 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Constraint by Only Support Constraint for Offline Reinforcement Learning
Mar 07, 2025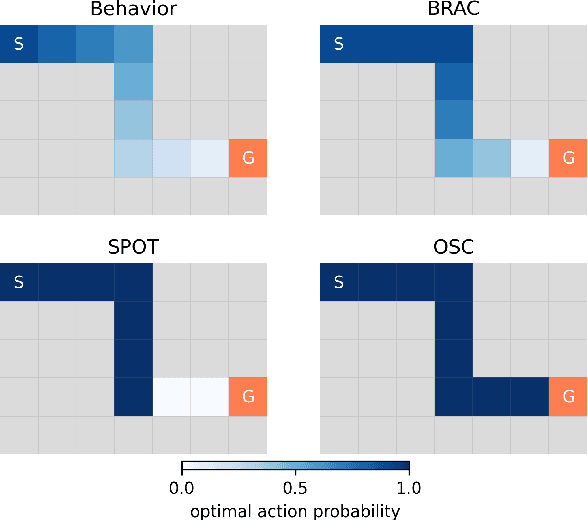
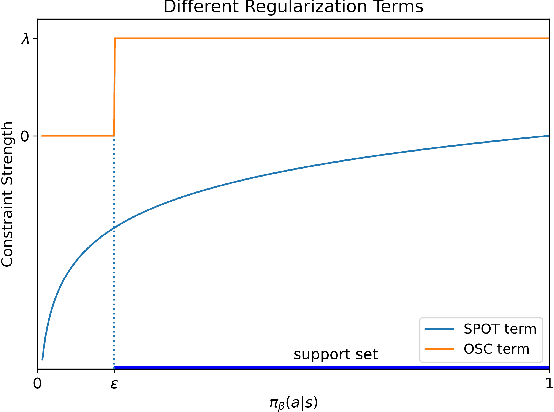

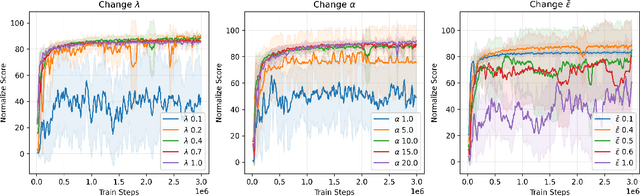
Offline reinforcement learning (RL) aims to optimize a policy by using pre-collected datasets, to maximize cumulative rewards. However, offline reinforcement learning suffers challenges due to the distributional shift between the learned and behavior policies, leading to errors when computing Q-values for out-of-distribution (OOD) actions. To mitigate this issue, policy constraint methods aim to constrain the learned policy's distribution with the distribution of the behavior policy or confine action selection within the support of the behavior policy. However, current policy constraint methods tend to exhibit excessive conservatism, hindering the policy from further surpassing the behavior policy's performance. In this work, we present Only Support Constraint (OSC) which is derived from maximizing the total probability of learned policy in the support of behavior policy, to address the conservatism of policy constraint. OSC presents a regularization term that only restricts policies to the support without imposing extra constraints on actions within the support. Additionally, to fully harness the performance of the new policy constraints, OSC utilizes a diffusion model to effectively characterize the support of behavior policies. Experimental evaluations across a variety of offline RL benchmarks demonstrate that OSC significantly enhances performance, alleviating the challenges associated with distributional shifts and mitigating conservatism of policy constraints. Code is available at https://github.com/MoreanP/OSC.
It's My Data Too: Private ML for Datasets with Multi-User Training Examples
Mar 05, 2025



We initiate a study of algorithms for model training with user-level differential privacy (DP), where each example may be attributed to multiple users, which we call the multi-attribution model. We first provide a carefully chosen definition of user-level DP under the multi-attribution model. Training in the multi-attribution model is facilitated by solving the contribution bounding problem, i.e. the problem of selecting a subset of the dataset for which each user is associated with a limited number of examples. We propose a greedy baseline algorithm for the contribution bounding problem. We then empirically study this algorithm for a synthetic logistic regression task and a transformer training task, including studying variants of this baseline algorithm that optimize the subset chosen using different techniques and criteria. We find that the baseline algorithm remains competitive with its variants in most settings, and build a better understanding of the practical importance of a bias-variance tradeoff inherent in solutions to the contribution bounding problem.
Learning Temporal 3D Semantic Scene Completion via Optical Flow Guidance
Feb 20, 2025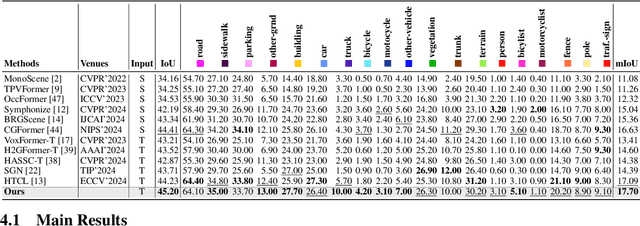
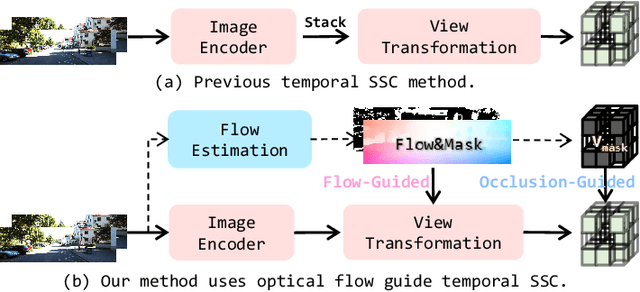

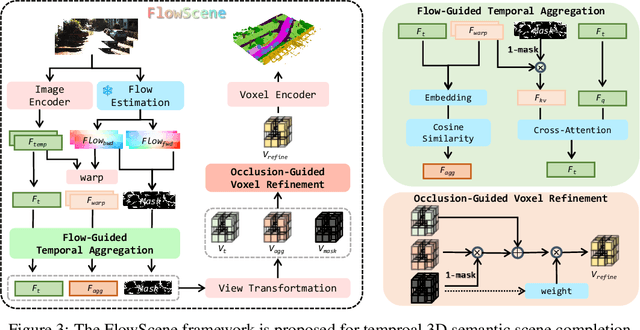
3D Semantic Scene Completion (SSC) provides comprehensive scene geometry and semantics for autonomous driving perception, which is crucial for enabling accurate and reliable decision-making. However, existing SSC methods are limited to capturing sparse information from the current frame or naively stacking multi-frame temporal features, thereby failing to acquire effective scene context. These approaches ignore critical motion dynamics and struggle to achieve temporal consistency. To address the above challenges, we propose a novel temporal SSC method FlowScene: Learning Temporal 3D Semantic Scene Completion via Optical Flow Guidance. By leveraging optical flow, FlowScene can integrate motion, different viewpoints, occlusions, and other contextual cues, thereby significantly improving the accuracy of 3D scene completion. Specifically, our framework introduces two key components: (1) a Flow-Guided Temporal Aggregation module that aligns and aggregates temporal features using optical flow, capturing motion-aware context and deformable structures; and (2) an Occlusion-Guided Voxel Refinement module that injects occlusion masks and temporally aggregated features into 3D voxel space, adaptively refining voxel representations for explicit geometric modeling. Experimental results demonstrate that FlowScene achieves state-of-the-art performance on the SemanticKITTI and SSCBench-KITTI-360 benchmarks.
OpenMLDB: A Real-Time Relational Data Feature Computation System for Online ML
Jan 15, 2025



Efficient and consistent feature computation is crucial for a wide range of online ML applications. Typically, feature computation is divided into two distinct phases, i.e., offline stage for model training and online stage for model serving. These phases often rely on execution engines with different interface languages and function implementations, causing significant inconsistencies. Moreover, many online ML features involve complex time-series computations (e.g., functions over varied-length table windows) that differ from standard streaming and analytical queries. Existing data processing systems (e.g., Spark, Flink, DuckDB) often incur multi-second latencies for these computations, making them unsuitable for real-time online ML applications that demand timely feature updates. This paper presents OpenMLDB, a feature computation system deployed in 4Paradigm's SageOne platform and over 100 real scenarios. Technically, OpenMLDB first employs a unified query plan generator for consistent computation results across the offline and online stages, significantly reducing feature deployment overhead. Second, OpenMLDB provides an online execution engine that resolves performance bottlenecks caused by long window computations (via pre-aggregation) and multi-table window unions (via data self-adjusting). It also provides a high-performance offline execution engine with window parallel optimization and time-aware data skew resolving. Third, OpenMLDB features a compact data format and stream-focused indexing to maximize memory usage and accelerate data access. Evaluations in testing and real workloads reveal significant performance improvements and resource savings compared to the baseline systems. The open community of OpenMLDB now has over 150 contributors and gained 1.6k stars on GitHub.
Understanding and Mitigating Membership Inference Risks of Neural Ordinary Differential Equations
Jan 12, 2025



Neural ordinary differential equations (NODEs) are an emerging paradigm in scientific computing for modeling dynamical systems. By accurately learning underlying dynamics in data in the form of differential equations, NODEs have been widely adopted in various domains, such as healthcare, finance, computer vision, and language modeling. However, there remains a limited understanding of the privacy implications of these fundamentally different models, particularly with regard to their membership inference risks. In this work, we study the membership inference risks associated with NODEs. We first comprehensively evaluate NODEs against membership inference attacks. We show that NODEs are twice as resistant to these privacy attacks compared to conventional feedforward models such as ResNets. By analyzing the variance in membership risks across different NODE models, we identify the factors that contribute to their lower risks. We then demonstrate, both theoretically and empirically, that membership inference risks can be further mitigated by utilizing a stochastic variant of NODEs: Neural stochastic differential equations (NSDEs). We show that NSDEs are differentially-private (DP) learners that provide the same provable privacy guarantees as DP-SGD, the de-facto mechanism for training private models. NSDEs are also effective in mitigating existing membership inference attacks, demonstrating risks comparable to private models trained with DP-SGD while offering an improved privacy-utility trade-off. Moreover, we propose a drop-in-replacement strategy that efficiently integrates NSDEs into conventional feedforward models to enhance their privacy.
Personalized Language Model Learning on Text Data Without User Identifiers
Jan 10, 2025



In many practical natural language applications, user data are highly sensitive, requiring anonymous uploads of text data from mobile devices to the cloud without user identifiers. However, the absence of user identifiers restricts the ability of cloud-based language models to provide personalized services, which are essential for catering to diverse user needs. The trivial method of replacing an explicit user identifier with a static user embedding as model input still compromises data anonymization. In this work, we propose to let each mobile device maintain a user-specific distribution to dynamically generate user embeddings, thereby breaking the one-to-one mapping between an embedding and a specific user. We further theoretically demonstrate that to prevent the cloud from tracking users via uploaded embeddings, the local distributions of different users should either be derived from a linearly dependent space to avoid identifiability or be close to each other to prevent accurate attribution. Evaluation on both public and industrial datasets using different language models reveals a remarkable improvement in accuracy from incorporating anonymous user embeddings, while preserving real-time inference requirement.
Forward Once for All: Structural Parameterized Adaptation for Efficient Cloud-coordinated On-device Recommendation
Jan 06, 2025



In cloud-centric recommender system, regular data exchanges between user devices and cloud could potentially elevate bandwidth demands and privacy risks. On-device recommendation emerges as a viable solution by performing reranking locally to alleviate these concerns. Existing methods primarily focus on developing local adaptive parameters, while potentially neglecting the critical role of tailor-made model architecture. Insights from broader research domains suggest that varying data distributions might favor distinct architectures for better fitting. In addition, imposing a uniform model structure across heterogeneous devices may result in risking inefficacy on less capable devices or sub-optimal performance on those with sufficient capabilities. In response to these gaps, our paper introduces Forward-OFA, a novel approach for the dynamic construction of device-specific networks (both structure and parameters). Forward-OFA employs a structure controller to selectively determine whether each block needs to be assembled for a given device. However, during the training of the structure controller, these assembled heterogeneous structures are jointly optimized, where the co-adaption among blocks might encounter gradient conflicts. To mitigate this, Forward-OFA is designed to establish a structure-guided mapping of real-time behaviors to the parameters of assembled networks. Structure-related parameters and parallel components within the mapper prevent each part from receiving heterogeneous gradients from others, thus bypassing the gradient conflicts for coupled optimization. Besides, direct mapping enables Forward-OFA to achieve adaptation through only one forward pass, allowing for swift adaptation to changing interests and eliminating the requirement for on-device backpropagation. Experiments on real-world datasets demonstrate the effectiveness and efficiency of Forward-OFA.
AdaSkip: Adaptive Sublayer Skipping for Accelerating Long-Context LLM Inference
Jan 04, 2025



Long-context large language models (LLMs) inference is increasingly critical, motivating a number of studies devoted to alleviating the substantial storage and computational costs in such scenarios. Layer-wise skipping methods are promising optimizations but rarely explored in long-context inference. We observe that existing layer-wise skipping strategies have several limitations when applied in long-context inference, including the inability to adapt to model and context variability, disregard for sublayer significance, and inapplicability for the prefilling phase. This paper proposes \sysname, an adaptive sublayer skipping method specifically designed for long-context inference. \sysname adaptively identifies less important layers by leveraging on-the-fly similarity information, enables sublayer-wise skipping, and accelerates both the prefilling and decoding phases. The effectiveness of \sysname is demonstrated through extensive experiments on various long-context benchmarks and models, showcasing its superior inference performance over existing baselines.
Personalized LLM for Generating Customized Responses to the Same Query from Different Users
Dec 16, 2024



Existing work on large language model (LLM) personalization assigned different responding roles to LLM, but overlooked the diversity of questioners. In this work, we propose a new form of questioner-aware LLM personalization, generating different responses even for the same query from different questioners. We design a dual-tower model architecture with a cross-questioner general encoder and a questioner-specific encoder. We further apply contrastive learning with multi-view augmentation, pulling close the dialogue representations of the same questioner, while pulling apart those of different questioners. To mitigate the impact of question diversity on questioner-contrastive learning, we cluster the dialogues based on question similarity and restrict the scope of contrastive learning within each cluster. We also build a multi-questioner dataset from English and Chinese scripts and WeChat records, called MQDialog, containing 173 questioners and 12 responders. Extensive evaluation with different metrics shows a significant improvement in the quality of personalized response generation.
How Does the Smoothness Approximation Method Facilitate Generalization for Federated Adversarial Learning?
Dec 11, 2024



Federated Adversarial Learning (FAL) is a robust framework for resisting adversarial attacks on federated learning. Although some FAL studies have developed efficient algorithms, they primarily focus on convergence performance and overlook generalization. Generalization is crucial for evaluating algorithm performance on unseen data. However, generalization analysis is more challenging due to non-smooth adversarial loss functions. A common approach to addressing this issue is to leverage smoothness approximation. In this paper, we develop algorithm stability measures to evaluate the generalization performance of two popular FAL algorithms: \textit{Vanilla FAL (VFAL)} and {\it Slack FAL (SFAL)}, using three different smooth approximation methods: 1) \textit{Surrogate Smoothness Approximation (SSA)}, (2) \textit{Randomized Smoothness Approximation (RSA)}, and (3) \textit{Over-Parameterized Smoothness Approximation (OPSA)}. Based on our in-depth analysis, we answer the question of how to properly set the smoothness approximation method to mitigate generalization error in FAL. Moreover, we identify RSA as the most effective method for reducing generalization error. In highly data-heterogeneous scenarios, we also recommend employing SFAL to mitigate the deterioration of generalization performance caused by heterogeneity. Based on our theoretical results, we provide insights to help develop more efficient FAL algorithms, such as designing new metrics and dynamic aggregation rules to mitigate heterogeneity.