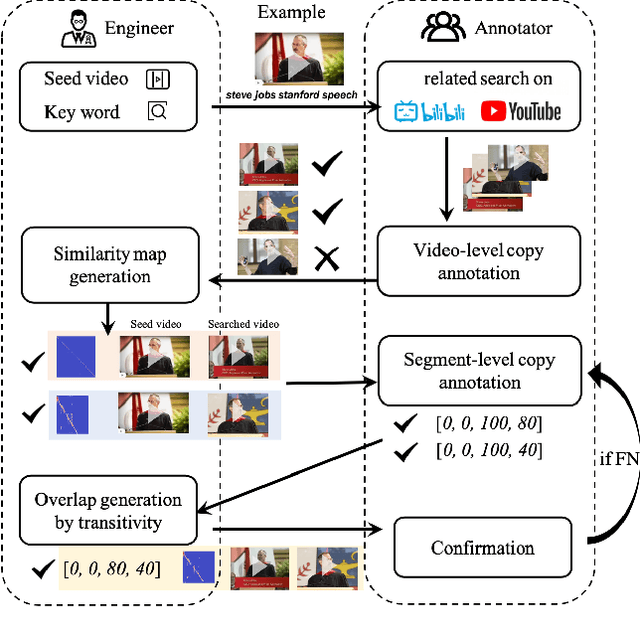
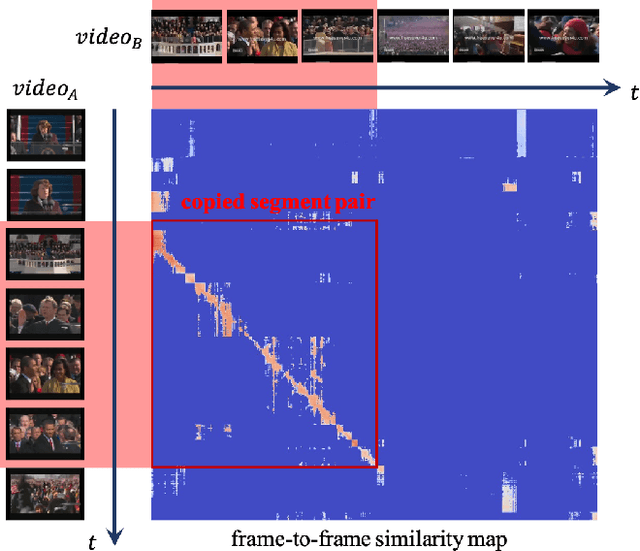
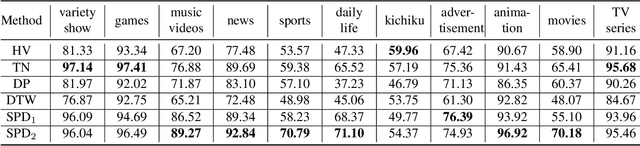
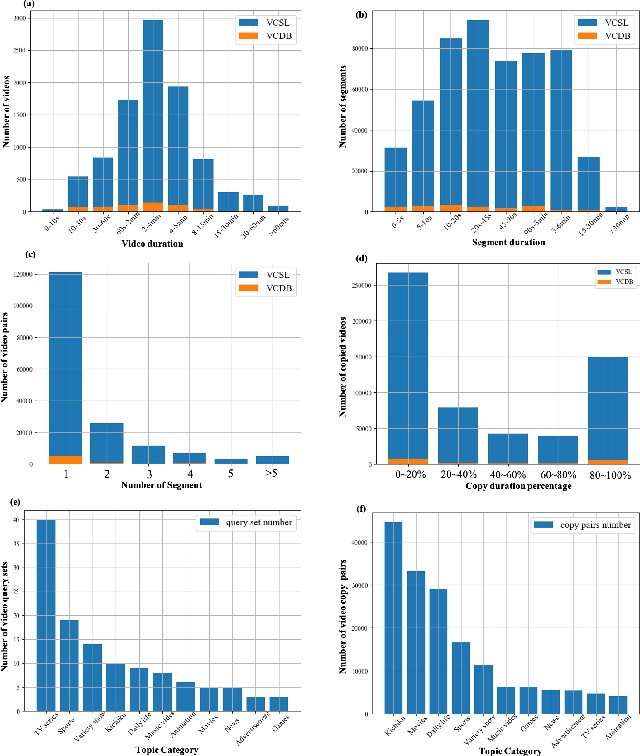
In this paper, we introduce VCSL (Video Copy Segment Localization), a new comprehensive segment-level annotated video copy dataset. Compared with existing copy detection datasets restricted by either video-level annotation or small-scale, VCSL not only has two orders of magnitude more segment-level labelled data, with 160k realistic video copy pairs containing more than 280k localized copied segment pairs, but also covers a variety of video categories and a wide range of video duration. All the copied segments inside each collected video pair are manually extracted and accompanied by precisely annotated starting and ending timestamps. Alongside the dataset, we also propose a novel evaluation protocol that better measures the prediction accuracy of copy overlapping segments between a video pair and shows improved adaptability in different scenarios. By benchmarking several baseline and state-of-the-art segment-level video copy detection methods with the proposed dataset and evaluation metric, we provide a comprehensive analysis that uncovers the strengths and weaknesses of current approaches, hoping to open up promising directions for future works. The VCSL dataset, metric and benchmark codes are all publicly available at https://github.com/alipay/VCSL.
When Autonomous Systems Meet Accuracy and Transferability through AI: A Survey
Apr 30, 2020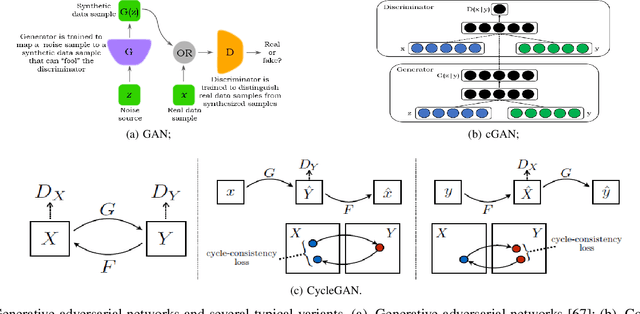
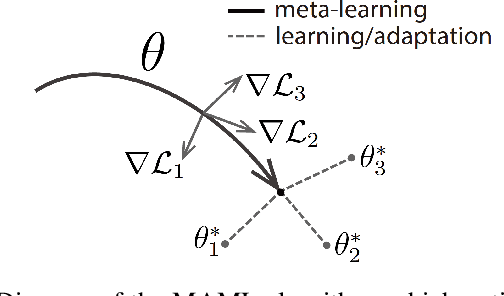


With widespread applications of artificial intelligence (AI), the capabilities of the perception, understanding, decision-making and control for autonomous systems have improved significantly in the past years. When autonomous systems consider the performance of accuracy and transferability, several AI methods, like adversarial learning, reinforcement learning (RL) and meta-learning, show their powerful performance. Here, we review the learning-based approaches in autonomous systems from the perspectives of accuracy and transferability. Accuracy means that a well-trained model shows good results during the testing phase, in which the testing set shares a same task or a data distribution with the training set. Transferability means that when a well-trained model is transferred to other testing domains, the accuracy is still good. Firstly, we introduce some basic concepts of transfer learning and then present some preliminaries of adversarial learning, RL and meta-learning. Secondly, we focus on reviewing the accuracy or transferability or both of them to show the advantages of adversarial learning, like generative adversarial networks (GANs), in typical computer vision tasks in autonomous systems, including image style transfer, image superresolution, image deblurring/dehazing/rain removal, semantic segmentation, depth estimation, pedestrian detection and person re-identification (re-ID). Then, we further review the performance of RL and meta-learning from the aspects of accuracy or transferability or both of them in autonomous systems, involving pedestrian tracking, robot navigation and robotic manipulation. Finally, we discuss several challenges and future topics for using adversarial learning, RL and meta-learning in autonomous systems.
Monocular Depth Estimation Based On Deep Learning: An Overview
Mar 14, 2020
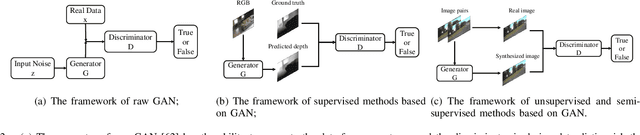
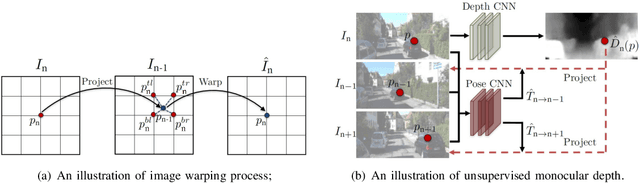
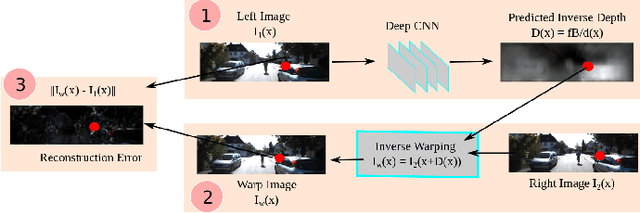
Depth information is important for autonomous systems to perceive environments and estimate their own state. Traditional depth estimation methods, like structure from motion and stereo vision matching, are built on feature correspondences of multiple viewpoints. Meanwhile, the predicted depth maps are sparse. Inferring depth information from a single image (monocular depth estimation) is an ill-posed problem. With the rapid development of deep neural networks, monocular depth estimation based on deep learning has been widely studied recently and achieved promising performance in accuracy. Meanwhile, dense depth maps are estimated from single images by deep neural networks in an end-to-end manner. In order to improve the accuracy of depth estimation, different kinds of network frameworks, loss functions and training strategies are proposed subsequently. Therefore, we survey the current monocular depth estimation methods based on deep learning in this review. Initially, we conclude several widely used datasets and evaluation indicators in deep learning-based depth estimation. Furthermore, we review some representative existing methods according to different training manners: supervised, unsupervised and semi-supervised. Finally, we discuss the challenges and provide some ideas for future researches in monocular depth estimation.
An Overview of Perception and Decision-Making in Autonomous Systems in the Era of Learning
Feb 24, 2020Autonomous systems possess the features of inferring their own ego-motion, autonomously understanding their surroundings, and planning trajectories. With the applications of deep learning and reinforcement learning, the perception and decision-making abilities of autonomous systems are being efficiently addressed, and many new learning-based algorithms have surfaced with respect to autonomous perception and decision-making. In this review, we focus on the applications of learning-based approaches in perception and decision-making in autonomous systems, which is different from previous reviews that discussed traditional methods. First, we delineate the existing classical simultaneous localization and mapping (SLAM) solutions and review the environmental perception and understanding methods based on deep learning, including deep learning-based monocular depth estimation, ego-motion prediction, image enhancement, object detection, semantic segmentation, and their combinations with traditional SLAM frameworks. Second, we briefly summarize the existing motion planning techniques, such as path planning and trajectory planning methods, and discuss the navigation methods based on reinforcement learning. Finally, we examine the several challenges and promising directions discussed and concluded in related research for future works in the era of computer science, automatic control, and robotics.
Combating Fake News: A Survey on Identification and Mitigation Techniques
Jan 18, 2019

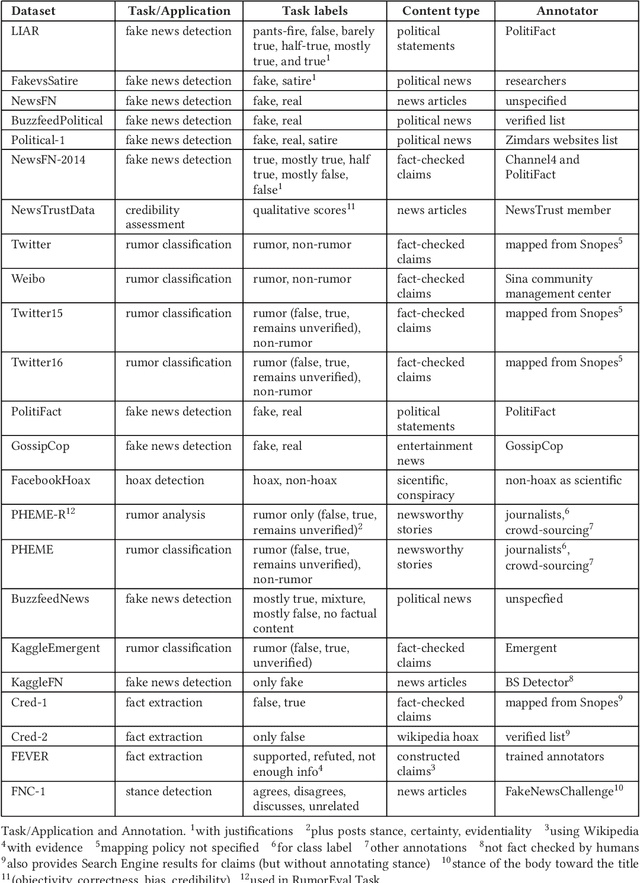
The proliferation of fake news on social media has opened up new directions of research for timely identification and containment of fake news, and mitigation of its widespread impact on public opinion. While much of the earlier research was focused on identification of fake news based on its contents or by exploiting users' engagements with the news on social media, there has been a rising interest in proactive intervention strategies to counter the spread of misinformation and its impact on society. In this survey, we describe the modern-day problem of fake news and, in particular, highlight the technical challenges associated with it. We discuss existing methods and techniques applicable to both identification and mitigation, with a focus on the significant advances in each method and their advantages and limitations. In addition, research has often been limited by the quality of existing datasets and their specific application contexts. To alleviate this problem, we comprehensively compile and summarize characteristic features of available datasets. Furthermore, we outline new directions of research to facilitate future development of effective and interdisciplinary solutions.
Multidimensional Data Tensor Sensing for RF Tomographic Imaging
Dec 16, 2017
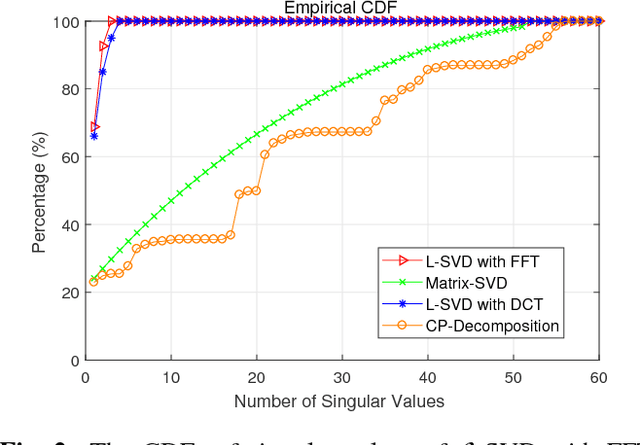

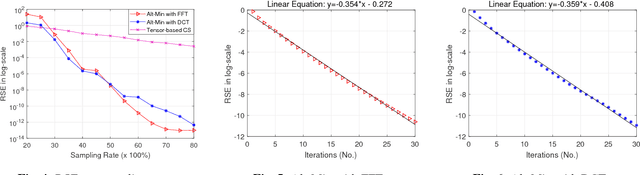
Radio-frequency (RF) tomographic imaging is a promising technique for inferring multi-dimensional physical space by processing RF signals traversed across a region of interest. However, conventional RF tomography schemes are generally based on vector compressed sensing, which ignores the geometric structures of the target spaces and leads to low recovery precision. The recently proposed transform-based tensor model is more appropriate for sensory data processing, as it helps exploit the geometric structures of the three-dimensional target and improve the recovery precision. In this paper, we propose a novel tensor sensing approach that achieves highly accurate estimation for real-world three-dimensional spaces. First, we use the transform-based tensor model to formulate a tensor sensing problem, and propose a fast alternating minimization algorithm called Alt-Min. Secondly, we drive an algorithm which is optimized to reduce memory and computation requirements. Finally, we present evaluation of our Alt-Min approach using IKEA 3D data and demonstrate significant improvement in recovery error and convergence speed compared to prior tensor-based compressed sensing.