 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting the Cross-Architecture Generalization of Dataset Distillation through an Empirical Study
Dec 09, 2023



The poor cross-architecture generalization of dataset distillation greatly weakens its practical significance. This paper attempts to mitigate this issue through an empirical study, which suggests that the synthetic datasets undergo an inductive bias towards the distillation model. Therefore, the evaluation model is strictly confined to having similar architectures of the distillation model. We propose a novel method of EvaLuation with distillation Feature (ELF), which utilizes features from intermediate layers of the distillation model for the cross-architecture evaluation. In this manner, the evaluation model learns from bias-free knowledge therefore its architecture becomes unfettered while retaining performance. By performing extensive experiments, we successfully prove that ELF can well enhance the cross-architecture generalization of current DD methods. Code of this project is at \url{https://github.com/Lirui-Zhao/ELF}.
AutoDiffusion: Training-Free Optimization of Time Steps and Architectures for Automated Diffusion Model Acceleration
Sep 23, 2023



Diffusion models are emerging expressive generative models, in which a large number of time steps (inference steps) are required for a single image generation. To accelerate such tedious process, reducing steps uniformly is considered as an undisputed principle of diffusion models. We consider that such a uniform assumption is not the optimal solution in practice; i.e., we can find different optimal time steps for different models. Therefore, we propose to search the optimal time steps sequence and compressed model architecture in a unified framework to achieve effective image generation for diffusion models without any further training. Specifically, we first design a unified search space that consists of all possible time steps and various architectures. Then, a two stage evolutionary algorithm is introduced to find the optimal solution in the designed search space. To further accelerate the search process, we employ FID score between generated and real samples to estimate the performance of the sampled examples. As a result, the proposed method is (i).training-free, obtaining the optimal time steps and model architecture without any training process; (ii). orthogonal to most advanced diffusion samplers and can be integrated to gain better sample quality. (iii). generalized, where the searched time steps and architectures can be directly applied on different diffusion models with the same guidance scale. Experimental results show that our method achieves excellent performance by using only a few time steps, e.g. 17.86 FID score on ImageNet 64 $\times$ 64 with only four steps, compared to 138.66 with DDIM. The code is available at https://github.com/lilijiangg/AutoDiffusion.
A Unified Framework for 3D Point Cloud Visual Grounding
Aug 23, 2023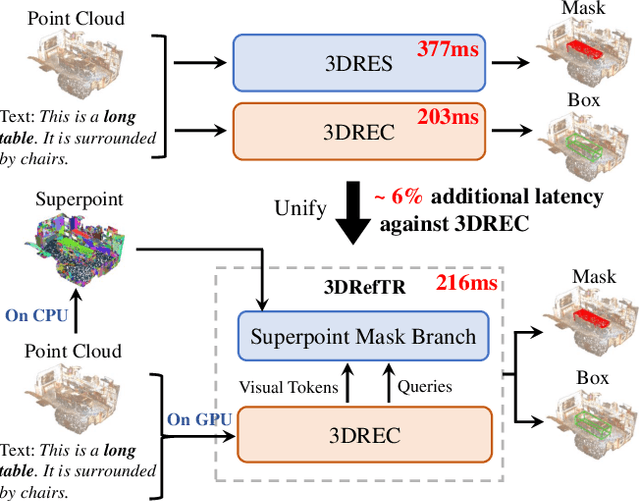
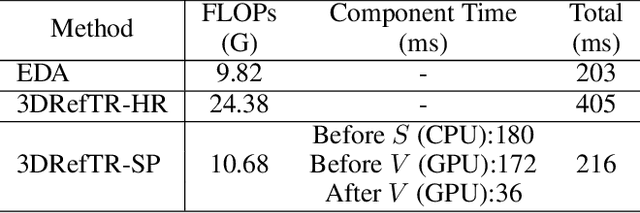
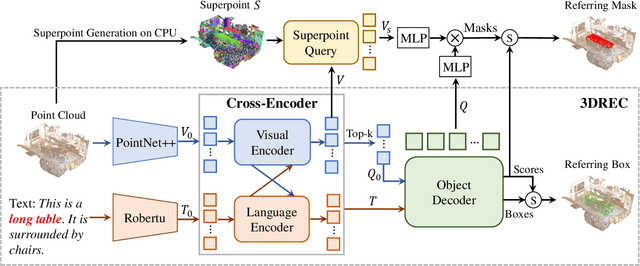

3D point cloud visual grounding plays a critical role in 3D scene comprehension, encompassing 3D referring expression comprehension (3DREC) and segmentation (3DRES). We argue that 3DREC and 3DRES should be unified in one framework, which is also a natural progression in the community. To explain, 3DREC can help 3DRES locate the referent, while 3DRES can also facilitate 3DREC via more finegrained language-visual alignment. To achieve this, this paper takes the initiative step to integrate 3DREC and 3DRES into a unified framework, termed 3D Referring Transformer (3DRefTR). Its key idea is to build upon a mature 3DREC model and leverage ready query embeddings and visual tokens from the 3DREC model to construct a dedicated mask branch. Specially, we propose Superpoint Mask Branch, which serves a dual purpose: i) By leveraging the heterogeneous CPU-GPU parallelism, while the GPU is occupied generating visual tokens, the CPU concurrently produces superpoints, equivalently accomplishing the upsampling computation; ii) By harnessing on the inherent association between the superpoints and point cloud, it eliminates the heavy computational overhead on the high-resolution visual features for upsampling. This elegant design enables 3DRefTR to achieve both well-performing 3DRES and 3DREC capacities with only a 6% additional latency compared to the original 3DREC model. Empirical evaluations affirm the superiority of 3DRefTR. Specifically, on the ScanRefer dataset, 3DRefTR surpasses the state-of-the-art 3DRES method by 12.43% in mIoU and improves upon the SOTA 3DREC method by 0.6% Acc@0.25IoU.
Spatial Re-parameterization for N:M Sparsity
Jun 09, 2023This paper presents a Spatial Re-parameterization (SpRe) method for the N:M sparsity in CNNs. SpRe is stemmed from an observation regarding the restricted variety in spatial sparsity present in N:M sparsity compared with unstructured sparsity. Particularly, N:M sparsity exhibits a fixed sparsity rate within the spatial domains due to its distinctive pattern that mandates N non-zero components among M successive weights in the input channel dimension of convolution filters. On the contrary, we observe that unstructured sparsity displays a substantial divergence in sparsity across the spatial domains, which we experimentally verified to be very crucial for its robust performance retention compared with N:M sparsity. Therefore, SpRe employs the spatial-sparsity distribution of unstructured sparsity to assign an extra branch in conjunction with the original N:M branch at training time, which allows the N:M sparse network to sustain a similar distribution of spatial sparsity with unstructured sparsity. During inference, the extra branch can be further re-parameterized into the main N:M branch, without exerting any distortion on the sparse pattern or additional computation costs. SpRe has achieved a commendable feat by matching the performance of N:M sparsity methods with state-of-the-art unstructured sparsity methods across various benchmarks. Code and models are anonymously available at \url{https://github.com/zyxxmu/SpRe}.
DiffRate : Differentiable Compression Rate for Efficient Vision Transformers
May 29, 2023



Token compression aims to speed up large-scale vision transformers (e.g. ViTs) by pruning (dropping) or merging tokens. It is an important but challenging task. Although recent advanced approaches achieved great success, they need to carefully handcraft a compression rate (i.e. number of tokens to remove), which is tedious and leads to sub-optimal performance. To tackle this problem, we propose Differentiable Compression Rate (DiffRate), a novel token compression method that has several appealing properties prior arts do not have. First, DiffRate enables propagating the loss function's gradient onto the compression ratio, which is considered as a non-differentiable hyperparameter in previous work. In this case, different layers can automatically learn different compression rates layer-wisely without extra overhead. Second, token pruning and merging can be naturally performed simultaneously in DiffRate, while they were isolated in previous works. Third, extensive experiments demonstrate that DiffRate achieves state-of-the-art performance. For example, by applying the learned layer-wise compression rates to an off-the-shelf ViT-H (MAE) model, we achieve a 40% FLOPs reduction and a 1.5x throughput improvement, with a minor accuracy drop of 0.16% on ImageNet without fine-tuning, even outperforming previous methods with fine-tuning. Codes and models are available at https://github.com/OpenGVLab/DiffRate.
MultiQuant: A Novel Multi-Branch Topology Method for Arbitrary Bit-width Network Quantization
May 14, 2023Arbitrary bit-width network quantization has received significant attention due to its high adaptability to various bit-width requirements during runtime. However, in this paper, we investigate existing methods and observe a significant accumulation of quantization errors caused by frequent bit-width switching of weights and activations, leading to limited performance. To address this issue, we propose MultiQuant, a novel method that utilizes a multi-branch topology for arbitrary bit-width quantization. MultiQuant duplicates the network body into multiple independent branches and quantizes the weights of each branch to a fixed 2-bit while retaining the input activations in the expected bit-width. This approach maintains the computational cost as the same while avoiding the switching of weight bit-widths, thereby substantially reducing errors in weight quantization. Additionally, we introduce an amortization branch selection strategy to distribute quantization errors caused by activation bit-width switching among branches to enhance performance. Finally, we design an in-place distillation strategy that facilitates guidance between branches to further enhance MultiQuant's performance. Extensive experiments demonstrate that MultiQuant achieves significant performance gains compared to existing arbitrary bit-width quantization methods. Code is at \url{https://github.com/zysxmu/MultiQuant}.
Distribution-Flexible Subset Quantization for Post-Quantizing Super-Resolution Networks
May 12, 2023



This paper introduces Distribution-Flexible Subset Quantization (DFSQ), a post-training quantization method for super-resolution networks. Our motivation for developing DFSQ is based on the distinctive activation distributions of current super-resolution models, which exhibit significant variance across samples and channels. To address this issue, DFSQ conducts channel-wise normalization of the activations and applies distribution-flexible subset quantization (SQ), wherein the quantization points are selected from a universal set consisting of multi-word additive log-scale values. To expedite the selection of quantization points in SQ, we propose a fast quantization points selection strategy that uses K-means clustering to select the quantization points closest to the centroids. Compared to the common iterative exhaustive search algorithm, our strategy avoids the enumeration of all possible combinations in the universal set, reducing the time complexity from exponential to linear. Consequently, the constraint of time costs on the size of the universal set is greatly relaxed. Extensive evaluations of various super-resolution models show that DFSQ effectively retains performance even without fine-tuning. For example, when quantizing EDSRx2 on the Urban benchmark, DFSQ achieves comparable performance to full-precision counterparts on 6- and 8-bit quantization, and incurs only a 0.1 dB PSNR drop on 4-bit quantization. Code is at \url{https://github.com/zysxmu/DFSQ}
Solving Oscillation Problem in Post-Training Quantization Through a Theoretical Perspective
Apr 04, 2023



Post-training quantization (PTQ) is widely regarded as one of the most efficient compression methods practically, benefitting from its data privacy and low computation costs. We argue that an overlooked problem of oscillation is in the PTQ methods. In this paper, we take the initiative to explore and present a theoretical proof to explain why such a problem is essential in PTQ. And then, we try to solve this problem by introducing a principled and generalized framework theoretically. In particular, we first formulate the oscillation in PTQ and prove the problem is caused by the difference in module capacity. To this end, we define the module capacity (ModCap) under data-dependent and data-free scenarios, where the differentials between adjacent modules are used to measure the degree of oscillation. The problem is then solved by selecting top-k differentials, in which the corresponding modules are jointly optimized and quantized. Extensive experiments demonstrate that our method successfully reduces the performance drop and is generalized to different neural networks and PTQ methods. For example, with 2/4 bit ResNet-50 quantization, our method surpasses the previous state-of-the-art method by 1.9%. It becomes more significant on small model quantization, e.g. surpasses BRECQ method by 6.61% on MobileNetV2*0.5.
Bi-directional Masks for Efficient N:M Sparse Training
Feb 13, 2023We focus on addressing the dense backward propagation issue for training efficiency of N:M fine-grained sparsity that preserves at most N out of M consecutive weights and achieves practical speedups supported by the N:M sparse tensor core. Therefore, we present a novel method of Bi-directional Masks (Bi-Mask) with its two central innovations in: 1) Separate sparse masks in the two directions of forward and backward propagation to obtain training acceleration. It disentangles the forward and backward weight sparsity and overcomes the very dense gradient computation. 2) An efficient weight row permutation method to maintain performance. It picks up the permutation candidate with the most eligible N:M weight blocks in the backward to minimize the gradient gap between traditional uni-directional masks and our bi-directional masks. Compared with existing uni-directional scenario that applies a transposable mask and enables backward acceleration, our Bi-Mask is experimentally demonstrated to be more superior in performance. Also, our Bi-Mask performs on par with or even better than methods that fail to achieve backward acceleration. Project of this paper is available at \url{https://github.com/zyxxmu/Bi-Mask}.
Real-Time Image Demoireing on Mobile Devices
Feb 04, 2023



Moire patterns appear frequently when taking photos of digital screens, drastically degrading the image quality. Despite the advance of CNNs in image demoireing, existing networks are with heavy design, causing redundant computation burden for mobile devices. In this paper, we launch the first study on accelerating demoireing networks and propose a dynamic demoireing acceleration method (DDA) towards a real-time deployment on mobile devices. Our stimulus stems from a simple-yet-universal fact that moire patterns often unbalancedly distribute across an image. Consequently, excessive computation is wasted upon non-moire areas. Therefore, we reallocate computation costs in proportion to the complexity of image patches. In order to achieve this aim, we measure the complexity of an image patch by designing a novel moire prior that considers both colorfulness and frequency information of moire patterns. Then, we restore image patches with higher-complexity using larger networks and the ones with lower-complexity are assigned with smaller networks to relieve the computation burden. At last, we train all networks in a parameter-shared supernet paradigm to avoid additional parameter burden. Extensive experiments on several benchmarks demonstrate the efficacy of our proposed DDA. In addition, the acceleration evaluated on the VIVO X80 Pro smartphone equipped with a chip of Snapdragon 8 Gen 1 shows that our method can drastically reduce the inference time, leading to a real-time image demoireing on mobile devices. Source codes and models are released at https://github.com/zyxxmu/DDA