 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Bayesian Personalized Ranking
Mar 14, 2025Recommendation systems have found extensive applications across diverse domains. However, the training data available typically comprises implicit feedback, manifested as user clicks and purchase behaviors, rather than explicit declarations of user preferences. This type of training data presents three main challenges for accurate ranking prediction: First, the unobservable nature of user preferences makes likelihood function modeling inherently difficult. Second, the resulting false positives (FP) and false negatives (FN) introduce noise into the learning process, disrupting parameter learning. Third, data bias arises as observed interactions tend to concentrate on a few popular items, exacerbating the feedback loop of popularity bias. To address these issues, we propose Variational BPR, a novel and easily implementable learning objective that integrates key components for enhancing collaborative filtering: likelihood optimization, noise reduction, and popularity debiasing. Our approach involves decomposing the pairwise loss under the ELBO-KL framework and deriving its variational lower bound to establish a manageable learning objective for approximate inference. Within this bound, we introduce an attention-based latent interest prototype contrastive mechanism, replacing instance-level contrastive learning, to effectively reduce noise from problematic samples. The process of deriving interest prototypes implicitly incorporates a flexible hard sample mining strategy, capable of simultaneously identifying hard positive and hard negative samples. Furthermore, we demonstrate that this hard sample mining strategy promotes feature distribution uniformity, thereby alleviating popularity bias. Empirically, we demonstrate the effectiveness of Variational BPR on popular backbone recommendation models. The code and data are available at: https://github.com/liubin06/VariationalBPR
Large-scale Regional Traffic Signal Control Based on Single-Agent Reinforcement Learning
Mar 12, 2025



In the context of global urbanization and motorization, traffic congestion has become a significant issue, severely affecting the quality of life, environment, and economy. This paper puts forward a single-agent reinforcement learning (RL)-based regional traffic signal control (TSC) model. Different from multi - agent systems, this model can coordinate traffic signals across a large area, with the goals of alleviating regional traffic congestion and minimizing the total travel time. The TSC environment is precisely defined through specific state space, action space, and reward functions. The state space consists of the current congestion state, which is represented by the queue lengths of each link, and the current signal phase scheme of intersections. The action space is designed to select an intersection first and then adjust its phase split. Two reward functions are meticulously crafted. One focuses on alleviating congestion and the other aims to minimize the total travel time while considering the congestion level. The experiments are carried out with the SUMO traffic simulation software. The performance of the TSC model is evaluated by comparing it with a base case where no signal-timing adjustments are made. The results show that the model can effectively control congestion. For example, the queuing length is significantly reduced in the scenarios tested. Moreover, when the reward is set to both alleviate congestion and minimize the total travel time, the average travel time is remarkably decreased, which indicates that the model can effectively improve traffic conditions. This research provides a new approach for large-scale regional traffic signal control and offers valuable insights for future urban traffic management.
DreamerV3 for Traffic Signal Control: Hyperparameter Tuning and Performance
Mar 04, 2025



Reinforcement learning (RL) has evolved into a widely investigated technology for the development of smart TSC strategies. However, current RL algorithms necessitate excessive interaction with the environment to learn effective policies, making them impractical for large-scale tasks. The DreamerV3 algorithm presents compelling properties for policy learning. It summarizes general dynamics knowledge about the environment and enables the prediction of future outcomes of potential actions from past experience, reducing the interaction with the environment through imagination training. In this paper, a corridor TSC model is trained using the DreamerV3 algorithm to explore the benefits of world models for TSC strategy learning. In RL environment design, to manage congestion levels effectively, both the state and reward functions are defined based on queue length, and the action is designed to manage queue length efficiently. Using the SUMO simulation platform, the two hyperparameters (training ratio and model size) of the DreamerV3 algorithm were tuned and analyzed across different OD matrix scenarios. We discovered that choosing a smaller model size and initially attempting several medium training ratios can significantly reduce the time spent on hyperparameter tuning. Additionally, we found that the approach is generally applicable as it can solve two TSC task scenarios with the same hyperparameters. Regarding the claimed data-efficiency of the DreamerV3 algorithm, due to the significant fluctuation of the episode reward curve in the early stages of training, it can only be confirmed that larger model sizes exhibit modest data-efficiency, and no evidence was found that increasing the training ratio accelerates convergence.
A Prompt Refinement-based Large Language Model for Metro Passenger Flow Forecasting under Delay Conditions
Oct 19, 2024



Accurate short-term forecasts of passenger flow in metro systems under delay conditions are crucial for emergency response and service recovery, which pose significant challenges and are currently under-researched. Due to the rare occurrence of delay events, the limited sample size under delay condictions make it difficult for conventional models to effectively capture the complex impacts of delays on passenger flow, resulting in low forecasting accuracy. Recognizing the strengths of large language models (LLMs) in few-shot learning due to their powerful pre-training, contextual understanding, ability to perform zero-shot and few-shot reasoning, to address the issues that effectively generalize and adapt with minimal data, we propose a passenger flow forecasting framework under delay conditions that synthesizes an LLM with carefully designed prompt engineering. By Refining prompt design, we enable the LLM to understand delay event information and the pattern from historical passenger flow data, thus overcoming the challenges of passenger flow forecasting under delay conditions. The propmpt engineering in the framework consists of two main stages: systematic prompt generation and prompt refinement. In the prompt generation stage, multi-source data is transformed into descriptive texts understandable by the LLM and stored. In the prompt refinement stage, we employ the multidimensional Chain of Thought (CoT) method to refine the prompts. We verify the proposed framework by conducting experiments using real-world datasets specifically targeting passenger flow forecasting under delay conditions of Shenzhen metro in China. The experimental results demonstrate that the proposed model performs particularly well in forecasting passenger flow under delay conditions.
Debiased Pairwise Learning from Positive-Unlabeled Implicit Feedback
Jul 29, 2023



Learning contrastive representations from pairwise comparisons has achieved remarkable success in various fields, such as natural language processing, computer vision, and information retrieval. Collaborative filtering algorithms based on pairwise learning also rooted in this paradigm. A significant concern is the absence of labels for negative instances in implicit feedback data, which often results in the random selected negative instances contains false negatives and inevitably, biased embeddings. To address this issue, we introduce a novel correction method for sampling bias that yields a modified loss for pairwise learning called debiased pairwise loss (DPL). The key idea underlying DPL is to correct the biased probability estimates that result from false negatives, thereby correcting the gradients to approximate those of fully supervised data. The implementation of DPL only requires a small modification of the codes. Experimental studies on five public datasets validate the effectiveness of proposed learning method.
Towards Unbiased Random Features with Lower Variance For Stationary Indefinite Kernels
Apr 14, 2021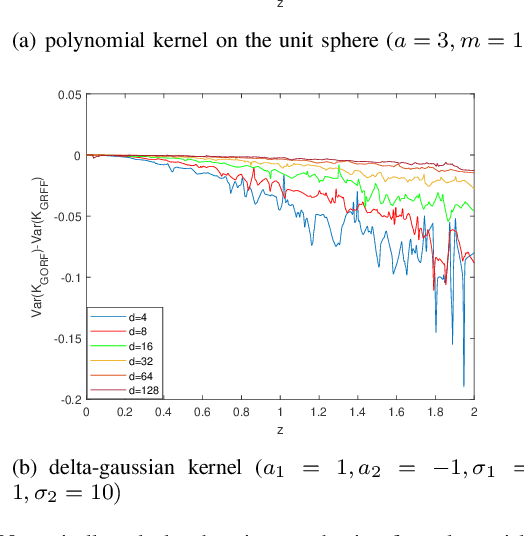
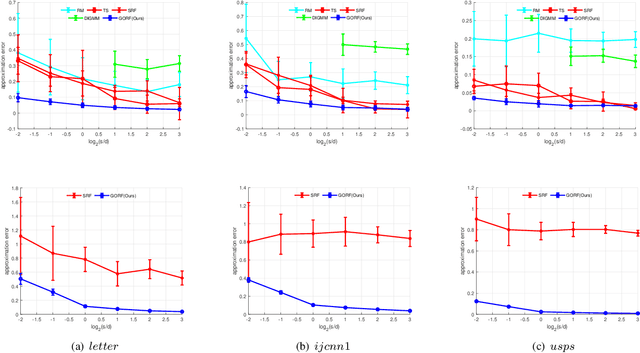
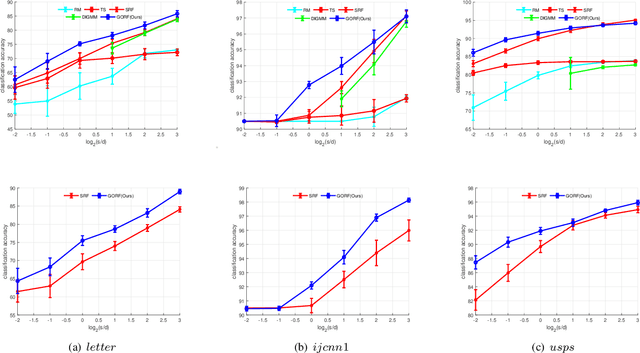
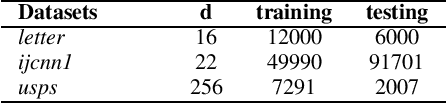
Random Fourier Features (RFF) demonstrate wellappreciated performance in kernel approximation for largescale situations but restrict kernels to be stationary and positive definite. And for non-stationary kernels, the corresponding RFF could be converted to that for stationary indefinite kernels when the inputs are restricted to the unit sphere. Numerous methods provide accessible ways to approximate stationary but indefinite kernels. However, they are either biased or possess large variance. In this article, we propose the generalized orthogonal random features, an unbiased estimation with lower variance.Experimental results on various datasets and kernels verify that our algorithm achieves lower variance and approximation error compared with the existing kernel approximation methods. With better approximation to the originally selected kernels, improved classification accuracy and regression ability is obtained with our approximation algorithm in the framework of support vector machine and regression.
Mixed-Precision Quantized Neural Network with Progressively Decreasing Bitwidth For Image Classification and Object Detection
Dec 29, 2019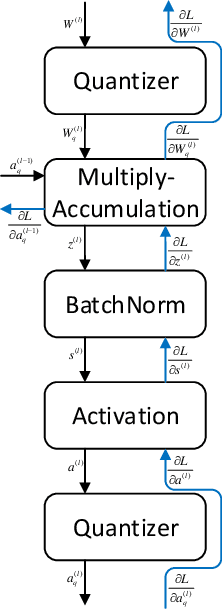
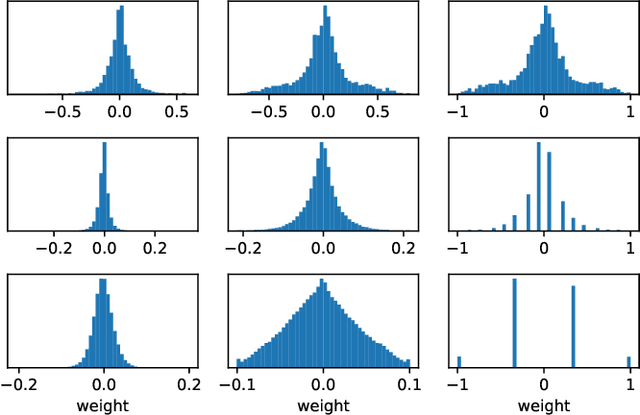
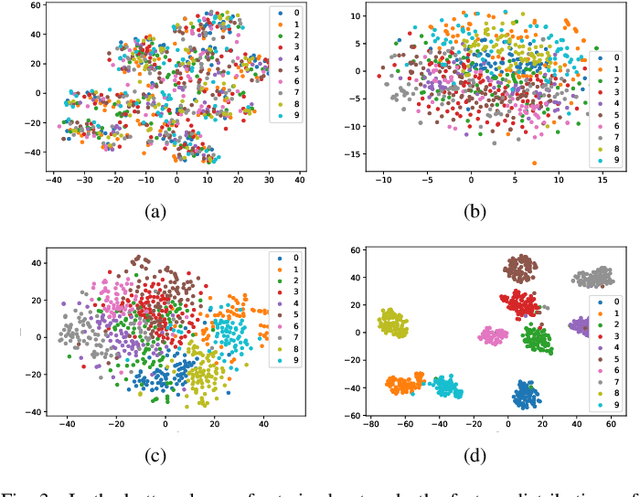
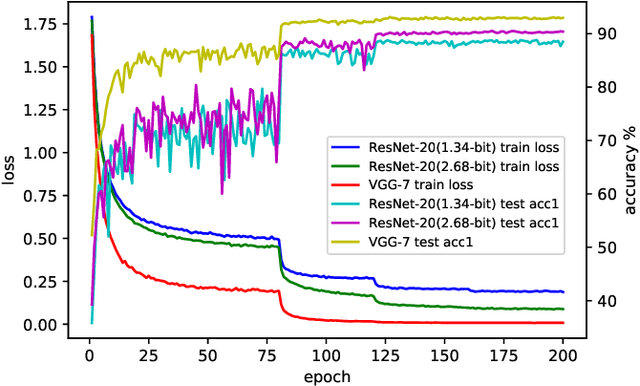
Efficient model inference is an important and practical issue in the deployment of deep neural network on resource constraint platforms. Network quantization addresses this problem effectively by leveraging low-bit representation and arithmetic that could be conducted on dedicated embedded systems. In the previous works, the parameter bitwidth is set homogeneously and there is a trade-off between superior performance and aggressive compression. Actually the stacked network layers, which are generally regarded as hierarchical feature extractors, contribute diversely to the overall performance. For a well-trained neural network, the feature distributions of different categories differentiate gradually as the network propagates forward. Hence the capability requirement on the subsequent feature extractors is reduced. It indicates that the neurons in posterior layers could be assigned with lower bitwidth for quantized neural networks. Based on this observation, a simple but effective mixed-precision quantized neural network with progressively ecreasing bitwidth is proposed to improve the trade-off between accuracy and compression. Extensive experiments on typical network architectures and benchmark datasets demonstrate that the proposed method could achieve better or comparable results while reducing the memory space for quantized parameters by more than 30\% in comparison with the homogeneous counterparts. In addition, the results also demonstrate that the higher-precision bottom layers could boost the 1-bit network performance appreciably due to a better preservation of the original image information while the lower-precision posterior layers contribute to the regularization of $k-$bit networks.