 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Semantic Alignment for LLM-based Time Series Forecasting
Jun 06, 2026Recent advances in Large Language Models (LLMs) have opened new possibilities for time series forecasting by enabling alignment between temporal patterns and pretrained word embeddings. However, most LLM-based methods overlook the heterogeneous nature of time series, where dynamic fluctuations and invariant semantics are entangled. This entanglement introduces spurious correlations during the alignment, as dynamic components act as confounders by simultaneously influencing invariant components and the resulting aligned embeddings. To address this issue, a variable-level alignment framework CVAformer is proposed. CVAformer explicitly disentangles each variable into invariant and dynamic components just before alignment, and applies causal intervention to mitigate the confounding effect of the dynamics. To better support variable-level alignment, CVAformer replaces the standard causal attention in LLMs with a non-causal attention mechanism that captures interactions among variables at each time step. Extensive experiments across long-term, short-term, few-shot, and zero-shot forecasting settings indicate that CVAformer matches or exceeds state-of-the-art performance on most datasets, and in some cases achieves notably better accuracy. Experimental results validate the effectiveness of variable-level alignment and dynamic disentanglement in CVAformer, offering a new perspective for LLM-based time series tasks.
Beyond Benchmark: LLMs Evaluation with an Anthropomorphic and Value-oriented Roadmap
Aug 26, 2025For Large Language Models (LLMs), a disconnect persists between benchmark performance and real-world utility. Current evaluation frameworks remain fragmented, prioritizing technical metrics while neglecting holistic assessment for deployment. This survey introduces an anthropomorphic evaluation paradigm through the lens of human intelligence, proposing a novel three-dimensional taxonomy: Intelligence Quotient (IQ)-General Intelligence for foundational capacity, Emotional Quotient (EQ)-Alignment Ability for value-based interactions, and Professional Quotient (PQ)-Professional Expertise for specialized proficiency. For practical value, we pioneer a Value-oriented Evaluation (VQ) framework assessing economic viability, social impact, ethical alignment, and environmental sustainability. Our modular architecture integrates six components with an implementation roadmap. Through analysis of 200+ benchmarks, we identify key challenges including dynamic assessment needs and interpretability gaps. It provides actionable guidance for developing LLMs that are technically proficient, contextually relevant, and ethically sound. We maintain a curated repository of open-source evaluation resources at: https://github.com/onejune2018/Awesome-LLM-Eval.
An Efficient Dynamic Resource Allocation Framework for Evolutionary Bilevel Optimization
Oct 31, 2024Bilevel optimization problems are characterized by an interactive hierarchical structure, where the upper level seeks to optimize its strategy while simultaneously considering the response of the lower level. Evolutionary algorithms are commonly used to solve complex bilevel problems in practical scenarios, but they face significant resource consumption challenges due to the nested structure imposed by the implicit lower-level optimality condition. This challenge becomes even more pronounced as problem dimensions increase. Although recent methods have enhanced bilevel convergence through task-level knowledge sharing, further efficiency improvements are still hindered by redundant lower-level iterations that consume excessive resources while generating unpromising solutions. To overcome this challenge, this paper proposes an efficient dynamic resource allocation framework for evolutionary bilevel optimization, named DRC-BLEA. Compared to existing approaches, DRC-BLEA introduces a novel competitive quasi-parallel paradigm, in which multiple lower-level optimization tasks, derived from different upper-level individuals, compete for resources. A continuously updated selection probability is used to prioritize execution opportunities to promising tasks. Additionally, a cooperation mechanism is integrated within the competitive framework to further enhance efficiency and prevent premature convergence. Experimental results compared with chosen state-of-the-art algorithms demonstrate the effectiveness of the proposed method. Specifically, DRC-BLEA achieves competitive accuracy across diverse problem sets and real-world scenarios, while significantly reducing the number of function evaluations and overall running time.
HMAMP: Hypervolume-Driven Multi-Objective Antimicrobial Peptides Design
May 01, 2024Antimicrobial peptides (AMPs) have exhibited unprecedented potential as biomaterials in combating multidrug-resistant bacteria. Despite the increasing adoption of artificial intelligence for novel AMP design, challenges pertaining to conflicting attributes such as activity, hemolysis, and toxicity have significantly impeded the progress of researchers. This paper introduces a paradigm shift by considering multiple attributes in AMP design. Presented herein is a novel approach termed Hypervolume-driven Multi-objective Antimicrobial Peptide Design (HMAMP), which prioritizes the simultaneous optimization of multiple attributes of AMPs. By synergizing reinforcement learning and a gradient descent algorithm rooted in the hypervolume maximization concept, HMAMP effectively expands exploration space and mitigates the issue of pattern collapse. This method generates a wide array of prospective AMP candidates that strike a balance among diverse attributes. Furthermore, we pinpoint knee points along the Pareto front of these candidate AMPs. Empirical results across five benchmark models substantiate that HMAMP-designed AMPs exhibit competitive performance and heightened diversity. A detailed analysis of the helical structures and molecular dynamics simulations for ten potential candidate AMPs validates the superiority of HMAMP in the realm of multi-objective AMP design. The ability of HMAMP to systematically craft AMPs considering multiple attributes marks a pioneering milestone, establishing a universal computational framework for the multi-objective design of AMPs.
A Composite Decomposition Method for Large-Scale Global Optimization
Mar 08, 2024



Cooperative co-evolution (CC) algorithms, based on the divide-and-conquer strategy, have emerged as the predominant approach to solving large-scale global optimization (LSGO) problems. The efficiency and accuracy of the grouping stage significantly impact the performance of the optimization process. While the general separability grouping (GSG) method has overcome the limitation of previous differential grouping (DG) methods by enabling the decomposition of non-additively separable functions, it suffers from high computational complexity. To address this challenge, this article proposes a composite separability grouping (CSG) method, seamlessly integrating DG and GSG into a problem decomposition framework to utilize the strengths of both approaches. CSG introduces a step-by-step decomposition framework that accurately decomposes various problem types using fewer computational resources. By sequentially identifying additively, multiplicatively and generally separable variables, CSG progressively groups non-separable variables by recursively considering the interactions between each non-separable variable and the formed non-separable groups. Furthermore, to enhance the efficiency and accuracy of CSG, we introduce two innovative methods: a multiplicatively separable variable detection method and a non-separable variable grouping method. These two methods are designed to effectively detect multiplicatively separable variables and efficiently group non-separable variables, respectively. Extensive experimental results demonstrate that CSG achieves more accurate variable grouping with lower computational complexity compared to GSG and state-of-the-art DG series designs.
Improving Performance Insensitivity of Large-scale Multiobjective Optimization via Monte Carlo Tree Search
Apr 14, 2023The large-scale multiobjective optimization problem (LSMOP) is characterized by simultaneously optimizing multiple conflicting objectives and involving hundreds of decision variables. Many real-world applications in engineering fields can be modeled as LSMOPs; simultaneously, engineering applications require insensitivity in performance. This requirement usually means that the results from the algorithm runs should not only be good for every run in terms of performance but also that the performance of multiple runs should not fluctuate too much, i.e., the algorithm shows good insensitivity. Considering that substantial computational resources are requested for each run, it is essential to improve upon the performance of the large-scale multiobjective optimization algorithm, as well as the insensitivity of the algorithm. However, existing large-scale multiobjective optimization algorithms solely focus on improving the performance of the algorithms, leaving the insensitivity characteristics unattended. In this work, we propose an evolutionary algorithm for solving LSMOPs based on Monte Carlo tree search, the so-called LMMOCTS, which aims to improve the performance and insensitivity for large-scale multiobjective optimization problems. The proposed method samples the decision variables to construct new nodes on the Monte Carlo tree for optimization and evaluation. It selects nodes with good evaluation for further search to reduce the performance sensitivity caused by large-scale decision variables. We compare the proposed algorithm with several state-of-the-art designs on different benchmark functions. We also propose two metrics to measure the sensitivity of the algorithm. The experimental results confirm the effectiveness and performance insensitivity of the proposed design for solving large-scale multiobjective optimization problems.
Efficient Evaluation Methods for Neural Architecture Search: A Survey
Jan 14, 2023Neural Architecture Search (NAS) has received increasing attention because of its exceptional merits in automating the design of Deep Neural Network (DNN) architectures. However, the performance evaluation process, as a key part of NAS, often requires training a large number of DNNs. This inevitably causes NAS computationally expensive. In past years, many Efficient Evaluation Methods (EEMs) have been proposed to address this critical issue. In this paper, we comprehensively survey these EEMs published up to date, and provide a detailed analysis to motivate the further development of this research direction. Specifically, we divide the existing EEMs into four categories based on the number of DNNs trained for constructing these EEMs. The categorization can reflect the degree of efficiency in principle, which can in turn help quickly grasp the methodological features. In surveying each category, we further discuss the design principles and analyze the strength and weaknesses to clarify the landscape of existing EEMs, thus making easily understanding the research trends of EEMs. Furthermore, we also discuss the current challenges and issues to identify future research directions in this emerging topic. To the best of our knowledge, this is the first work that extensively and systematically surveys the EEMs of NAS.
Analysis of Expected Hitting Time for Designing Evolutionary Neural Architecture Search Algorithms
Oct 11, 2022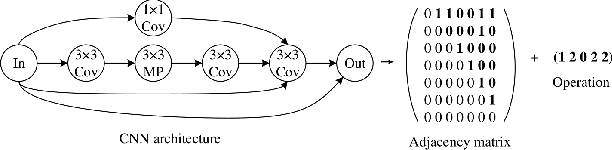
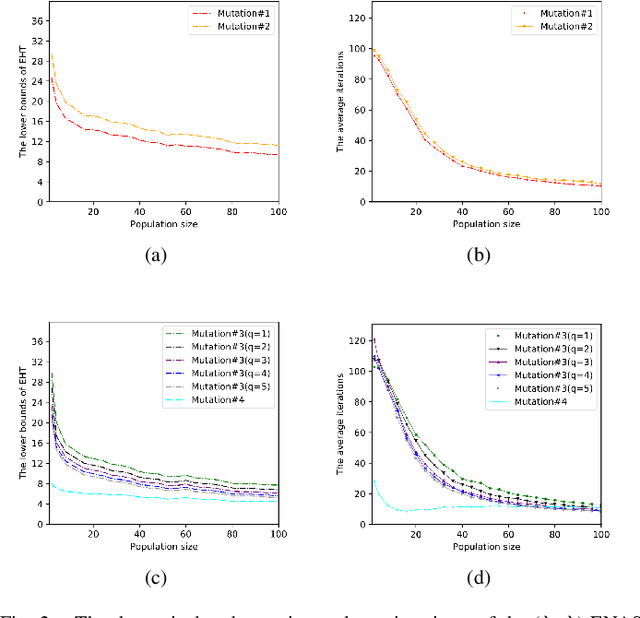
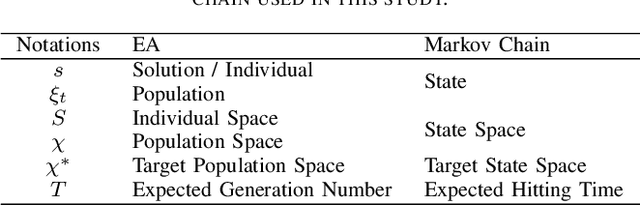
Evolutionary computation-based neural architecture search (ENAS) is a popular technique for automating architecture design of deep neural networks. In recent years, various ENAS algorithms have been proposed and shown promising performance on diverse real-world applications. In contrast to these groundbreaking applications, there is no theoretical guideline for assigning a reasonable running time (mainly affected by the generation number, population size, and evolution operator) given both the anticipated performance and acceptable computation budget on ENAS problems. The expected hitting time (EHT), which refers to the average generations, is considered to analyze the running time of ENAS algorithms. This paper proposes a general framework for estimating the EHT of ENAS algorithms, which includes common configuration, search space partition, transition probability estimation, and hitting time analysis. By exploiting the proposed framework, we consider the so-called ($\lambda$+$\lambda$)-ENAS algorithms with different mutation operators and manage to estimate the lower bounds of the EHT {which are critical for the algorithm to find the global optimum}. Furthermore, we study the theoretical results on the NAS-Bench-101 architecture searching problem, and the results show that the one-bit mutation with "bit-based fair mutation" strategy needs less time than the "offspring-based fair mutation" strategy, and the bitwise mutation operator needs less time than the $q$-bit mutation operator. To the best of our knowledge, this is the first work focusing on the theory of ENAS, and the above observation will be substantially helpful in designing efficient ENAS algorithms.
Learn to Adapt for Monocular Depth Estimation
Mar 26, 2022
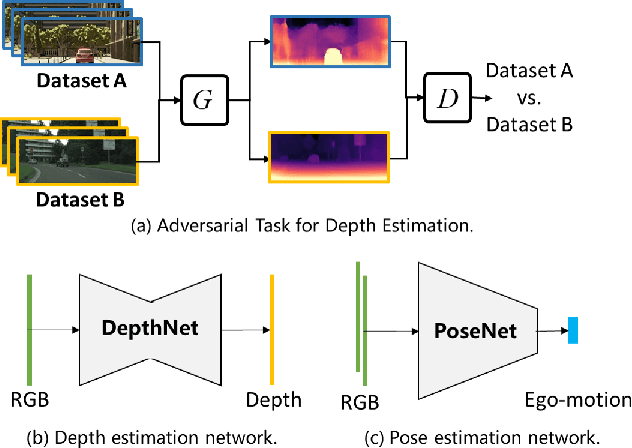
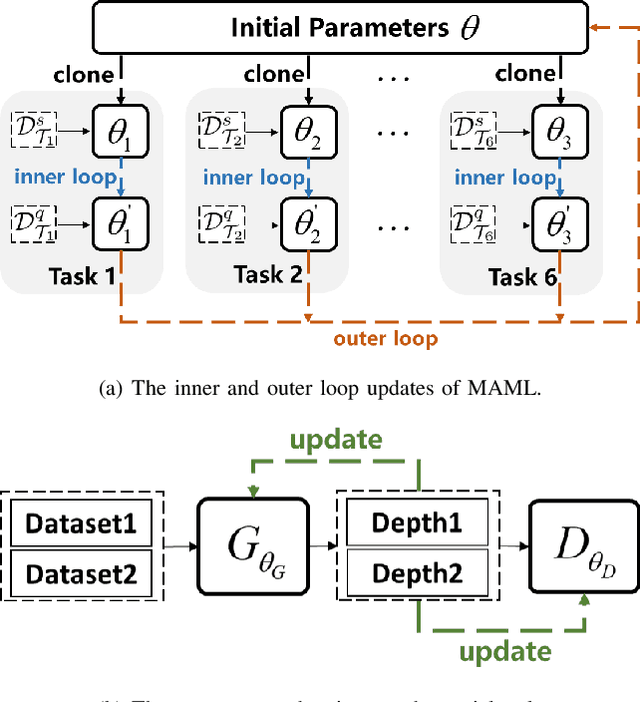

Monocular depth estimation is one of the fundamental tasks in environmental perception and has achieved tremendous progress in virtue of deep learning. However, the performance of trained models tends to degrade or deteriorate when employed on other new datasets due to the gap between different datasets. Though some methods utilize domain adaptation technologies to jointly train different domains and narrow the gap between them, the trained models cannot generalize to new domains that are not involved in training. To boost the transferability of depth estimation models, we propose an adversarial depth estimation task and train the model in the pipeline of meta-learning. Our proposed adversarial task mitigates the issue of meta-overfitting, since the network is trained in an adversarial manner and aims to extract domain invariant representations. In addition, we propose a constraint to impose upon cross-task depth consistency to compel the depth estimation to be identical in different adversarial tasks, which improves the performance of our method and smoothens the training process. Experiments demonstrate that our method adapts well to new datasets after few training steps during the test procedure.
BenchENAS: A Benchmarking Platform for Evolutionary Neural Architecture Search
Aug 14, 2021
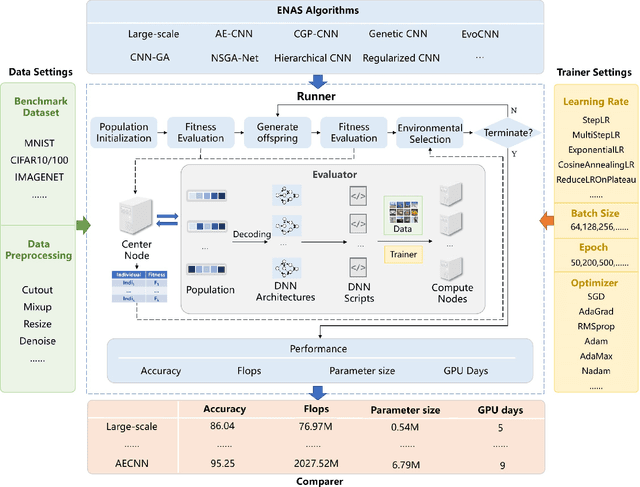
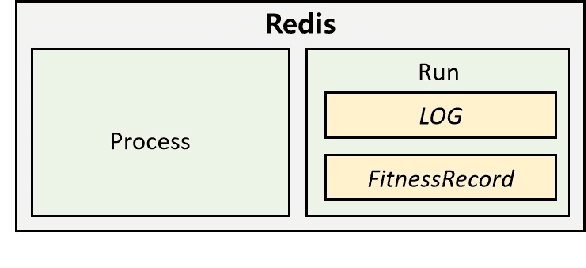
Neural architecture search (NAS), which automatically designs the architectures of deep neural networks, has achieved breakthrough success over many applications in the past few years. Among different classes of NAS methods, evolutionary computation based NAS (ENAS) methods have recently gained much attention. Unfortunately, the issues of fair comparisons and efficient evaluations have hindered the development of ENAS. The current benchmark architecture datasets designed for fair comparisons only provide the datasets, not the ENAS algorithms or the platform to run the algorithms. The existing efficient evaluation methods are either not suitable for the population-based ENAS algorithm or are too complex to use. This paper develops a platform named BenchENAS to address these issues. BenchENAS aims to achieve fair comparisons by running different algorithms in the same environment and with the same settings. To achieve efficient evaluation in a common lab environment, BenchENAS designs a parallel component and a cache component with high maintainability. Furthermore, BenchENAS is easy to install and highly configurable and modular, which brings benefits in good usability and easy extensibility. The paper conducts efficient comparison experiments on eight ENAS algorithms with high GPU utilization on this platform. The experiments validate that the fair comparison issue does exist, and BenchENAS can alleviate this issue. A website has been built to promote BenchENAS at https://benchenas.com, where interested researchers can obtain the source code and document of BenchENAS for free.