 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIGA: Self-Evolving Coding-Agent Adapters for Scientific Simulation
Jun 08, 2026Advanced scientific simulators expose specialized input languages that turn simulation goals into executable configurations, but learning them can cost domain scientists hours to days. We study simulator setup as a problem of agent-tool interface grounding: what minimal simulator-specific adaptations are needed for an off-the-shelf coding agent to operate real scientific software? Our intuition is that coding agents already know how to navigate files, edit code, run commands, and repair outputs, but they lack the simulator's executable contract: its vocabulary, structural constraints, validation rules, and termination conditions. We introduce SIGA, a Simulator-Interface Grounding Adapter that supplies this contract through retrieval, procedural memory, in-trajectory validation, and validation-enforced termination. We primarily evaluate SIGA on GEOS, an open-source multiphysics simulator used in subsurface science. SIGA produces a complete GEOS deck in about five minutes with TreeSim above 0.90, matching an extended-budget human expert who took about three hours, a roughly 36x wall-clock speedup. On a harder held-out set, grounding raises TreeSim from 0.720 to 0.789, a roughly 10% relative gain over the bare agent, and can reduce the across-seed standard deviation by 16x. Self-evolution further improves SIGA by rewriting adapter contents from prior trajectories, yielding the highest held-out GEOS mean and matching or outperforming the strongest hand-designed configuration. Transfers to OpenFOAM and LAMMPS show that the dominant mechanism shifts by interface: validation matters most when structural completeness is the bottleneck, while memory and retrieval matter most when domain correctness is the bottleneck. These results suggest that lightweight, self-improvable grounding layers can turn general coding agents into practical operators of scientific software.
MEGnifying Emotion: Sentiment Analysis from Annotated Brain Data
Jan 26, 2026Decoding emotion from brain activity could unlock a deeper understanding of the human experience. While a number of existing datasets align brain data with speech and with speech transcripts, no datasets have annotated brain data with sentiment. To bridge this gap, we explore the use of pre-trained Text-to-Sentiment models to annotate non invasive brain recordings, acquired using magnetoencephalography (MEG), while participants listened to audiobooks. Having annotated the text, we employ force-alignment of the text and audio to align our sentiment labels with the brain recordings. It is straightforward then to train Brainto-Sentiment models on these data. Experimental results show an improvement in balanced accuracy for Brain-to-Sentiment compared to baseline, supporting the proposed approach as a proof-of-concept for leveraging existing MEG datasets and learning to decode sentiment directly from the brain.
RobotCycle: Assessing Cycling Safety in Urban Environments
Mar 12, 2024



This paper introduces RobotCycle, a novel ongoing project that leverages Autonomous Vehicle (AV) research to investigate how cycling infrastructure influences cyclist behaviour and safety during real-world journeys. The project's requirements were defined in collaboration with key stakeholders (i.e. city planners, cyclists, and policymakers), informing the design of risk and safety metrics and the data collection criteria. We propose a data-driven approach relying on a novel, rich dataset of diverse traffic scenes captured through a custom-designed wearable sensing unit. We extract road-user trajectories and analyse deviations suggesting risk or potentially hazardous interactions in correlation with infrastructural elements in the environment. Driving profiles and trajectory patterns are associated with local road segments, driving conditions, and road-user interactions to predict traffic behaviour and identify critical scenarios. Moreover, leveraging advancements in AV research, the project extracts detailed 3D maps, traffic flow patterns, and trajectory models to provide an in-depth assessment and analysis of the behaviour of all traffic agents. This data can then inform the design of cyclist-friendly road infrastructure, improving road safety and cyclability, as it provides valuable insights for enhancing cyclist protection and promoting sustainable urban mobility.
FAST: An Optimization Framework for Fast Additive Segmentation in Transparent ML
Feb 20, 2024



We present FAST, an optimization framework for fast additive segmentation. FAST segments piecewise constant shape functions for each feature in a dataset to produce transparent additive models. The framework leverages a novel optimization procedure to fit these models $\sim$2 orders of magnitude faster than existing state-of-the-art methods, such as explainable boosting machines \citep{nori2019interpretml}. We also develop new feature selection algorithms in the FAST framework to fit parsimonious models that perform well. Through experiments and case studies, we show that FAST improves the computational efficiency and interpretability of additive models.
Randomization Can Reduce Both Bias and Variance: A Case Study in Random Forests
Feb 20, 2024We study the often overlooked phenomenon, first noted in \cite{breiman2001random}, that random forests appear to reduce bias compared to bagging. Motivated by an interesting paper by \cite{mentch2020randomization}, where the authors argue that random forests reduce effective degrees of freedom and only outperform bagging ensembles in low signal-to-noise ratio (SNR) settings, we explore how random forests can uncover patterns in the data missed by bagging. We empirically demonstrate that in the presence of such patterns, random forests reduce bias along with variance and increasingly outperform bagging ensembles when SNR is high. Our observations offer insights into the real-world success of random forests across a range of SNRs and enhance our understanding of the difference between random forests and bagging ensembles with respect to the randomization injected into each split. Our investigations also yield practical insights into the importance of tuning $mtry$ in random forests.
FIRE: An Optimization Approach for Fast Interpretable Rule Extraction
Jun 12, 2023



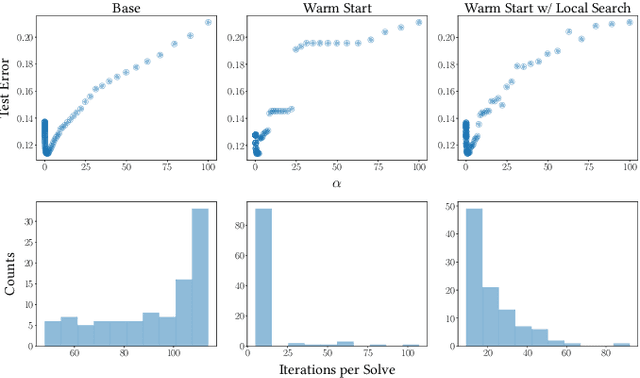
We present FIRE, Fast Interpretable Rule Extraction, an optimization-based framework to extract a small but useful collection of decision rules from tree ensembles. FIRE selects sparse representative subsets of rules from tree ensembles, that are easy for a practitioner to examine. To further enhance the interpretability of the extracted model, FIRE encourages fusing rules during selection, so that many of the selected decision rules share common antecedents. The optimization framework utilizes a fusion regularization penalty to accomplish this, along with a non-convex sparsity-inducing penalty to aggressively select rules. Optimization problems in FIRE pose a challenge to off-the-shelf solvers due to problem scale and the non-convexity of the penalties. To address this, making use of problem-structure, we develop a specialized solver based on block coordinate descent principles; our solver performs up to 40x faster than existing solvers. We show in our experiments that FIRE outperforms state-of-the-art rule ensemble algorithms at building sparse rule sets, and can deliver more interpretable models compared to existing methods.
A Cooperative Perception Environment for Traffic Operations and Control
Aug 04, 2022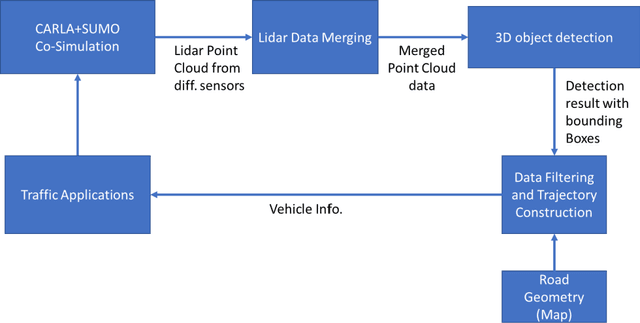
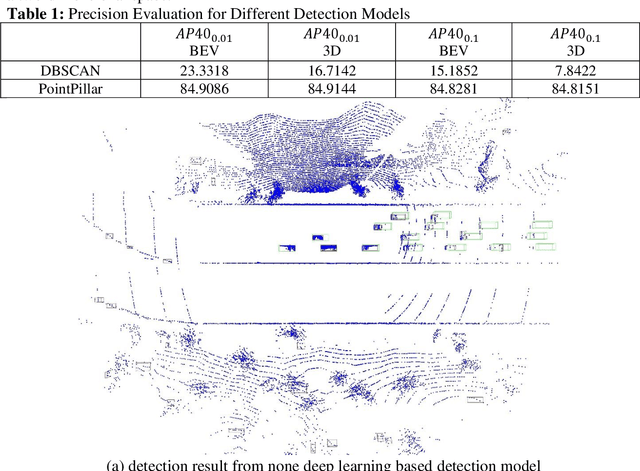


Existing data collection methods for traffic operations and control usually rely on infrastructure-based loop detectors or probe vehicle trajectories. Connected and automated vehicles (CAVs) not only can report data about themselves but also can provide the status of all detected surrounding vehicles. Integration of perception data from multiple CAVs as well as infrastructure sensors (e.g., LiDAR) can provide richer information even under a very low penetration rate. This paper aims to develop a cooperative data collection system, which integrates Lidar point cloud data from both infrastructure and CAVs to create a cooperative perception environment for various transportation applications. The state-of-the-art 3D detection models are applied to detect vehicles in the merged point cloud. We test the proposed cooperative perception environment with the max pressure adaptive signal control model in a co-simulation platform with CARLA and SUMO. Results show that very low penetration rates of CAV plus an infrastructure sensor are sufficient to achieve comparable performance with 30% or higher penetration rates of connected vehicles (CV). We also show the equivalent CV penetration rate (E-CVPR) under different CAV penetration rates to demonstrate the data collection efficiency of the cooperative perception environment.
ControlBurn: Nonlinear Feature Selection with Sparse Tree Ensembles
Jul 08, 2022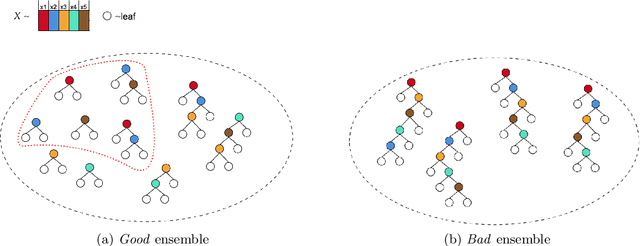

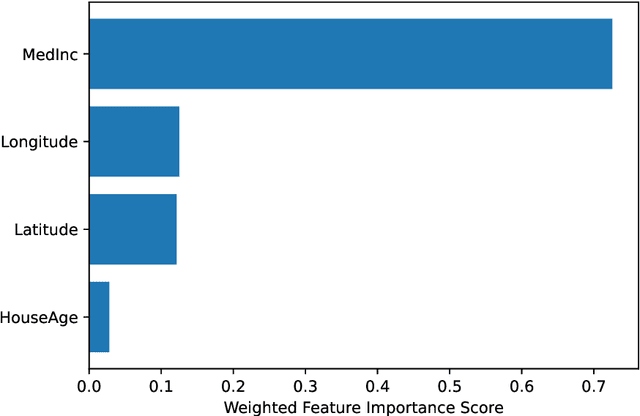
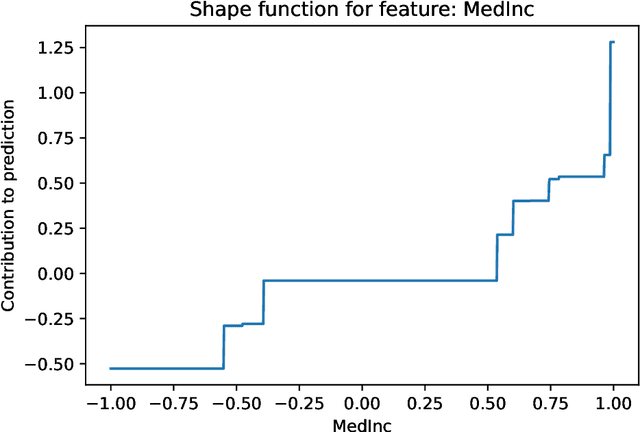
ControlBurn is a Python package to construct feature-sparse tree ensembles that support nonlinear feature selection and interpretable machine learning. The algorithms in this package first build large tree ensembles that prioritize basis functions with few features and then select a feature-sparse subset of these basis functions using a weighted lasso optimization criterion. The package includes visualizations to analyze the features selected by the ensemble and their impact on predictions. Hence ControlBurn offers the accuracy and flexibility of tree-ensemble models and the interpretability of sparse generalized additive models. ControlBurn is scalable and flexible: for example, it can use warm-start continuation to compute the regularization path (prediction error for any number of selected features) for a dataset with tens of thousands of samples and hundreds of features in seconds. For larger datasets, the runtime scales linearly in the number of samples and features (up to a log factor), and the package support acceleration using sketching. Moreover, the ControlBurn framework accommodates feature costs, feature groupings, and $\ell_0$-based regularizers. The package is user-friendly and open-source: its documentation and source code appear on https://pypi.org/project/ControlBurn/ and https://github.com/udellgroup/controlburn/.
ForestPrune: Compact Depth-Controlled Tree Ensembles
May 31, 2022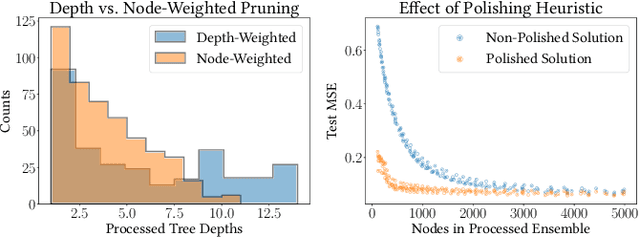

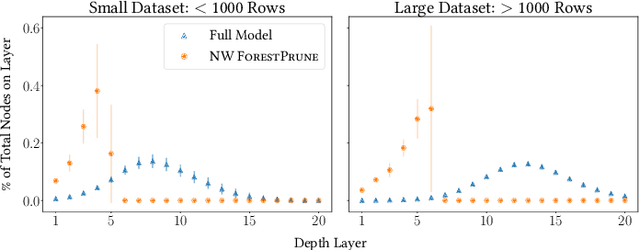
Tree ensembles are versatile supervised learning algorithms that achieve state-of-the-art performance. These models are extremely powerful but can grow to enormous sizes. As a result, tree ensembles are often post-processed to reduce memory footprint and improve interpretability. In this paper, we present ForestPrune, a novel optimization framework that can post-process tree ensembles by pruning depth layers from individual trees. We also develop a new block coordinate descent method to efficiently obtain high-quality solutions to optimization problems under this framework. The number of nodes in a decision tree increases exponentially with tree depth, so pruning deep trees can drastically improve model parsimony. ForestPrune can substantially reduce the space complexity of an ensemble for a minimal cost to performance. The framework supports various weighting schemes and contains just a single hyperparameter to tune. In our experiments, we observe that ForestPrune can reduce model size 20-fold with negligible performance loss.
ControlBurn: Feature Selection by Sparse Forests
Jul 01, 2021
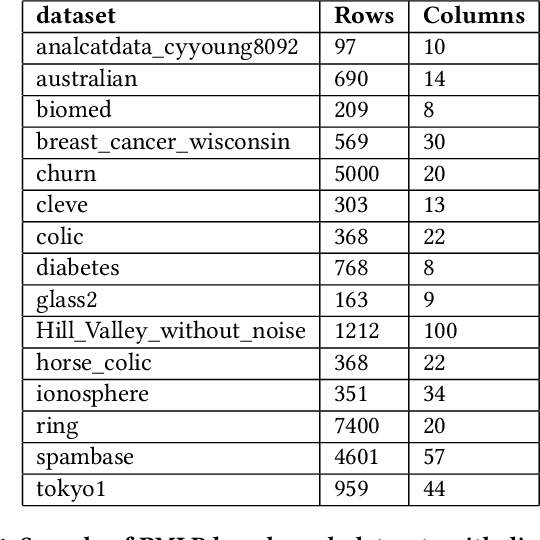
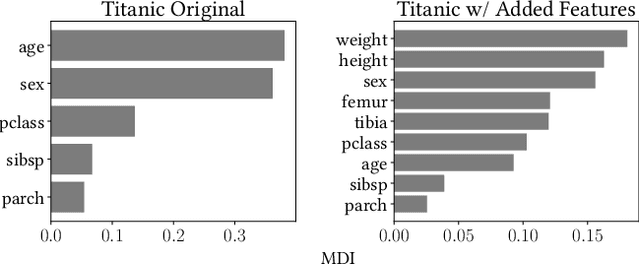
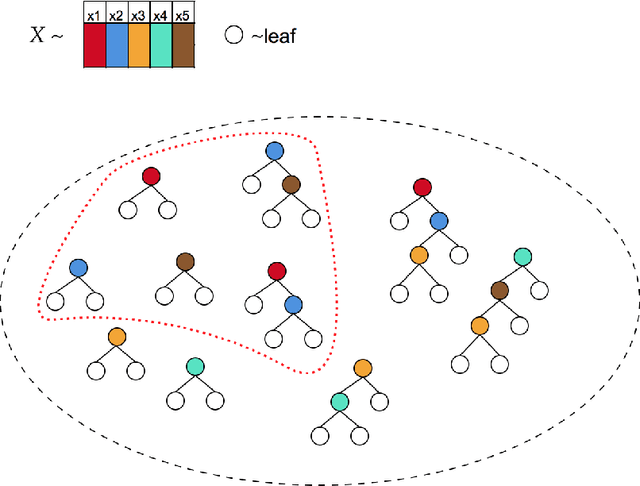
Tree ensembles distribute feature importance evenly amongst groups of correlated features. The average feature ranking of the correlated group is suppressed, which reduces interpretability and complicates feature selection. In this paper we present ControlBurn, a feature selection algorithm that uses a weighted LASSO-based feature selection method to prune unnecessary features from tree ensembles, just as low-intensity fire reduces overgrown vegetation. Like the linear LASSO, ControlBurn assigns all the feature importance of a correlated group of features to a single feature. Moreover, the algorithm is efficient and only requires a single training iteration to run, unlike iterative wrapper-based feature selection methods. We show that ControlBurn performs substantially better than feature selection methods with comparable computational costs on datasets with correlated features.