 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Heads Are Better Than One: Integrating Knowledge from Knowledge Graphs and Large Language Models for Entity Alignment
Jan 30, 2024Entity alignment, which is a prerequisite for creating a more comprehensive Knowledge Graph (KG), involves pinpointing equivalent entities across disparate KGs. Contemporary methods for entity alignment have predominantly utilized knowledge embedding models to procure entity embeddings that encapsulate various similarities-structural, relational, and attributive. These embeddings are then integrated through attention-based information fusion mechanisms. Despite this progress, effectively harnessing multifaceted information remains challenging due to inherent heterogeneity. Moreover, while Large Language Models (LLMs) have exhibited exceptional performance across diverse downstream tasks by implicitly capturing entity semantics, this implicit knowledge has yet to be exploited for entity alignment. In this study, we propose a Large Language Model-enhanced Entity Alignment framework (LLMEA), integrating structural knowledge from KGs with semantic knowledge from LLMs to enhance entity alignment. Specifically, LLMEA identifies candidate alignments for a given entity by considering both embedding similarities between entities across KGs and edit distances to a virtual equivalent entity. It then engages an LLM iteratively, posing multiple multi-choice questions to draw upon the LLM's inference capability. The final prediction of the equivalent entity is derived from the LLM's output. Experiments conducted on three public datasets reveal that LLMEA surpasses leading baseline models. Additional ablation studies underscore the efficacy of our proposed framework.
Enhancing Traffic Object Detection in Variable Illumination with RGB-Event Fusion
Nov 01, 2023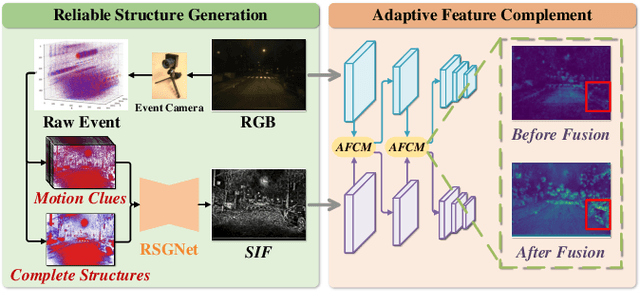

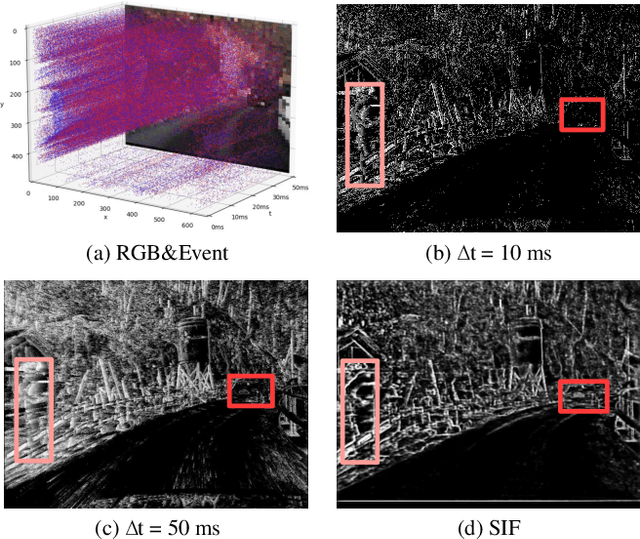
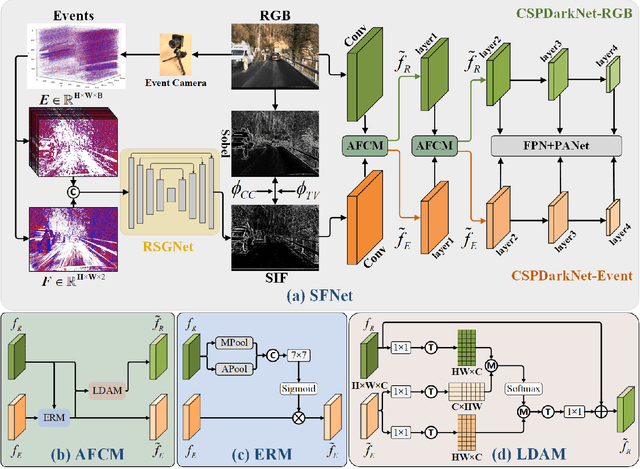
Traffic object detection under variable illumination is challenging due to the information loss caused by the limited dynamic range of conventional frame-based cameras. To address this issue, we introduce bio-inspired event cameras and propose a novel Structure-aware Fusion Network (SFNet) that extracts sharp and complete object structures from the event stream to compensate for the lost information in images through cross-modality fusion, enabling the network to obtain illumination-robust representations for traffic object detection. Specifically, to mitigate the sparsity or blurriness issues arising from diverse motion states of traffic objects in fixed-interval event sampling methods, we propose the Reliable Structure Generation Network (RSGNet) to generate Speed Invariant Frames (SIF), ensuring the integrity and sharpness of object structures. Next, we design a novel Adaptive Feature Complement Module (AFCM) which guides the adaptive fusion of two modality features to compensate for the information loss in the images by perceiving the global lightness distribution of the images, thereby generating illumination-robust representations. Finally, considering the lack of large-scale and high-quality annotations in the existing event-based object detection datasets, we build a DSEC-Det dataset, which consists of 53 sequences with 63,931 images and more than 208,000 labels for 8 classes. Extensive experimental results demonstrate that our proposed SFNet can overcome the perceptual boundaries of conventional cameras and outperform the frame-based method by 8.0% in mAP50 and 5.9% in mAP50:95. Our code and dataset will be available at https://github.com/YN-Yang/SFNet.
HPL-ViT: A Unified Perception Framework for Heterogeneous Parallel LiDARs in V2V
Sep 27, 2023



To develop the next generation of intelligent LiDARs, we propose a novel framework of parallel LiDARs and construct a hardware prototype in our experimental platform, DAWN (Digital Artificial World for Natural). It emphasizes the tight integration of physical and digital space in LiDAR systems, with networking being one of its supported core features. In the context of autonomous driving, V2V (Vehicle-to-Vehicle) technology enables efficient information sharing between different agents which significantly promotes the development of LiDAR networks. However, current research operates under an ideal situation where all vehicles are equipped with identical LiDAR, ignoring the diversity of LiDAR categories and operating frequencies. In this paper, we first utilize OpenCDA and RLS (Realistic LiDAR Simulation) to construct a novel heterogeneous LiDAR dataset named OPV2V-HPL. Additionally, we present HPL-ViT, a pioneering architecture designed for robust feature fusion in heterogeneous and dynamic scenarios. It uses a graph-attention Transformer to extract domain-specific features for each agent, coupled with a cross-attention mechanism for the final fusion. Extensive experiments on OPV2V-HPL demonstrate that HPL-ViT achieves SOTA (state-of-the-art) performance in all settings and exhibits outstanding generalization capabilities.
Towards Integrated Traffic Control with Operating Decentralized Autonomous Organization
Jul 25, 2023



With a growing complexity of the intelligent traffic system (ITS), an integrated control of ITS that is capable of considering plentiful heterogeneous intelligent agents is desired. However, existing control methods based on the centralized or the decentralized scheme have not presented their competencies in considering the optimality and the scalability simultaneously. To address this issue, we propose an integrated control method based on the framework of Decentralized Autonomous Organization (DAO). The proposed method achieves a global consensus on energy consumption efficiency (ECE), meanwhile to optimize the local objectives of all involved intelligent agents, through a consensus and incentive mechanism. Furthermore, an operation algorithm is proposed regarding the issue of structural rigidity in DAO. Specifically, the proposed operation approach identifies critical agents to execute the smart contract in DAO, which ultimately extends the capability of DAO-based control. In addition, a numerical experiment is designed to examine the performance of the proposed method. The experiment results indicate that the controlled agents can achieve a consensus faster on the global objective with improved local objectives by the proposed method, compare to existing decentralized control methods. In general, the proposed method shows a great potential in developing an integrated control system in the ITS
IR Design for Application-Specific Natural Language: A Case Study on Traffic Data
Jul 13, 2023



In the realm of software applications in the transportation industry, Domain-Specific Languages (DSLs) have enjoyed widespread adoption due to their ease of use and various other benefits. With the ceaseless progress in computer performance and the rapid development of large-scale models, the possibility of programming using natural language in specified applications - referred to as Application-Specific Natural Language (ASNL) - has emerged. ASNL exhibits greater flexibility and freedom, which, in turn, leads to an increase in computational complexity for parsing and a decrease in processing performance. To tackle this issue, our paper advances a design for an intermediate representation (IR) that caters to ASNL and can uniformly process transportation data into graph data format, improving data processing performance. Experimental comparisons reveal that in standard data query operations, our proposed IR design can achieve a speed improvement of over forty times compared to direct usage of standard XML format data.
Milestones in Autonomous Driving and Intelligent Vehicles Part II: Perception and Planning
Jun 03, 2023



Growing interest in autonomous driving (AD) and intelligent vehicles (IVs) is fueled by their promise for enhanced safety, efficiency, and economic benefits. While previous surveys have captured progress in this field, a comprehensive and forward-looking summary is needed. Our work fills this gap through three distinct articles. The first part, a "Survey of Surveys" (SoS), outlines the history, surveys, ethics, and future directions of AD and IV technologies. The second part, "Milestones in Autonomous Driving and Intelligent Vehicles Part I: Control, Computing System Design, Communication, HD Map, Testing, and Human Behaviors" delves into the development of control, computing system, communication, HD map, testing, and human behaviors in IVs. This part, the third part, reviews perception and planning in the context of IVs. Aiming to provide a comprehensive overview of the latest advancements in AD and IVs, this work caters to both newcomers and seasoned researchers. By integrating the SoS and Part I, we offer unique insights and strive to serve as a bridge between past achievements and future possibilities in this dynamic field.
TransWorldNG: Traffic Simulation via Foundation Model
May 25, 2023



Traffic simulation is a crucial tool for transportation decision-making and policy development. However, achieving realistic simulations in the face of the high dimensionality and heterogeneity of traffic environments is a longstanding challenge. In this paper, we present TransWordNG, a traffic simulator that uses Data-driven algorithms and Graph Computing techniques to learn traffic dynamics from real data. The functionality and structure of TransWorldNG are introduced, which utilize a foundation model for transportation management and control. The results demonstrate that TransWorldNG can generate more realistic traffic patterns compared to traditional simulators. Additionally, TransWorldNG exhibits better scalability, as it shows linear growth in computation time as the scenario scale increases. To the best of our knowledge, this is the first traffic simulator that can automatically learn traffic patterns from real-world data and efficiently generate accurate and realistic traffic environments.
Milestones in Autonomous Driving and Intelligent Vehicles Part \uppercase\expandafter{\romannumeral1}: Control, Computing System Design, Communication, HD Map, Testing, and Human Behaviors
May 12, 2023



Interest in autonomous driving (AD) and intelligent vehicles (IVs) is growing at a rapid pace due to the convenience, safety, and economic benefits. Although a number of surveys have reviewed research achievements in this field, they are still limited in specific tasks and lack systematic summaries and research directions in the future. Our work is divided into 3 independent articles and the first part is a Survey of Surveys (SoS) for total technologies of AD and IVs that involves the history, summarizes the milestones, and provides the perspectives, ethics, and future research directions. This is the second part (Part \uppercase\expandafter{\romannumeral1} for this technical survey) to review the development of control, computing system design, communication, High Definition map (HD map), testing, and human behaviors in IVs. In addition, the third part (Part \uppercase\expandafter{\romannumeral2} for this technical survey) is to review the perception and planning sections. The objective of this paper is to involve all the sections of AD, summarize the latest technical milestones, and guide abecedarians to quickly understand the development of AD and IVs. Combining the SoS and Part \uppercase\expandafter{\romannumeral2}, we anticipate that this work will bring novel and diverse insights to researchers and abecedarians, and serve as a bridge between past and future.
* 18 pages, 4 figures, 3 tables
Milestones in Autonomous Driving and Intelligent Vehicles: Survey of Surveys
Mar 30, 2023



Interest in autonomous driving (AD) and intelligent vehicles (IVs) is growing at a rapid pace due to the convenience, safety, and economic benefits. Although a number of surveys have reviewed research achievements in this field, they are still limited in specific tasks, lack of systematic summary and research directions in the future. Here we propose a Survey of Surveys (SoS) for total technologies of AD and IVs that reviews the history, summarizes the milestones, and provides the perspectives, ethics, and future research directions. To our knowledge, this article is the first SoS with milestones in AD and IVs, which constitutes our complete research work together with two other technical surveys. We anticipate that this article will bring novel and diverse insights to researchers and abecedarians, and serve as a bridge between past and future.
* 13 pages, 3 tables, 0 figure
Conservative-Progressive Collaborative Learning for Semi-supervised Semantic Segmentation
Nov 30, 2022Pseudo supervision is regarded as the core idea in semi-supervised learning for semantic segmentation, and there is always a tradeoff between utilizing only the high-quality pseudo labels and leveraging all the pseudo labels. Addressing that, we propose a novel learning approach, called Conservative-Progressive Collaborative Learning (CPCL), among which two predictive networks are trained in parallel, and the pseudo supervision is implemented based on both the agreement and disagreement of the two predictions. One network seeks common ground via intersection supervision and is supervised by the high-quality labels to ensure a more reliable supervision, while the other network reserves differences via union supervision and is supervised by all the pseudo labels to keep exploring with curiosity. Thus, the collaboration of conservative evolution and progressive exploration can be achieved. To reduce the influences of the suspicious pseudo labels, the loss is dynamic re-weighted according to the prediction confidence. Extensive experiments demonstrate that CPCL achieves state-of-the-art performance for semi-supervised semantic segmentation.