 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinReporting: An Agentic Workflow for Localized Reporting of Cross-Jurisdiction Financial Disclosures
Apr 07, 2026Financial reporting systems increasingly use large language models (LLMs) to extract and summarize corporate disclosures. However, most assume a single-market setting and do not address structural differences across jurisdictions. Variations in accounting taxonomies, tagging infrastructures (e.g., XBRL vs. PDF), and aggregation conventions make cross-jurisdiction reporting a semantic alignment and verification challenge. We present FinReporting, an agentic workflow for localized cross-jurisdiction financial reporting. The system builds a unified canonical ontology over Income Statement, Balance Sheet, and Cash Flow, and decomposes reporting into auditable stages including filing acquisition, extraction, canonical mapping, and anomaly logging. Rather than using LLMs as free-form generators, FinReporting deploys them as constrained verifiers under explicit decision rules and evidence grounding. Evaluated on annual filings from the US, Japan, and China, the system improves consistency and reliability under heterogeneous reporting regimes. We release an interactive demo supporting cross-market inspection and structured export of localized financial statements. Our demo is available at https://huggingface.co/spaces/BoomQ/FinReporting-Demo . The video describing our system is available at https://www.youtube.com/watch?v=f65jdEL31Kk
The CLEF-2026 FinMMEval Lab: Multilingual and Multimodal Evaluation of Financial AI Systems
Feb 11, 2026We present the setup and the tasks of the FinMMEval Lab at CLEF 2026, which introduces the first multilingual and multimodal evaluation framework for financial Large Language Models (LLMs). While recent advances in financial natural language processing have enabled automated analysis of market reports, regulatory documents, and investor communications, existing benchmarks remain largely monolingual, text-only, and limited to narrow subtasks. FinMMEval 2026 addresses this gap by offering three interconnected tasks that span financial understanding, reasoning, and decision-making: Financial Exam Question Answering, Multilingual Financial Question Answering (PolyFiQA), and Financial Decision Making. Together, these tasks provide a comprehensive evaluation suite that measures models' ability to reason, generalize, and act across diverse languages and modalities. The lab aims to promote the development of robust, transparent, and globally inclusive financial AI systems, with datasets and evaluation resources publicly released to support reproducible research.
OpenFactCheck: A Unified Framework for Factuality Evaluation of LLMs
May 09, 2024



The increased use of large language models (LLMs) across a variety of real-world applications calls for mechanisms to verify the factual accuracy of their outputs. Difficulties lie in assessing the factuality of free-form responses in open domains. Also, different papers use disparate evaluation benchmarks and measurements, which renders them hard to compare and hampers future progress. To mitigate these issues, we propose OpenFactCheck, a unified factuality evaluation framework for LLMs. OpenFactCheck consists of three modules: (i) CUSTCHECKER allows users to easily customize an automatic fact-checker and verify the factual correctness of documents and claims, (ii) LLMEVAL, a unified evaluation framework assesses LLM's factuality ability from various perspectives fairly, and (iii) CHECKEREVAL is an extensible solution for gauging the reliability of automatic fact-checkers' verification results using human-annotated datasets. OpenFactCheck is publicly released at https://github.com/yuxiaw/OpenFactCheck.
Factuality of Large Language Models in the Year 2024
Feb 09, 2024


Large language models (LLMs), especially when instruction-tuned for chat, have become part of our daily lives, freeing people from the process of searching, extracting, and integrating information from multiple sources by offering a straightforward answer to a variety of questions in a single place. Unfortunately, in many cases, LLM responses are factually incorrect, which limits their applicability in real-world scenarios. As a result, research on evaluating and improving the factuality of LLMs has attracted a lot of research attention recently. In this survey, we critically analyze existing work with the aim to identify the major challenges and their associated causes, pointing out to potential solutions for improving the factuality of LLMs, and analyzing the obstacles to automated factuality evaluation for open-ended text generation. We further offer an outlook on where future research should go.
Leaf: Multiple-Choice Question Generation
Jan 22, 2022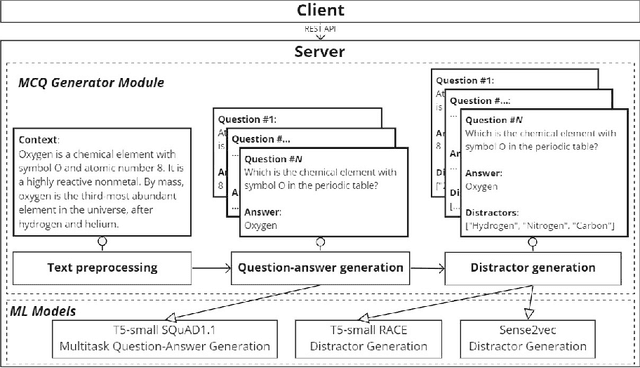
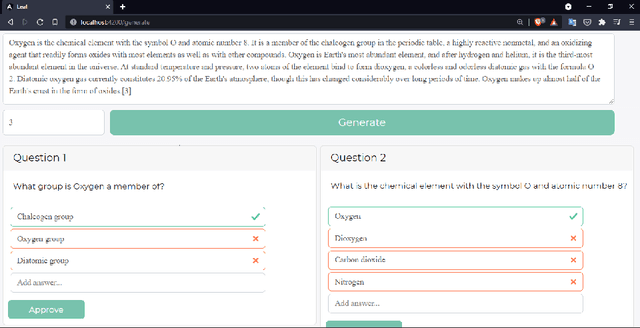
Testing with quiz questions has proven to be an effective way to assess and improve the educational process. However, manually creating quizzes is tedious and time-consuming. To address this challenge, we present Leaf, a system for generating multiple-choice questions from factual text. In addition to being very well suited for the classroom, Leaf could also be used in an industrial setting, e.g., to facilitate onboarding and knowledge sharing, or as a component of chatbots, question answering systems, or Massive Open Online Courses (MOOCs). The code and the demo are available on https://github.com/KristiyanVachev/Leaf-Question-Generation.
Feature-Rich Named Entity Recognition for Bulgarian Using Conditional Random Fields
Sep 26, 2021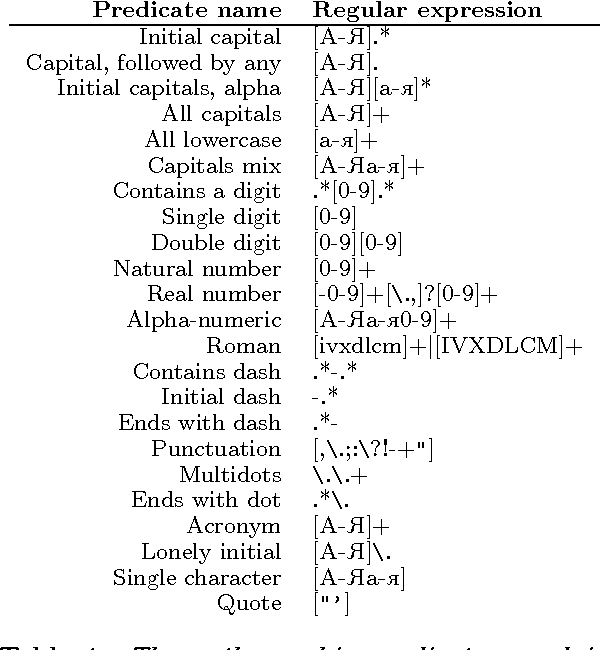

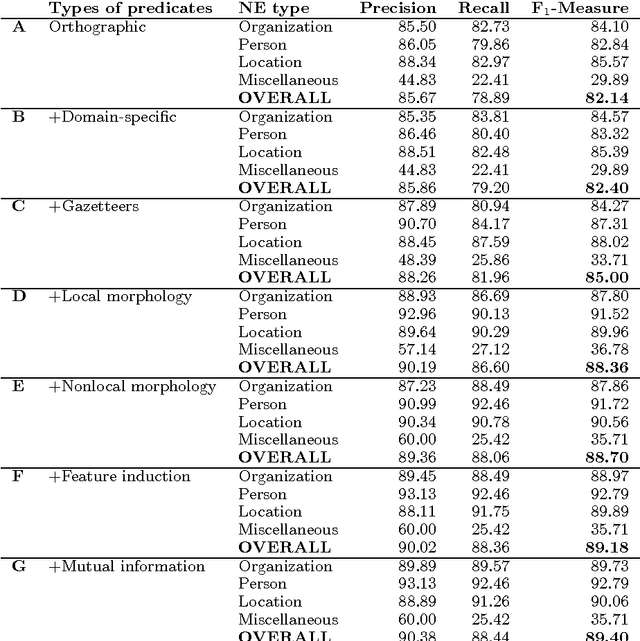
The paper presents a feature-rich approach to the automatic recognition and categorization of named entities (persons, organizations, locations, and miscellaneous) in news text for Bulgarian. We combine well-established features used for other languages with language-specific lexical, syntactic and morphological information. In particular, we make use of the rich tagset annotation of the BulTreeBank (680 morpho-syntactic tags), from which we derive suitable task-specific tagsets (local and nonlocal). We further add domain-specific gazetteers and additional unlabeled data, achieving F1=89.4%, which is comparable to the state-of-the-art results for English.
* named entity recognition, NER, conditional random fields, CRF, Bulgarian, BulTreeBank
Exposing Paid Opinion Manipulation Trolls
Sep 26, 2021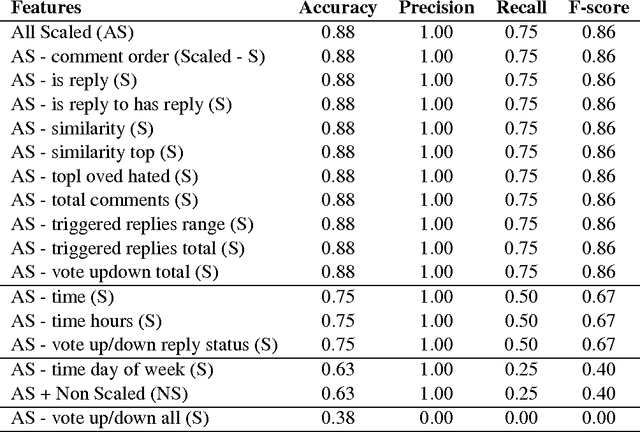
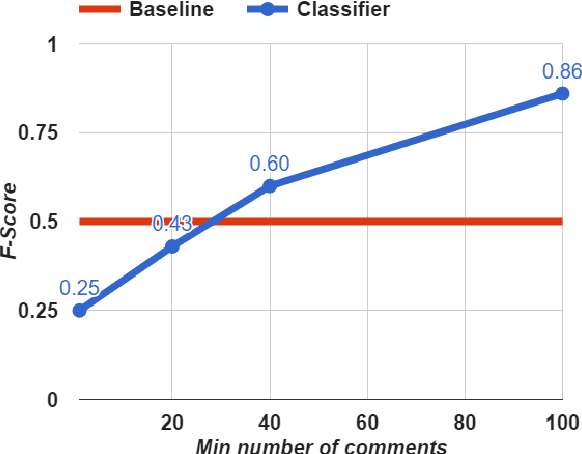
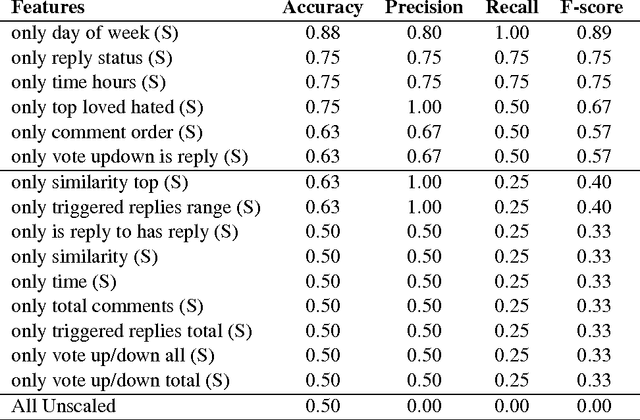
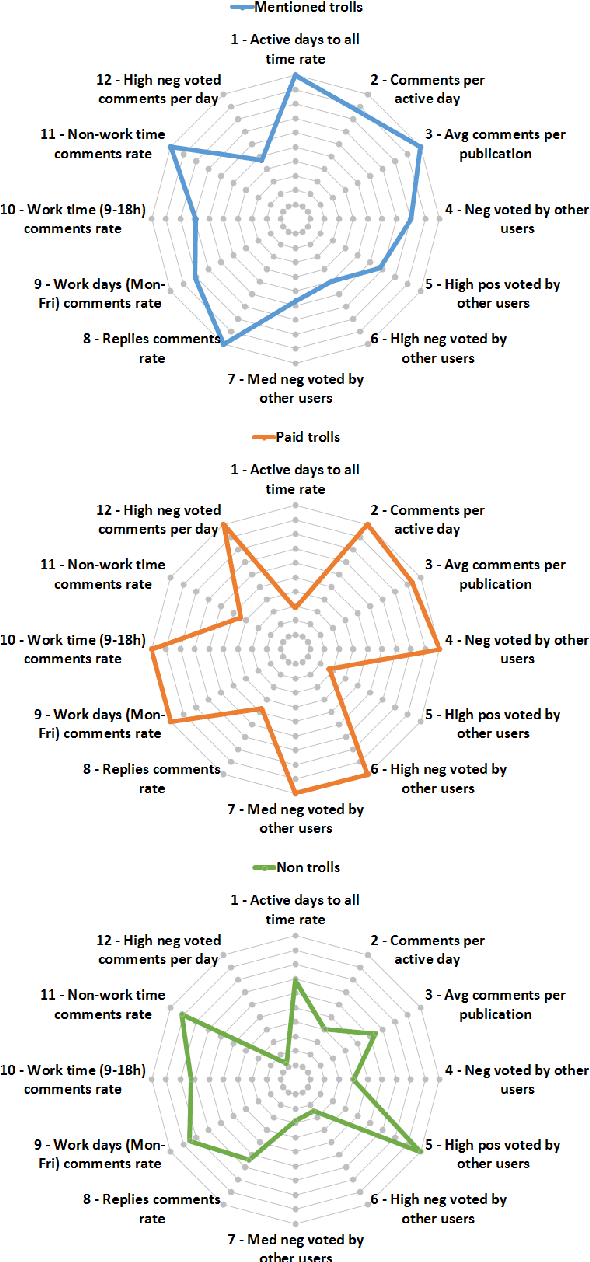
Recently, Web forums have been invaded by opinion manipulation trolls. Some trolls try to influence the other users driven by their own convictions, while in other cases they can be organized and paid, e.g., by a political party or a PR agency that gives them specific instructions what to write. Finding paid trolls automatically using machine learning is a hard task, as there is no enough training data to train a classifier; yet some test data is possible to obtain, as these trolls are sometimes caught and widely exposed. In this paper, we solve the training data problem by assuming that a user who is called a troll by several different people is likely to be such, and one who has never been called a troll is unlikely to be such. We compare the profiles of (i) paid trolls vs. (ii)"mentioned" trolls vs. (iii) non-trolls, and we further show that a classifier trained to distinguish (ii) from (iii) does quite well also at telling apart (i) from (iii).
* opinion manipulation trolls, trolls, opinion manipulation, community forums, news media
Generating Answer Candidates for Quizzes and Answer-Aware Question Generators
Aug 29, 2021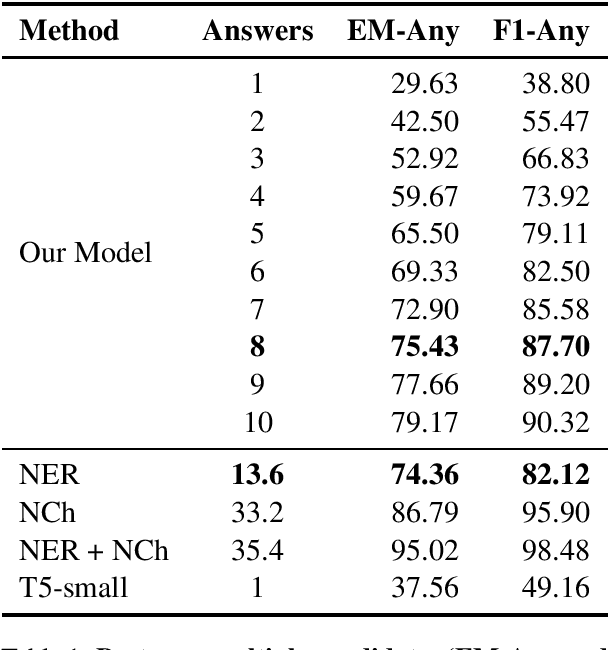
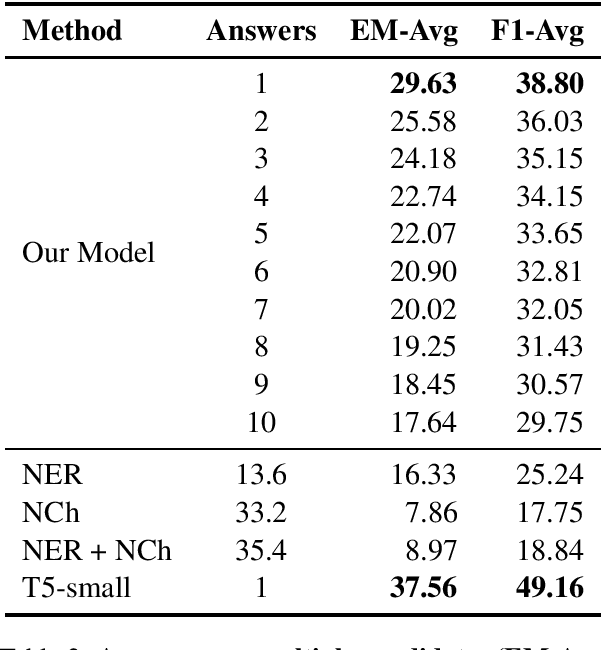

In education, open-ended quiz questions have become an important tool for assessing the knowledge of students. Yet, manually preparing such questions is a tedious task, and thus automatic question generation has been proposed as a possible alternative. So far, the vast majority of research has focused on generating the question text, relying on question answering datasets with readily picked answers, and the problem of how to come up with answer candidates in the first place has been largely ignored. Here, we aim to bridge this gap. In particular, we propose a model that can generate a specified number of answer candidates for a given passage of text, which can then be used by instructors to write questions manually or can be passed as an input to automatic answer-aware question generators. Our experiments show that our proposed answer candidate generation model outperforms several baselines.
* answer generation, question generation, answer-aware question generation, quiz questions, question answering
Feature-Rich Part-of-speech Tagging for Morphologically Complex Languages: Application to Bulgarian
Nov 26, 2019
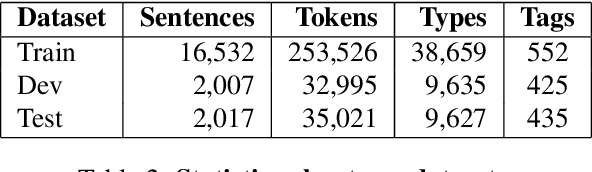

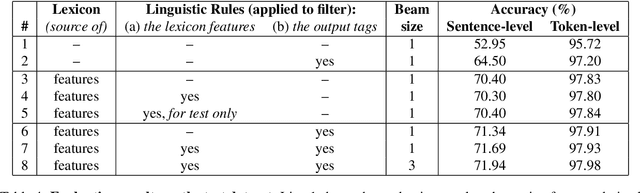
We present experiments with part-of-speech tagging for Bulgarian, a Slavic language with rich inflectional and derivational morphology. Unlike most previous work, which has used a small number of grammatical categories, we work with 680 morpho-syntactic tags. We combine a large morphological lexicon with prior linguistic knowledge and guided learning from a POS-annotated corpus, achieving accuracy of 97.98%, which is a significant improvement over the state-of-the-art for Bulgarian.
* part-of-speech tagging, POS tagging, morpho-syntactic tags, guided learning, Bulgarian, Slavic
Where Classification Fails, Interpretation Rises
Dec 02, 2017
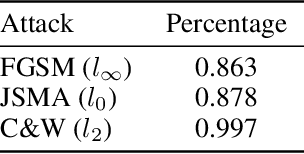
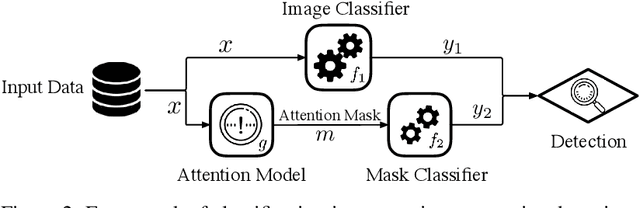

An intriguing property of deep neural networks is their inherent vulnerability to adversarial inputs, which significantly hinders their application in security-critical domains. Most existing detection methods attempt to use carefully engineered patterns to distinguish adversarial inputs from their genuine counterparts, which however can often be circumvented by adaptive adversaries. In this work, we take a completely different route by leveraging the definition of adversarial inputs: while deceiving for deep neural networks, they are barely discernible for human visions. Building upon recent advances in interpretable models, we construct a new detection framework that contrasts an input's interpretation against its classification. We validate the efficacy of this framework through extensive experiments using benchmark datasets and attacks. We believe that this work opens a new direction for designing adversarial input detection methods.