 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Learning for Generalized Vehicle Routing
May 20, 2024Neural combinatorial optimization (NCO) is a promising learning-based approach to solving various vehicle routing problems without much manual algorithm design. However, the current NCO methods mainly focus on the in-distribution performance, while the real-world problem instances usually come from different distributions. A costly fine-tuning approach or generalized model retraining from scratch could be needed to tackle the out-of-distribution instances. Unlike the existing methods, this work investigates an efficient prompt learning approach in NCO for cross-distribution adaptation. To be concrete, we propose a novel prompt learning method to facilitate fast zero-shot adaptation of a pre-trained model to solve routing problem instances from different distributions. The proposed model learns a set of prompts among various distributions and then selects the best-matched one to prompt a pre-trained attention model for each problem instance. Extensive experiments show that the proposed prompt learning approach facilitates the fast adaptation of pre-trained routing models. It also outperforms existing generalized models on both in-distribution prediction and zero-shot generalization to a diverse set of new tasks. Our code implementation is available online https://github.com/FeiLiu36/PromptVRP.
JIGGLE: An Active Sensing Framework for Boundary Parameters Estimation in Deformable Surgical Environments
May 16, 2024Surgical automation can improve the accessibility and consistency of life saving procedures. Most surgeries require separating layers of tissue to access the surgical site, and suturing to reattach incisions. These tasks involve deformable manipulation to safely identify and alter tissue attachment (boundary) topology. Due to poor visual acuity and frequent occlusions, surgeons tend to carefully manipulate the tissue in ways that enable inference of the tissue's attachment points without causing unsafe tearing. In a similar fashion, we propose JIGGLE, a framework for estimation and interactive sensing of unknown boundary parameters in deformable surgical environments. This framework has two key components: (1) a probabilistic estimation to identify the current attachment points, achieved by integrating a differentiable soft-body simulator with an extended Kalman filter (EKF), and (2) an optimization-based active control pipeline that generates actions to maximize information gain of the tissue attachments, while simultaneously minimizing safety costs. The robustness of our estimation approach is demonstrated through experiments with real animal tissue, where we infer sutured attachment points using stereo endoscope observations. We also demonstrate the capabilities of our method in handling complex topological changes such as cutting and suturing.
Evolve Cost-aware Acquisition Functions Using Large Language Models
Apr 25, 2024Many real-world optimization scenarios involve expensive evaluation with unknown and heterogeneous costs. Cost-aware Bayesian optimization stands out as a prominent solution in addressing these challenges. To approach the global optimum within a limited budget in a cost-efficient manner, the design of cost-aware acquisition functions (AFs) becomes a crucial step. However, traditional manual design paradigm typically requires extensive domain knowledge and involves a labor-intensive trial-and-error process. This paper introduces EvolCAF, a novel framework that integrates large language models (LLMs) with evolutionary computation (EC) to automatically design cost-aware AFs. Leveraging the crossover and mutation in the algorithm space, EvolCAF offers a novel design paradigm, significantly reduces the reliance on domain expertise and model training. The designed cost-aware AF maximizes the utilization of available information from historical data, surrogate models and budget details. It introduces novel ideas not previously explored in the existing literature on acquisition function design, allowing for clear interpretations to provide insights into its behavior and decision-making process. In comparison to the well-known EIpu and EI-cool methods designed by human experts, our approach showcases remarkable efficiency and generalization across various tasks, including 12 synthetic problems and 3 real-world hyperparameter tuning test sets.
Smooth Tchebycheff Scalarization for Multi-Objective Optimization
Mar 14, 2024



Multi-objective optimization problems can be found in many real-world applications, where the objectives often conflict each other and cannot be optimized by a single solution. In the past few decades, numerous methods have been proposed to find Pareto solutions that represent different optimal trade-offs among the objectives for a given problem. However, these existing methods could have high computational complexity or may not have good theoretical properties for solving a general differentiable multi-objective optimization problem. In this work, by leveraging the smooth optimization technique, we propose a novel and lightweight smooth Tchebycheff scalarization approach for gradient-based multi-objective optimization. It has good theoretical properties for finding all Pareto solutions with valid trade-off preferences, while enjoying significantly lower computational complexity compared to other methods. Experimental results on various real-world application problems fully demonstrate the effectiveness of our proposed method.
Robust Surgical Tool Tracking with Pixel-based Probabilities for Projected Geometric Primitives
Mar 08, 2024



Controlling robotic manipulators via visual feedback requires a known coordinate frame transformation between the robot and the camera. Uncertainties in mechanical systems as well as camera calibration create errors in this coordinate frame transformation. These errors result in poor localization of robotic manipulators and create a significant challenge for applications that rely on precise interactions between manipulators and the environment. In this work, we estimate the camera-to-base transform and joint angle measurement errors for surgical robotic tools using an image based insertion-shaft detection algorithm and probabilistic models. We apply our proposed approach in both a structured environment as well as an unstructured environment and measure to demonstrate the efficacy of our methods.
Can Large Language Models do Analytical Reasoning?
Mar 06, 2024

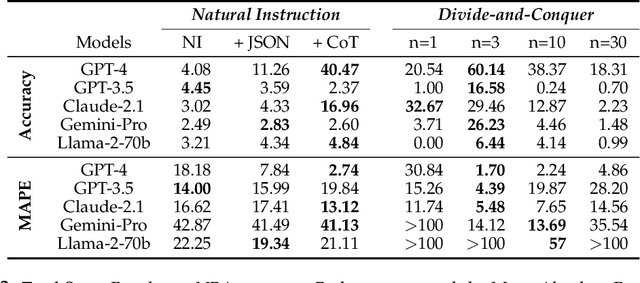
This paper explores the cutting-edge Large Language Model with analytical reasoning on sports. Our analytical reasoning embodies the tasks of letting large language models count how many points each team scores in a quarter in the NBA and NFL games. Our major discoveries are in two folds. Firstly, we find among all the models we employed, GPT-4 stands out in effectiveness, followed by Claude-2.1, with GPT-3.5, Gemini-Pro, and Llama-2-70b lagging behind. Specifically, we compare three different prompting techniques and a divide-and-conquer approach, we find that the latter was the most effective. Our divide-and-conquer approach breaks down play-by-play data into smaller, more manageable segments, solves each piece individually, and then aggregates them together. Besides the divide-and-conquer approach, we also explore the Chain of Thought (CoT) strategy, which markedly improves outcomes for certain models, notably GPT-4 and Claude-2.1, with their accuracy rates increasing significantly. However, the CoT strategy has negligible or even detrimental effects on the performance of other models like GPT-3.5 and Gemini-Pro. Secondly, to our surprise, we observe that most models, including GPT-4, struggle to accurately count the total scores for NBA quarters despite showing strong performance in counting NFL quarter scores. This leads us to further investigate the factors that impact the complexity of analytical reasoning tasks with extensive experiments, through which we conclude that task complexity depends on the length of context, the information density, and the presence of related information. Our research provides valuable insights into the complexity of analytical reasoning tasks and potential directions for developing future large language models.
Multi-Task Learning for Routing Problem with Cross-Problem Zero-Shot Generalization
Feb 23, 2024Vehicle routing problems (VRPs), which can be found in numerous real-world applications, have been an important research topic for several decades. Recently, the neural combinatorial optimization (NCO) approach that leverages a learning-based model to solve VRPs without manual algorithm design has gained substantial attention. However, current NCO methods typically require building one model for each routing problem, which significantly hinders their practical application for real-world industry problems with diverse attributes. In this work, we make the first attempt to tackle the crucial challenge of cross-problem generalization. In particular, we formulate VRPs as different combinations of a set of shared underlying attributes and solve them simultaneously via a single model through attribute composition. In this way, our proposed model can successfully solve VRPs with unseen attribute combinations in a zero-shot generalization manner. Extensive experiments are conducted on eleven VRP variants, benchmark datasets, and industry logistic scenarios. The results show that the unified model demonstrates superior performance in the eleven VRPs, reducing the average gap to around 5% from over 20% in the existing approach and achieving a significant performance boost on benchmark datasets as well as a real-world logistics application.
Identifying Factual Inconsistency in Summaries: Towards Effective Utilization of Large Language Model
Feb 20, 2024



Factual inconsistency poses a significant hurdle for the commercial deployment of abstractive summarizers. Under this Large Language Model (LLM) era, this work focuses around two important questions: what is the best way to leverage LLM for factual inconsistency detection, and how could we distill a smaller LLM with both high efficiency and efficacy? Three zero-shot paradigms are firstly proposed and evaluated across five diverse datasets: direct inference on the entire summary or each summary window; entity verification through question generation and answering. Experiments suggest that LLM itself is capable to resolve this task train-free under the proper paradigm design, surpassing strong trained baselines by 2.8% on average. To further promote practical utility, we then propose training strategies aimed at distilling smaller open-source LLM that learns to score the entire summary at once with high accuracy, which outperforms the zero-shot approaches by much larger LLM, serving as an effective and efficient ready-to-use scorer.
SportsMetrics: Blending Text and Numerical Data to Understand Information Fusion in LLMs
Feb 15, 2024Large language models hold significant potential for integrating various data types, such as text documents and database records, for advanced analytics. However, blending text and numerical data presents substantial challenges. LLMs need to process and cross-reference entities and numbers, handle data inconsistencies and redundancies, and develop planning capabilities such as building a working memory for managing complex data queries. In this paper, we introduce four novel tasks centered around sports data analytics to evaluate the numerical reasoning and information fusion capabilities of LLMs. These tasks involve providing LLMs with detailed, play-by-play sports game descriptions, then challenging them with adversarial scenarios such as new game rules, longer durations, scrambled narratives, and analyzing key statistics in game summaries. We conduct extensive experiments on NBA and NFL games to assess the performance of LLMs on these tasks. Our benchmark, SportsMetrics, introduces a new mechanism for assessing LLMs' numerical reasoning and fusion skills.
Factuality of Large Language Models in the Year 2024
Feb 09, 2024


Large language models (LLMs), especially when instruction-tuned for chat, have become part of our daily lives, freeing people from the process of searching, extracting, and integrating information from multiple sources by offering a straightforward answer to a variety of questions in a single place. Unfortunately, in many cases, LLM responses are factually incorrect, which limits their applicability in real-world scenarios. As a result, research on evaluating and improving the factuality of LLMs has attracted a lot of research attention recently. In this survey, we critically analyze existing work with the aim to identify the major challenges and their associated causes, pointing out to potential solutions for improving the factuality of LLMs, and analyzing the obstacles to automated factuality evaluation for open-ended text generation. We further offer an outlook on where future research should go.