 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution Shift Is Key to Learning Invariant Prediction
Jan 18, 2026An interesting phenomenon arises: Empirical Risk Minimization (ERM) sometimes outperforms methods specifically designed for out-of-distribution tasks. This motivates an investigation into the reasons behind such behavior beyond algorithmic design. In this study, we find that one such reason lies in the distribution shift across training domains. A large degree of distribution shift can lead to better performance even under ERM. Specifically, we derive several theoretical and empirical findings demonstrating that distribution shift plays a crucial role in model learning and benefits learning invariant prediction. Firstly, the proposed upper bounds indicate that the degree of distribution shift directly affects the prediction ability of the learned models. If it is large, the models' ability can increase, approximating invariant prediction models that make stable predictions under arbitrary known or unseen domains; and vice versa. We also prove that, under certain data conditions, ERM solutions can achieve performance comparable to that of invariant prediction models. Secondly, the empirical validation results demonstrated that the predictions of learned models approximate those of Oracle or Optimal models, provided that the degree of distribution shift in the training data increases.
Hallucinating 360°: Panoramic Street-View Generation via Local Scenes Diffusion and Probabilistic Prompting
Jul 09, 2025



Panoramic perception holds significant potential for autonomous driving, enabling vehicles to acquire a comprehensive 360{\deg} surround view in a single shot. However, autonomous driving is a data-driven task. Complete panoramic data acquisition requires complex sampling systems and annotation pipelines, which are time-consuming and labor-intensive. Although existing street view generation models have demonstrated strong data regeneration capabilities, they can only learn from the fixed data distribution of existing datasets and cannot achieve high-quality, controllable panoramic generation. In this paper, we propose the first panoramic generation method Percep360 for autonomous driving. Percep360 enables coherent generation of panoramic data with control signals based on the stitched panoramic data. Percep360 focuses on two key aspects: coherence and controllability. Specifically, to overcome the inherent information loss caused by the pinhole sampling process, we propose the Local Scenes Diffusion Method (LSDM). LSDM reformulates the panorama generation as a spatially continuous diffusion process, bridging the gaps between different data distributions. Additionally, to achieve the controllable generation of panoramic images, we propose a Probabilistic Prompting Method (PPM). PPM dynamically selects the most relevant control cues, enabling controllable panoramic image generation. We evaluate the effectiveness of the generated images from three perspectives: image quality assessment (i.e., no-reference and with reference), controllability, and their utility in real-world Bird's Eye View (BEV) segmentation. Notably, the generated data consistently outperforms the original stitched images in no-reference quality metrics and enhances downstream perception models. The source code will be publicly available at https://github.com/Bryant-Teng/Percep360.
LAPSO: A Unified Optimization View for Learning-Augmented Power System Operations
May 08, 2025With the high penetration of renewables, traditional model-based power system operation is challenged to deliver economic, stable, and robust decisions. Machine learning has emerged as a powerful modeling tool for capturing complex dynamics to address these challenges. However, its separate design often lacks systematic integration with existing methods. To fill the gap, this paper proposes a holistic framework of Learning-Augmented Power System Operations (LAPSO, pronounced as Lap-So). Adopting a native optimization perspective, LAPSO is centered on the operation stage and aims to break the boundary between temporally siloed power system tasks, such as forecast, operation and control, while unifying the objectives of machine learning and model-based optimizations at both training and inference stages. Systematic analysis and simulations demonstrate the effectiveness of applying LAPSO in designing new integrated algorithms, such as stability-constrained optimization (SCO) and objective-based forecasting (OBF), while enabling end-to-end tracing of different sources of uncertainties. In addition, a dedicated Python package-lapso is introduced to automatically augment existing power system optimization models with learnable components. All code and data are available at https://github.com/xuwkk/lapso_exp.
Panoramic Out-of-Distribution Segmentation
May 06, 2025Panoramic imaging enables capturing 360{\deg} images with an ultra-wide Field-of-View (FoV) for dense omnidirectional perception. However, current panoramic semantic segmentation methods fail to identify outliers, and pinhole Out-of-distribution Segmentation (OoS) models perform unsatisfactorily in the panoramic domain due to background clutter and pixel distortions. To address these issues, we introduce a new task, Panoramic Out-of-distribution Segmentation (PanOoS), achieving OoS for panoramas. Furthermore, we propose the first solution, POS, which adapts to the characteristics of panoramic images through text-guided prompt distribution learning. Specifically, POS integrates a disentanglement strategy designed to materialize the cross-domain generalization capability of CLIP. The proposed Prompt-based Restoration Attention (PRA) optimizes semantic decoding by prompt guidance and self-adaptive correction, while Bilevel Prompt Distribution Learning (BPDL) refines the manifold of per-pixel mask embeddings via semantic prototype supervision. Besides, to compensate for the scarcity of PanOoS datasets, we establish two benchmarks: DenseOoS, which features diverse outliers in complex environments, and QuadOoS, captured by a quadruped robot with a panoramic annular lens system. Extensive experiments demonstrate superior performance of POS, with AuPRC improving by 34.25% and FPR95 decreasing by 21.42% on DenseOoS, outperforming state-of-the-art pinhole-OoS methods. Moreover, POS achieves leading closed-set segmentation capabilities. Code and datasets will be available at https://github.com/MengfeiD/PanOoS.
Out-of-Distribution Generalization in Time Series: A Survey
Mar 18, 2025



Time series frequently manifest distribution shifts, diverse latent features, and non-stationary learning dynamics, particularly in open and evolving environments. These characteristics pose significant challenges for out-of-distribution (OOD) generalization. While substantial progress has been made, a systematic synthesis of advancements remains lacking. To address this gap, we present the first comprehensive review of OOD generalization methodologies for time series, organized to delineate the field's evolutionary trajectory and contemporary research landscape. We organize our analysis across three foundational dimensions: data distribution, representation learning, and OOD evaluation. For each dimension, we present several popular algorithms in detail. Furthermore, we highlight key application scenarios, emphasizing their real-world impact. Finally, we identify persistent challenges and propose future research directions. A detailed summary of the methods reviewed for the generalization of OOD in time series can be accessed at https://tsood-generalization.com.
Variational Bayesian Personalized Ranking
Mar 14, 2025Recommendation systems have found extensive applications across diverse domains. However, the training data available typically comprises implicit feedback, manifested as user clicks and purchase behaviors, rather than explicit declarations of user preferences. This type of training data presents three main challenges for accurate ranking prediction: First, the unobservable nature of user preferences makes likelihood function modeling inherently difficult. Second, the resulting false positives (FP) and false negatives (FN) introduce noise into the learning process, disrupting parameter learning. Third, data bias arises as observed interactions tend to concentrate on a few popular items, exacerbating the feedback loop of popularity bias. To address these issues, we propose Variational BPR, a novel and easily implementable learning objective that integrates key components for enhancing collaborative filtering: likelihood optimization, noise reduction, and popularity debiasing. Our approach involves decomposing the pairwise loss under the ELBO-KL framework and deriving its variational lower bound to establish a manageable learning objective for approximate inference. Within this bound, we introduce an attention-based latent interest prototype contrastive mechanism, replacing instance-level contrastive learning, to effectively reduce noise from problematic samples. The process of deriving interest prototypes implicitly incorporates a flexible hard sample mining strategy, capable of simultaneously identifying hard positive and hard negative samples. Furthermore, we demonstrate that this hard sample mining strategy promotes feature distribution uniformity, thereby alleviating popularity bias. Empirically, we demonstrate the effectiveness of Variational BPR on popular backbone recommendation models. The code and data are available at: https://github.com/liubin06/VariationalBPR
Omnidirectional Multi-Object Tracking
Mar 06, 2025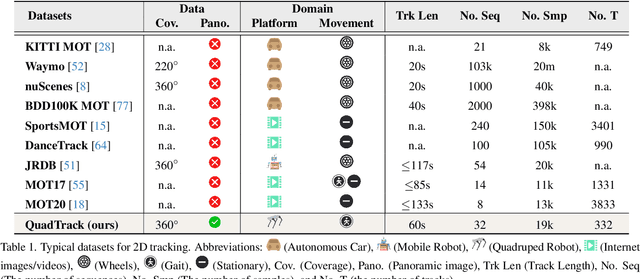
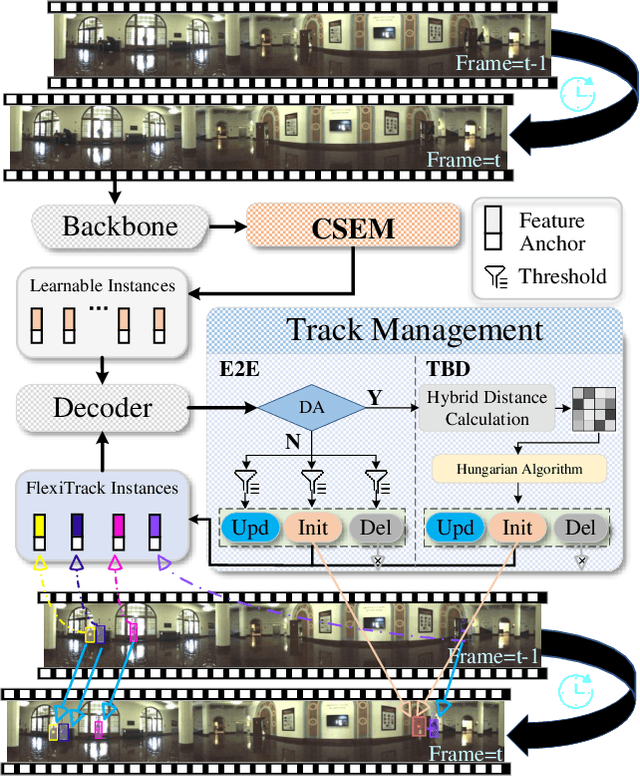
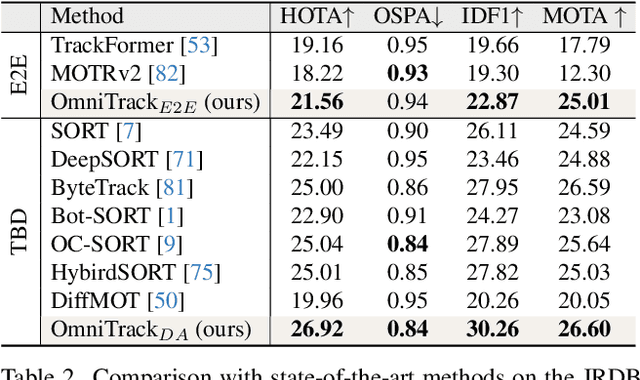
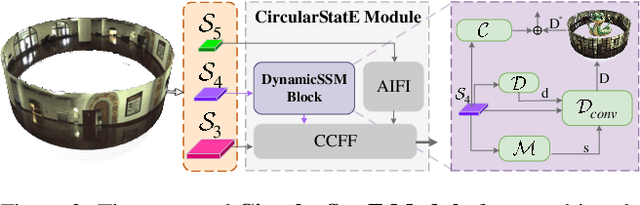
Panoramic imagery, with its 360{\deg} field of view, offers comprehensive information to support Multi-Object Tracking (MOT) in capturing spatial and temporal relationships of surrounding objects. However, most MOT algorithms are tailored for pinhole images with limited views, impairing their effectiveness in panoramic settings. Additionally, panoramic image distortions, such as resolution loss, geometric deformation, and uneven lighting, hinder direct adaptation of existing MOT methods, leading to significant performance degradation. To address these challenges, we propose OmniTrack, an omnidirectional MOT framework that incorporates Tracklet Management to introduce temporal cues, FlexiTrack Instances for object localization and association, and the CircularStatE Module to alleviate image and geometric distortions. This integration enables tracking in large field-of-view scenarios, even under rapid sensor motion. To mitigate the lack of panoramic MOT datasets, we introduce the QuadTrack dataset--a comprehensive panoramic dataset collected by a quadruped robot, featuring diverse challenges such as wide fields of view, intense motion, and complex environments. Extensive experiments on the public JRDB dataset and the newly introduced QuadTrack benchmark demonstrate the state-of-the-art performance of the proposed framework. OmniTrack achieves a HOTA score of 26.92% on JRDB, representing an improvement of 3.43%, and further achieves 23.45% on QuadTrack, surpassing the baseline by 6.81%. The dataset and code will be made publicly available at https://github.com/xifen523/OmniTrack.
Unveiling the Potential of Segment Anything Model 2 for RGB-Thermal Semantic Segmentation with Language Guidance
Mar 04, 2025The perception capability of robotic systems relies on the richness of the dataset. Although Segment Anything Model 2 (SAM2), trained on large datasets, demonstrates strong perception potential in perception tasks, its inherent training paradigm prevents it from being suitable for RGB-T tasks. To address these challenges, we propose SHIFNet, a novel SAM2-driven Hybrid Interaction Paradigm that unlocks the potential of SAM2 with linguistic guidance for efficient RGB-Thermal perception. Our framework consists of two key components: (1) Semantic-Aware Cross-modal Fusion (SACF) module that dynamically balances modality contributions through text-guided affinity learning, overcoming SAM2's inherent RGB bias; (2) Heterogeneous Prompting Decoder (HPD) that enhances global semantic information through a semantic enhancement module and then combined with category embeddings to amplify cross-modal semantic consistency. With 32.27M trainable parameters, SHIFNet achieves state-of-the-art segmentation performance on public benchmarks, reaching 89.8% on PST900 and 67.8% on FMB, respectively. The framework facilitates the adaptation of pre-trained large models to RGB-T segmentation tasks, effectively mitigating the high costs associated with data collection while endowing robotic systems with comprehensive perception capabilities. The source code will be made publicly available at https://github.com/iAsakiT3T/SHIFNet.
Beyond Fixed Variables: Expanding-variate Time Series Forecasting via Flat Scheme and Spatio-temporal Focal Learning
Feb 21, 2025Multivariate Time Series Forecasting (MTSF) has long been a key research focus. Traditionally, these studies assume a fixed number of variables, but in real-world applications, Cyber-Physical Systems often expand as new sensors are deployed, increasing variables in MTSF. In light of this, we introduce a novel task, Expanding-variate Time Series Forecasting (EVTSF). This task presents unique challenges, specifically (1) handling inconsistent data shapes caused by adding new variables, and (2) addressing imbalanced spatio-temporal learning, where expanding variables have limited observed data due to the necessity for timely operation. To address these challenges, we propose STEV, a flexible spatio-temporal forecasting framework. STEV includes a new Flat Scheme to tackle the inconsistent data shape issue, which extends the graph-based spatio-temporal modeling architecture into 1D space by flattening the 2D samples along the variable dimension, making the model variable-scale-agnostic while still preserving dynamic spatial correlations through a holistic graph. We introduce a novel Spatio-temporal Focal Learning strategy that incorporates a negative filter to resolve potential conflicts between contrastive learning and graph representation, and a focal contrastive loss as its core to guide the framework to focus on optimizing the expanding variables. We benchmark EVTSF performance using three real-world datasets and compare it against three potential solutions employing SOTA MTSF models tailored for EVSTF. Experimental results show that STEV significantly outperforms its competitors, particularly on expanding variables. Notably, STEV, with only 5% of observations from the expanding period, is on par with SOTA MTSF models trained with complete observations. Further exploration of various expanding strategies underscores the generalizability of STEV in real-world applications.
Graph-based Retrieval Augmented Generation for Dynamic Few-shot Text Classification
Jan 06, 2025



Text classification is a fundamental task in natural language processing, pivotal to various applications such as query optimization, data integration, and schema matching. While neural network-based models, such as CNN and BERT, have demonstrated remarkable performance in text classification, their effectiveness heavily relies on abundant labeled training data. This dependency makes these models less effective in dynamic few-shot text classification, where labeled data is scarce, and target labels frequently evolve based on application needs. Recently, large language models (LLMs) have shown promise due to their extensive pretraining and contextual understanding. Current approaches provide LLMs with text inputs, candidate labels, and additional side information (e.g., descriptions) to predict text labels. However, their effectiveness is hindered by the increased input size and the noise introduced through side information processing. To address these limitations, we propose a graph-based online retrieval-augmented generation framework, namely GORAG, for dynamic few-shot text classification. GORAG constructs and maintains an adaptive information graph by extracting side information across all target texts, rather than treating each input independently. It employs a weighted edge mechanism to prioritize the importance and reliability of extracted information and dynamically retrieves relevant context using a minimum-cost spanning tree tailored for each text input. Empirical evaluations demonstrate that GORAG outperforms existing approaches by providing more comprehensive and accurate contextual information.