 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeFi: Cross-Modal Knowledge Transfer for Wireless Skeleton-Based Action Recognition
Jan 18, 2026Skeleton-based action recognition leverages human pose keypoints to categorize human actions, which shows superior generalization and interoperability compared to regular end-to-end action recognition. Existing solutions use RGB cameras to annotate skeletal keypoints, but their performance declines in dark environments and raises privacy concerns, limiting their use in smart homes and hospitals. This paper explores non-invasive wireless sensors, i.e., LiDAR and mmWave, to mitigate these challenges as a feasible alternative. Two problems are addressed: (1) insufficient data on wireless sensor modality to train an accurate skeleton estimation model, and (2) skeletal keypoints derived from wireless sensors are noisier than RGB, causing great difficulties for subsequent action recognition models. Our work, SkeFi, overcomes these gaps through a novel cross-modal knowledge transfer method acquired from the data-rich RGB modality. We propose the enhanced Temporal Correlation Adaptive Graph Convolution (TC-AGC) with frame interactive enhancement to overcome the noise from missing or inconsecutive frames. Additionally, our research underscores the effectiveness of enhancing multiscale temporal modeling through dual temporal convolution. By integrating TC-AGC with temporal modeling for cross-modal transfer, our framework can extract accurate poses and actions from noisy wireless sensors. Experiments demonstrate that SkeFi realizes state-of-the-art performances on mmWave and LiDAR. The code is available at https://github.com/Huang0035/Skefi.
M4Human: A Large-Scale Multimodal mmWave Radar Benchmark for Human Mesh Reconstruction
Dec 17, 2025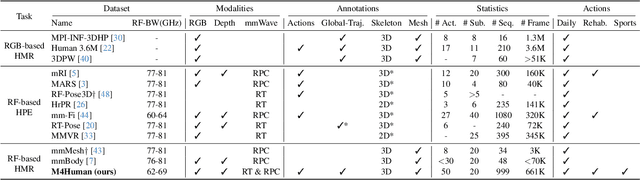
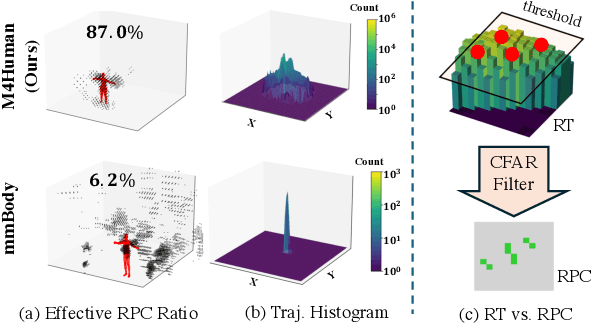

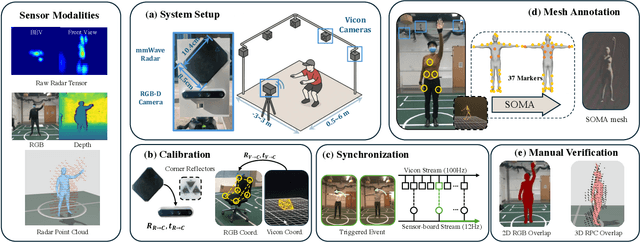
Human mesh reconstruction (HMR) provides direct insights into body-environment interaction, which enables various immersive applications. While existing large-scale HMR datasets rely heavily on line-of-sight RGB input, vision-based sensing is limited by occlusion, lighting variation, and privacy concerns. To overcome these limitations, recent efforts have explored radio-frequency (RF) mmWave radar for privacy-preserving indoor human sensing. However, current radar datasets are constrained by sparse skeleton labels, limited scale, and simple in-place actions. To advance the HMR research community, we introduce M4Human, the current largest-scale (661K-frame) ($9\times$ prior largest) multimodal benchmark, featuring high-resolution mmWave radar, RGB, and depth data. M4Human provides both raw radar tensors (RT) and processed radar point clouds (RPC) to enable research across different levels of RF signal granularity. M4Human includes high-quality motion capture (MoCap) annotations with 3D meshes and global trajectories, and spans 20 subjects and 50 diverse actions, including in-place, sit-in-place, and free-space sports or rehabilitation movements. We establish benchmarks on both RT and RPC modalities, as well as multimodal fusion with RGB-D modalities. Extensive results highlight the significance of M4Human for radar-based human modeling while revealing persistent challenges under fast, unconstrained motion. The dataset and code will be released after the paper publication.
Zero-Shot Open-Vocabulary Human Motion Grounding with Test-Time Training
Nov 19, 2025Understanding complex human activities demands the ability to decompose motion into fine-grained, semantic-aligned sub-actions. This motion grounding process is crucial for behavior analysis, embodied AI and virtual reality. Yet, most existing methods rely on dense supervision with predefined action classes, which are infeasible in open-vocabulary, real-world settings. In this paper, we propose ZOMG, a zero-shot, open-vocabulary framework that segments motion sequences into semantically meaningful sub-actions without requiring any annotations or fine-tuning. Technically, ZOMG integrates (1) language semantic partition, which leverages large language models to decompose instructions into ordered sub-action units, and (2) soft masking optimization, which learns instance-specific temporal masks to focus on frames critical to sub-actions, while maintaining intra-segment continuity and enforcing inter-segment separation, all without altering the pretrained encoder. Experiments on three motion-language datasets demonstrate state-of-the-art effectiveness and efficiency of motion grounding performance, outperforming prior methods by +8.7\% mAP on HumanML3D benchmark. Meanwhile, significant improvements also exist in downstream retrieval, establishing a new paradigm for annotation-free motion understanding.
Generative Dataset Distillation using Min-Max Diffusion Model
Mar 24, 2025In this paper, we address the problem of generative dataset distillation that utilizes generative models to synthesize images. The generator may produce any number of images under a preserved evaluation time. In this work, we leverage the popular diffusion model as the generator to compute a surrogate dataset, boosted by a min-max loss to control the dataset's diversity and representativeness during training. However, the diffusion model is time-consuming when generating images, as it requires an iterative generation process. We observe a critical trade-off between the number of image samples and the image quality controlled by the diffusion steps and propose Diffusion Step Reduction to achieve optimal performance. This paper details our comprehensive method and its performance. Our model achieved $2^{nd}$ place in the generative track of \href{https://www.dd-challenge.com/#/}{The First Dataset Distillation Challenge of ECCV2024}, demonstrating its superior performance.
IoT-LLM: Enhancing Real-World IoT Task Reasoning with Large Language Models
Oct 03, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities across textual and visual domains but often generate outputs that violate physical laws, revealing a gap in their understanding of the physical world. Inspired by human cognition, where perception is fundamental to reasoning, we explore augmenting LLMs with enhanced perception abilities using Internet of Things (IoT) sensor data and pertinent knowledge for IoT task reasoning in the physical world. In this work, we systematically study LLMs capability to address real-world IoT tasks by augmenting their perception and knowledge base, and then propose a unified framework, IoT-LLM, to enhance such capability. In IoT-LLM, we customize three steps for LLMs: preprocessing IoT data into formats amenable to LLMs, activating their commonsense knowledge through chain-of-thought prompting and specialized role definitions, and expanding their understanding via IoT-oriented retrieval-augmented generation based on in-context learning. To evaluate the performance, We design a new benchmark with five real-world IoT tasks with different data types and reasoning difficulties and provide the benchmarking results on six open-source and close-source LLMs. Experimental results demonstrate the limitations of existing LLMs with naive textual inputs that cannot perform these tasks effectively. We show that IoT-LLM significantly enhances the performance of IoT tasks reasoning of LLM, such as GPT-4, achieving an average improvement of 65% across various tasks against previous methods. The results also showcase LLMs ability to comprehend IoT data and the physical law behind data by providing a reasoning process. Limitations of our work are claimed to inspire future research in this new era.
PowerSkel: A Device-Free Framework Using CSI Signal for Human Skeleton Estimation in Power Station
Mar 04, 2024



Safety monitoring of power operations in power stations is crucial for preventing accidents and ensuring stable power supply. However, conventional methods such as wearable devices and video surveillance have limitations such as high cost, dependence on light, and visual blind spots. WiFi-based human pose estimation is a suitable method for monitoring power operations due to its low cost, device-free, and robustness to various illumination conditions.In this paper, a novel Channel State Information (CSI)-based pose estimation framework, namely PowerSkel, is developed to address these challenges. PowerSkel utilizes self-developed CSI sensors to form a mutual sensing network and constructs a CSI acquisition scheme specialized for power scenarios. It significantly reduces the deployment cost and complexity compared to the existing solutions. To reduce interference with CSI in the electricity scenario, a sparse adaptive filtering algorithm is designed to preprocess the CSI. CKDformer, a knowledge distillation network based on collaborative learning and self-attention, is proposed to extract the features from CSI and establish the mapping relationship between CSI and keypoints. The experiments are conducted in a real-world power station, and the results show that the PowerSkel achieves high performance with a PCK@50 of 96.27%, and realizes a significant visualization on pose estimation, even in dark environments. Our work provides a novel low-cost and high-precision pose estimation solution for power operation.
MaskFi: Unsupervised Learning of WiFi and Vision Representations for Multimodal Human Activity Recognition
Feb 29, 2024



Human activity recognition (HAR) has been playing an increasingly important role in various domains such as healthcare, security monitoring, and metaverse gaming. Though numerous HAR methods based on computer vision have been developed to show prominent performance, they still suffer from poor robustness in adverse visual conditions in particular low illumination, which motivates WiFi-based HAR to serve as a good complementary modality. Existing solutions using WiFi and vision modalities rely on massive labeled data that are very cumbersome to collect. In this paper, we propose a novel unsupervised multimodal HAR solution, MaskFi, that leverages only unlabeled video and WiFi activity data for model training. We propose a new algorithm, masked WiFi-vision modeling (MI2M), that enables the model to learn cross-modal and single-modal features by predicting the masked sections in representation learning. Benefiting from our unsupervised learning procedure, the network requires only a small amount of annotated data for finetuning and can adapt to the new environment with better performance. We conduct extensive experiments on two WiFi-vision datasets collected in-house, and our method achieves human activity recognition and human identification in terms of both robustness and accuracy.
T3DNet: Compressing Point Cloud Models for Lightweight 3D Recognition
Feb 29, 20243D point cloud has been widely used in many mobile application scenarios, including autonomous driving and 3D sensing on mobile devices. However, existing 3D point cloud models tend to be large and cumbersome, making them hard to deploy on edged devices due to their high memory requirements and non-real-time latency. There has been a lack of research on how to compress 3D point cloud models into lightweight models. In this paper, we propose a method called T3DNet (Tiny 3D Network with augmEntation and disTillation) to address this issue. We find that the tiny model after network augmentation is much easier for a teacher to distill. Instead of gradually reducing the parameters through techniques such as pruning or quantization, we pre-define a tiny model and improve its performance through auxiliary supervision from augmented networks and the original model. We evaluate our method on several public datasets, including ModelNet40, ShapeNet, and ScanObjectNN. Our method can achieve high compression rates without significant accuracy sacrifice, achieving state-of-the-art performances on three datasets against existing methods. Amazingly, our T3DNet is 58 times smaller and 54 times faster than the original model yet with only 1.4% accuracy descent on the ModelNet40 dataset.
TENT: Connect Language Models with IoT Sensors for Zero-Shot Activity Recognition
Nov 14, 2023Recent achievements in language models have showcased their extraordinary capabilities in bridging visual information with semantic language understanding. This leads us to a novel question: can language models connect textual semantics with IoT sensory signals to perform recognition tasks, e.g., Human Activity Recognition (HAR)? If so, an intelligent HAR system with human-like cognition can be built, capable of adapting to new environments and unseen categories. This paper explores its feasibility with an innovative approach, IoT-sEnsors-language alignmEnt pre-Training (TENT), which jointly aligns textual embeddings with IoT sensor signals, including camera video, LiDAR, and mmWave. Through the IoT-language contrastive learning, we derive a unified semantic feature space that aligns multi-modal features with language embeddings, so that the IoT data corresponds to specific words that describe the IoT data. To enhance the connection between textual categories and their IoT data, we propose supplementary descriptions and learnable prompts that bring more semantic information into the joint feature space. TENT can not only recognize actions that have been seen but also ``guess'' the unseen action by the closest textual words from the feature space. We demonstrate TENT achieves state-of-the-art performance on zero-shot HAR tasks using different modalities, improving the best vision-language models by over 12%.
AdaPose: Towards Cross-Site Device-Free Human Pose Estimation with Commodity WiFi
Sep 29, 2023WiFi-based pose estimation is a technology with great potential for the development of smart homes and metaverse avatar generation. However, current WiFi-based pose estimation methods are predominantly evaluated under controlled laboratory conditions with sophisticated vision models to acquire accurately labeled data. Furthermore, WiFi CSI is highly sensitive to environmental variables, and direct application of a pre-trained model to a new environment may yield suboptimal results due to domain shift. In this paper, we proposes a domain adaptation algorithm, AdaPose, designed specifically for weakly-supervised WiFi-based pose estimation. The proposed method aims to identify consistent human poses that are highly resistant to environmental dynamics. To achieve this goal, we introduce a Mapping Consistency Loss that aligns the domain discrepancy of source and target domains based on inner consistency between input and output at the mapping level. We conduct extensive experiments on domain adaptation in two different scenes using our self-collected pose estimation dataset containing WiFi CSI frames. The results demonstrate the effectiveness and robustness of AdaPose in eliminating domain shift, thereby facilitating the widespread application of WiFi-based pose estimation in smart cities.